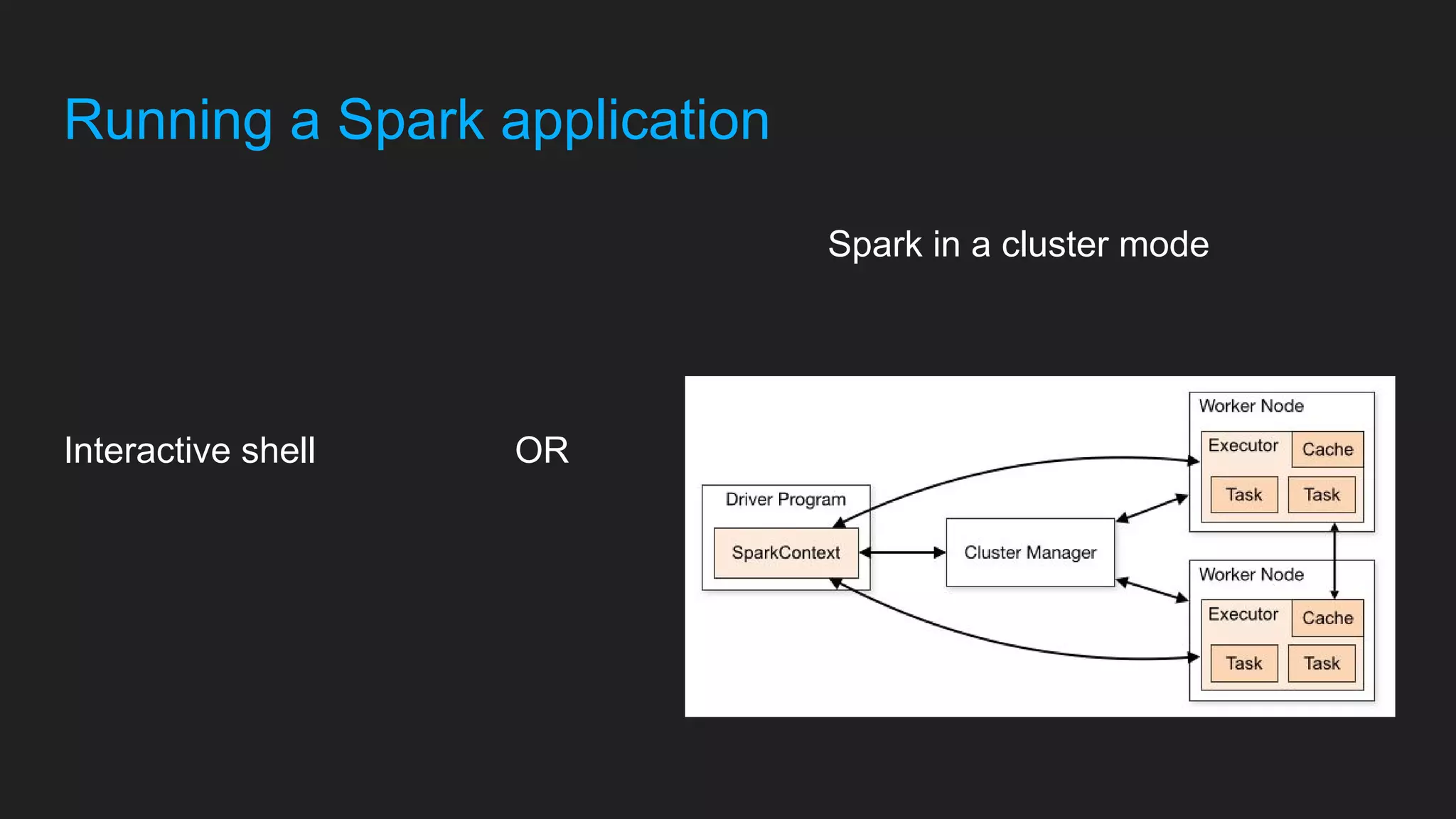
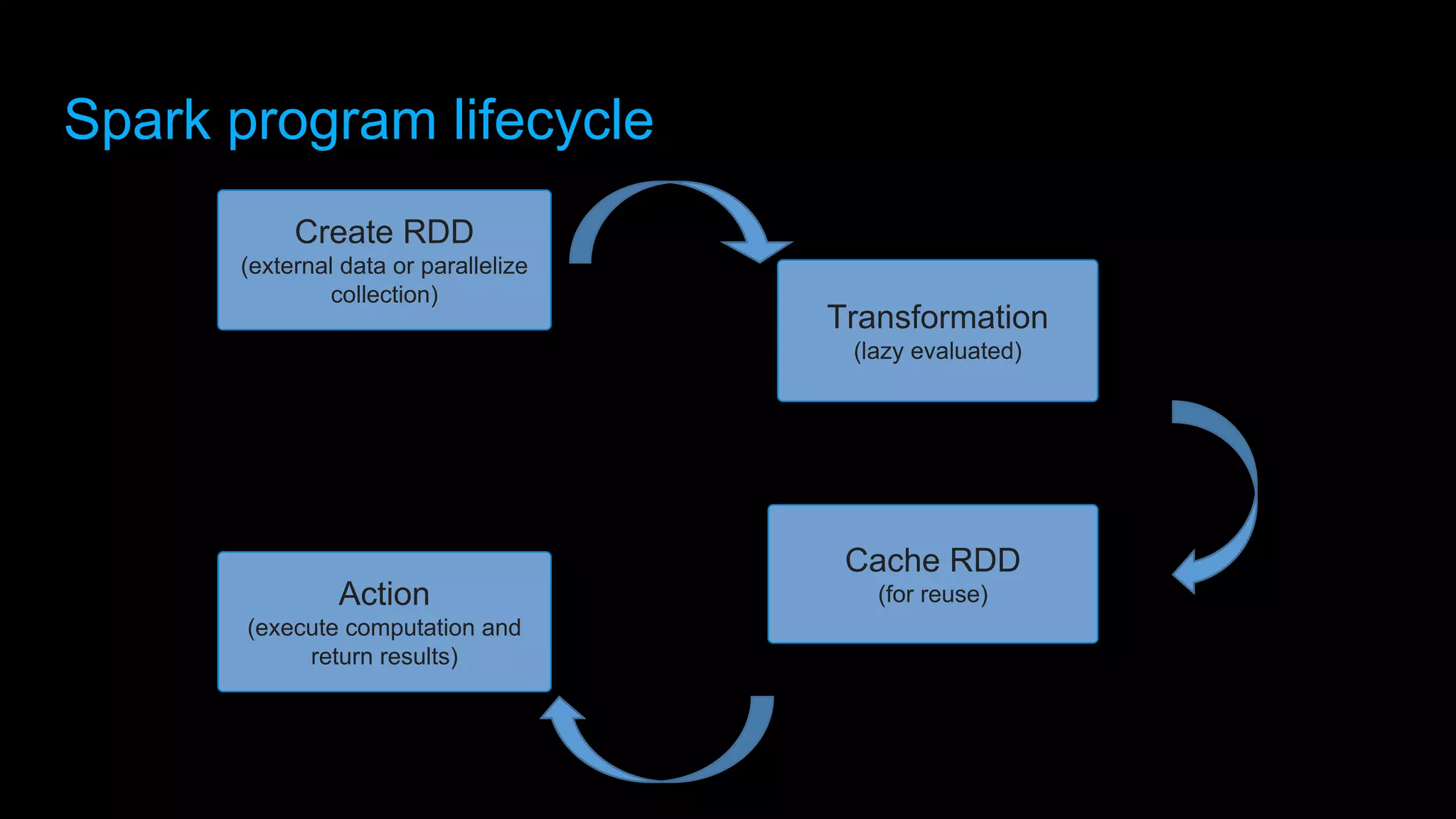
Download to read offline




![Spark Datasets
Spark Dataset is a strongly-typed, immutable collection of objects that are mapped to a
relational schema. *
Encoder is responsible for converting between JVM objects and tabular representation.
API Preview in Spark 1.6
Main goal was to bring the object oriented programming style and type-safety, while
preserving performance.
Java and Scala APIs so far.
val lines = sqlContext.read.text("pathToMyFile").as[String]
*qoute: https://databricks.com/blog/2016/01/04/introducing-spark-datasets.html](https://image.slidesharecdn.com/letsstartwithspark-161031142154/75/Let-s-start-with-Spark-6-2048.jpg)





Spark is a fast, general processing engine that improves efficiency through in-memory computing and computation graphs. It offers APIs in Scala, Java, Python and R. Spark applications use Resilient Distributed Datasets (RDDs) which are immutable, partitioned objects that support fault tolerance. Spark also supports Spark SQL for structured data querying and Spark MLlib for machine learning.















































![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)




