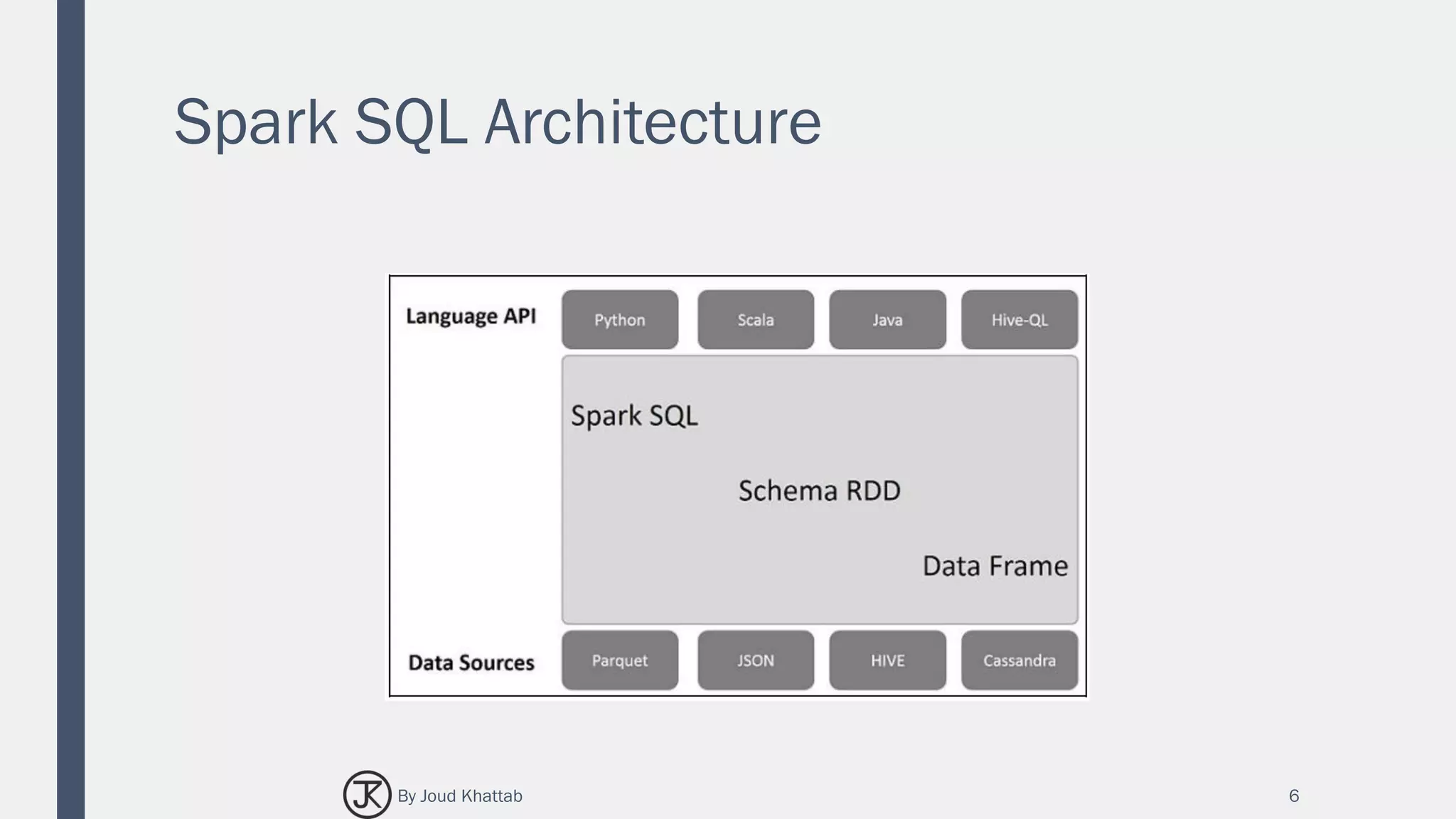
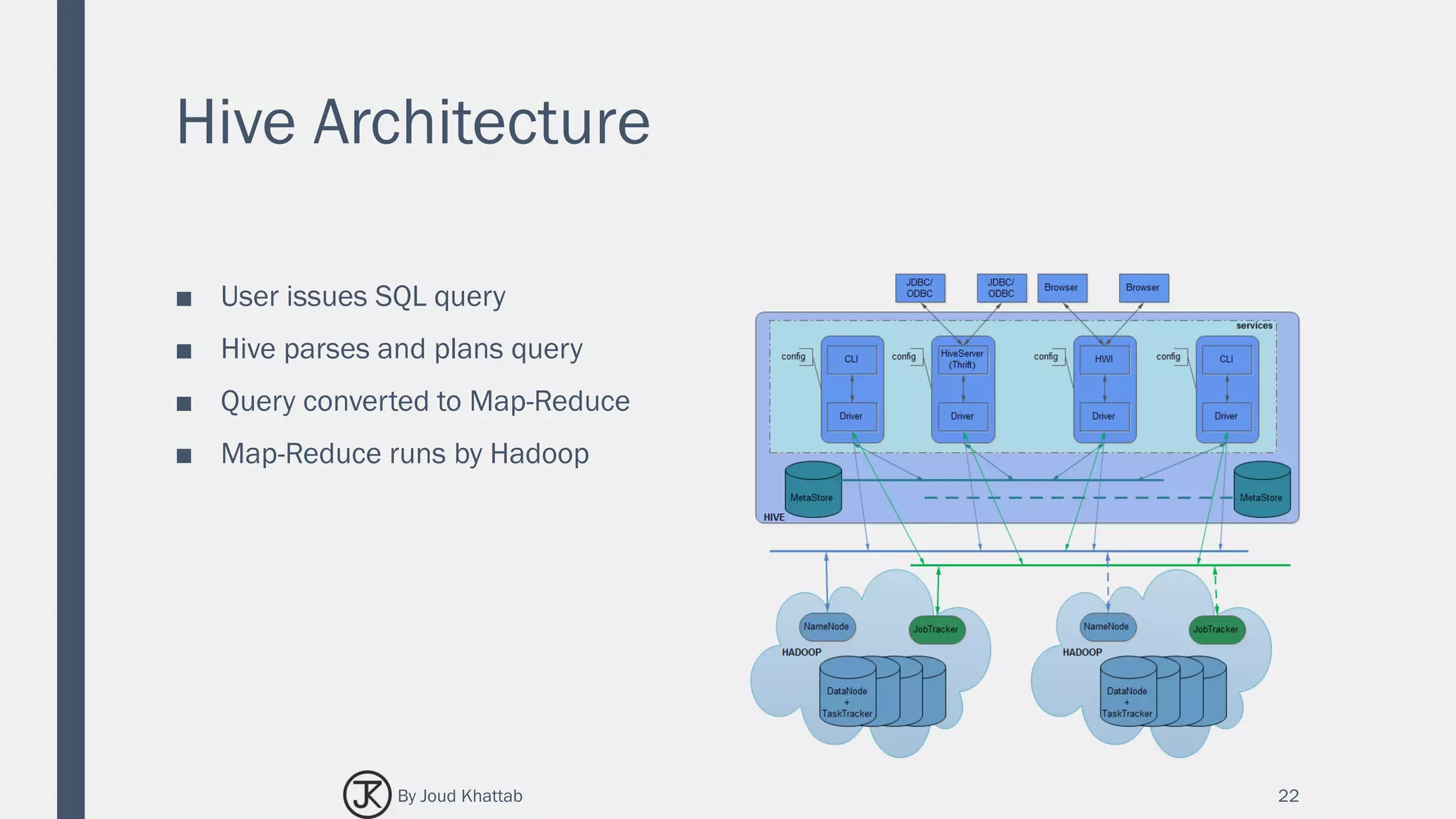
The document summarizes Spark SQL, which is a Spark module for structured data processing. It introduces key concepts like RDDs, DataFrames, and interacting with data sources. The architecture of Spark SQL is explained, including how it works with different languages and data sources through its schema RDD abstraction. Features of Spark SQL are covered such as its integration with Spark programs, unified data access, compatibility with Hive, and standard connectivity.





























![Write Less Code:
Compute an Average
32
private IntWritable one = new IntWritable(1)
private IntWritable output = new IntWritable()
proctected void map( LongWritable key,
Text value, Context context) {
String[] fields = value.split("t")
output.set(Integer.parseInt(fields[1]))
context.write(one, output)
}
IntWritable one = new IntWritable(1) DoubleWritable average
= new DoubleWritable()
protected void reduce( IntWritable key,
Iterable<IntWritable> values, Context
context) {
int sum = 0 int count = 0
for(IntWritable value : values) { sum +=
value.get()
count++
}
average.set(sum / (double) count)
context.Write(key, average)
data = sc.textFile(...).split("t")
data.map(lambda x: (x[0], [x.[1], 1]))
.reduceByKey(lambda x, y: [x[0] + y[0], x[1] + y[1]])
.map(lambda x: [x[0], x[1][0] / x[1][1]])
.collect()
By Joud Khattab](https://image.slidesharecdn.com/sparksql-170702093401/75/Spark-SQL-32-2048.jpg)
![Write Less Code:
Compute an Average
33
Using RDDs
data = sc.textFile(...).split("t")
data.map(lambda x: (x[0], [int(x[1]), 1]))
.reduceByKey(lambda x, y: [x[0] + y[0], x[1] + y[1]])
.map(lambda x: [x[0], x[1][0] / x[1][1]])
.collect()
Using DataFrames
sqlCtx.table("people")
.groupBy("name")
.agg("name", avg("age"))
.collect()
Using SQL
SELECT name, avg(age)
FROM people
GROUP BY name
By Joud Khattab](https://image.slidesharecdn.com/sparksql-170702093401/75/Spark-SQL-33-2048.jpg)




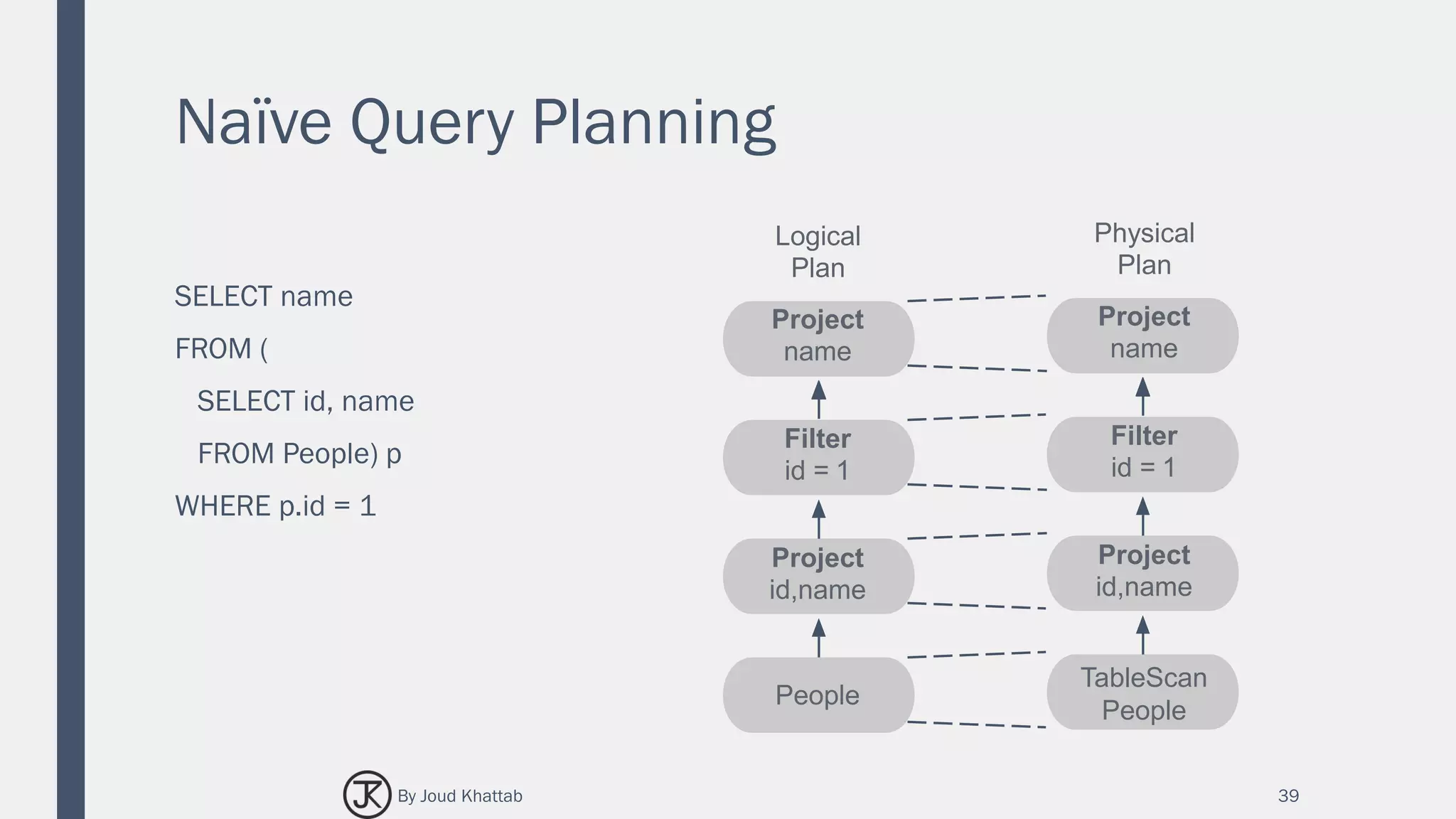
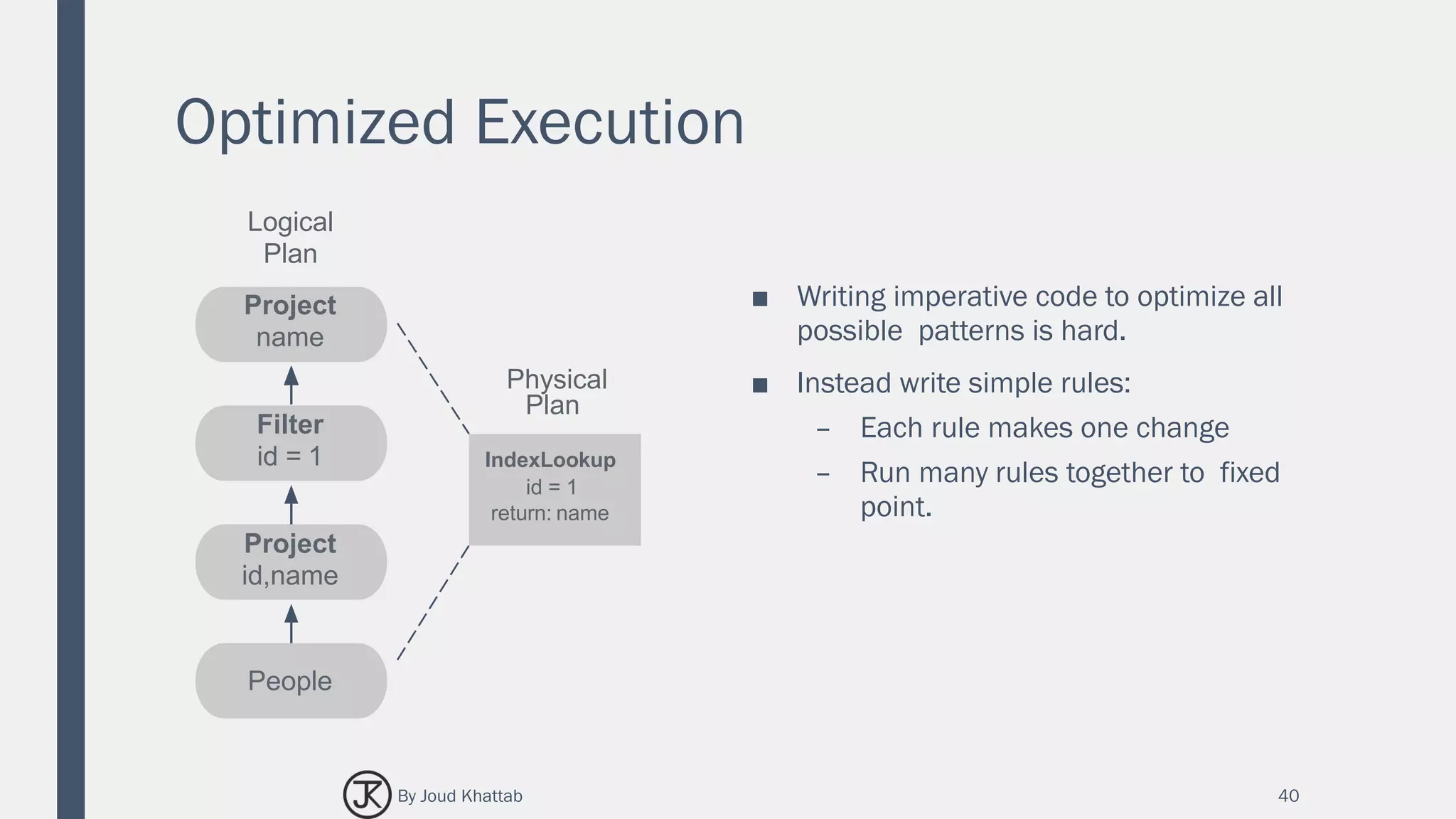
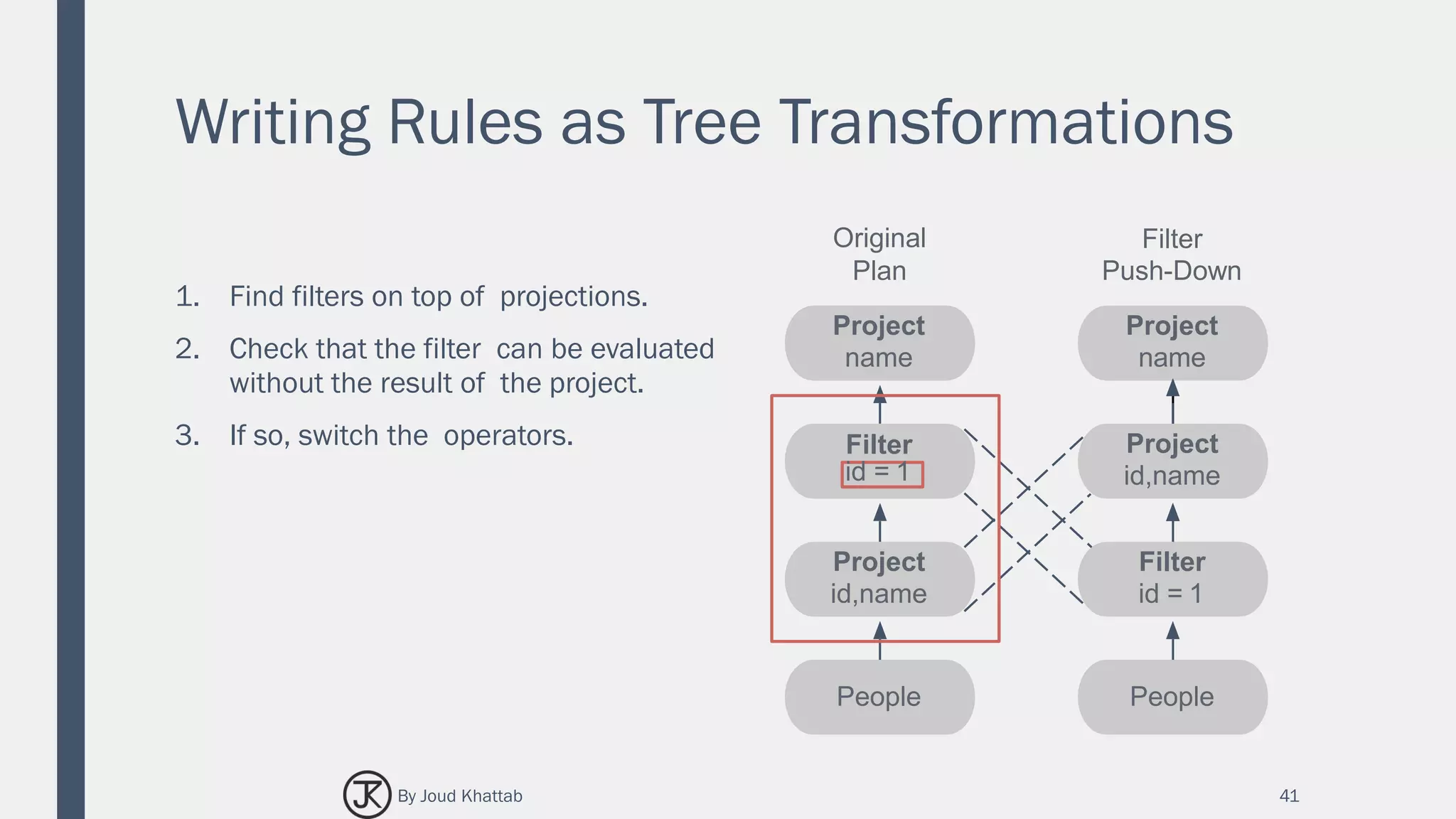
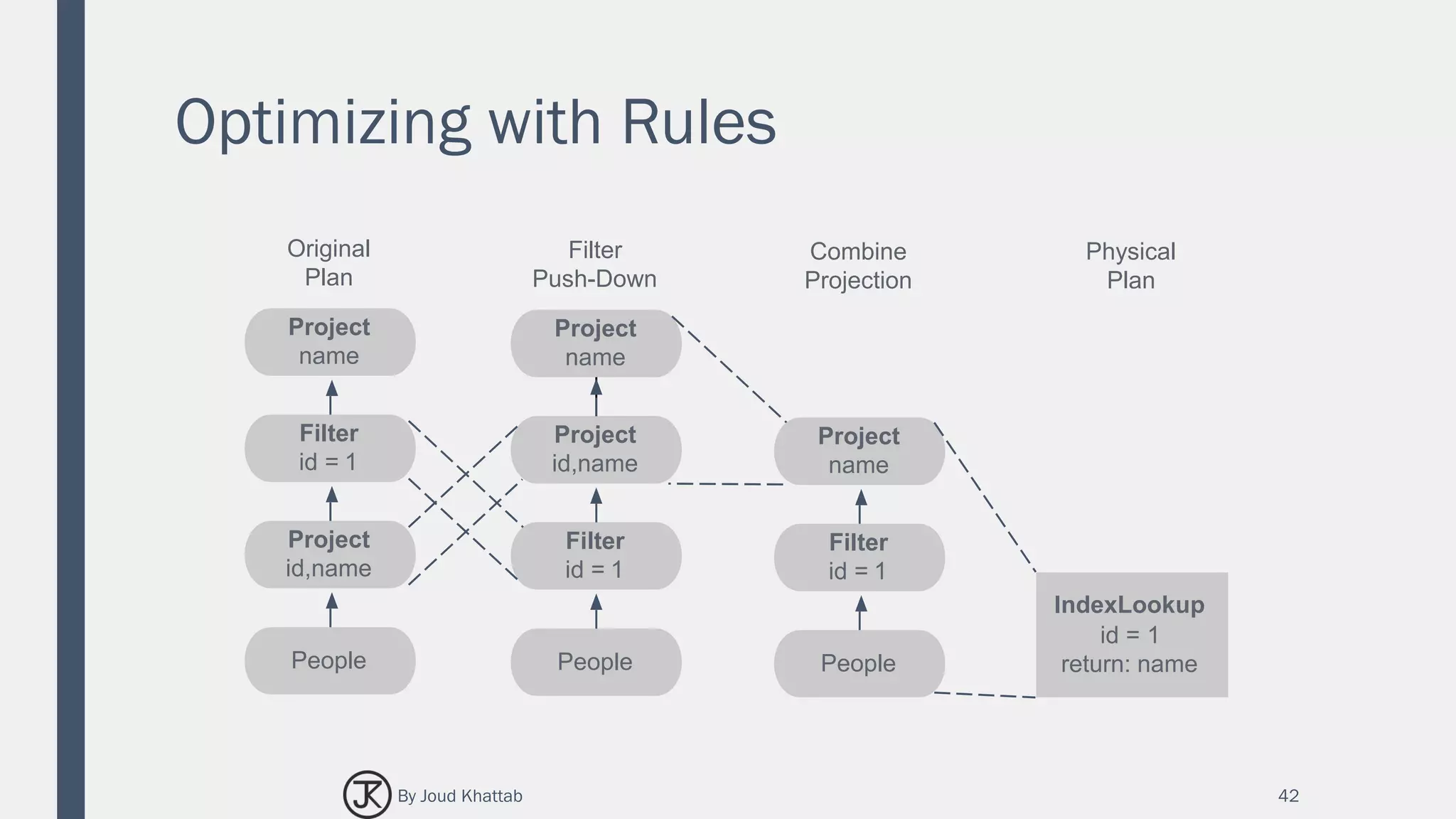





![Flights Data
library(sparklyr)
library(dplyr)
library(nycflights13)
library(ggplot2)
sc <- spark_connect(master="local")
flights <- copy_to(sc, flights, "flights")
airlines <- copy_to(sc, airlines, "airlines")
src_tbls(sc)
[1] "airlines" "flights"
48By Joud Khattab](https://image.slidesharecdn.com/sparksql-170702093401/75/Spark-SQL-48-2048.jpg)

![dplyr Verbs:
select
select(flights, year:day, arr_delay,
dep_delay)
# Source: lazy query [?? x 5]
# Database: spark_connection
year month day arr_delay dep_delay
<int> <int> <int> <dbl> <dbl>
1 2013 1 1 11 2
2 2013 1 1 20 4
3 2013 1 1 33 2
4 2013 1 1 -18 -1
5 2013 1 1 -25 -6
6 2013 1 1 12 -4
7 2013 1 1 19 -5
8 2013 1 1 -14 -3
9 2013 1 1 -8 -3
10 2013 1 1 8 -2
# ... with 3.368e+05 more rows
50By Joud Khattab](https://image.slidesharecdn.com/sparksql-170702093401/75/Spark-SQL-50-2048.jpg)
![dplyr Verbs:
filter
filter(flights, dep_delay > 1000) # Source: lazy query [?? x 19]
# Database: spark_connection
year month day dep_time sched_dep_time dep_delay
<int> <int> <int> <int> <int> <dbl>
1 2013 1 9 641 900 1301
2 2013 1 10 1121 1635 1126
3 2013 6 15 1432 1935 1137
4 2013 7 22 845 1600 1005
5 2013 9 20 1139 1845 1014
# ... with 13 more variables: arr_time <int>, sched_arr_time
# <int>, arr_delay <dbl>, carrier <chr>, flight <int>, talinum
# <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance
# <dbl>, hour <dbl>, minute <dbl>, time_hour <dbl>
51By Joud Khattab](https://image.slidesharecdn.com/sparksql-170702093401/75/Spark-SQL-51-2048.jpg)
![dplyr Verbs:
arrange
arrange(flights, desc(dep_delay)) # Source: table<flights> [?? x 19]
# Database: spark_connection
# Ordered by: desc(dep_delay)
year month day dep_time sched_dep_time dep_delay
<int> <int> <int> <int> <int> <dbl>
1 2013 1 9 641 900 1301
2 2013 6 15 1432 1935 1137
3 2013 1 10 1121 1635 1126
4 2013 9 20 1139 1845 1014
5 2013 7 22 845 1600 1005
6 2013 4 10 1100 1900 960
7 2013 3 17 2321 810 911
8 2013 6 27 959 1900 899
9 2013 7 22 2257 759 898
10 2013 12 5 756 1700 896
# ... With 3.368e+05 more rows, and 13 more variables:
# arr_time <int>, sched_arr_time <int>, arr_delay <dbl>,
# carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest
# <chr>, air_time <dbl>, distance <dbl>, hour <dbl>, minute
# <dbl>, time_hour <dbl>
52By Joud Khattab](https://image.slidesharecdn.com/sparksql-170702093401/75/Spark-SQL-52-2048.jpg)
![dplyr Verbs:
summarise
summarise(flights, mean_dep_delay =
mean(dep_delay))
# Source: lazy query [?? x 1]
# Database: spark_connection
mean_dep_delay
<dbl>
1 12.63907
53By Joud Khattab](https://image.slidesharecdn.com/sparksql-170702093401/75/Spark-SQL-53-2048.jpg)
![dplyr Verbs:
mutate
mutate(flights, speed = distance /
air_time * 60)
Source: query [3.368e+05 x 4]
Database: spark connection master=local[4]
app=sparklyr local=TRUE
# A tibble: 3.368e+05 x 4
year month day speed
<int> <int> <int> <dbl>
1 2013 1 1 370.0441
2 2013 1 1 374.2731
3 2013 1 1 408.3750
4 2013 1 1 516.7213
5 2013 1 1 394.1379
6 2013 1 1 287.6000
7 2013 1 1 404.4304
8 2013 1 1 259.2453
9 2013 1 1 404.5714
10 2013 1 1 318.6957
# ... with 3.368e+05 more rows
54By Joud Khattab](https://image.slidesharecdn.com/sparksql-170702093401/75/Spark-SQL-54-2048.jpg)

![Laziness
■ This sequence of operations never
actually touches the database.
■ It’s not until you ask for the data (e.g.
by printing c4) that dplyr requests the
results from the database.
# Source: lazy query [?? x 20]
# Database: spark_connection
year month day carrier dep_delay air_time distance air_time_hours
<int> <int> <int> <chr> <dbl> <dbl> <dbl> <dbl>
1 2013 5 17 AA -2 294 2248 4.900000
2 2013 5 17 AA -1 146 1096 2.433333
3 2013 5 17 AA -2 185 1372 3.083333
4 2013 5 17 AA -9 186 1389 3.100000
5 2013 5 17 AA 2 147 1096 2.450000
6 2013 5 17 AA -4 114 733 1.900000
7 2013 5 17 AA -7 117 733 1.950000
8 2013 5 17 AA -7 142 1089 2.366667
9 2013 5 17 AA -6 148 1089 2.466667
10 2013 5 17 AA -7 137 944 2.283333
# ... with more rows
56By Joud Khattab](https://image.slidesharecdn.com/sparksql-170702093401/75/Spark-SQL-56-2048.jpg)

![Grouping
c4 %>%
group_by(carrier) %>%
summarize(count = n(), mean_dep_delay =
mean(dep_delay))
Source: query [?? x 3]
Database: spark connection master=local
app=sparklyr local=TRUE
# S3: tbl_spark
carrier count mean_dep_delay
<chr> <dbl> <dbl>
1 AA 94 1.468085
2 UA 172 9.633721
3 WN 34 7.970588
4 DL 136 6.235294
58By Joud Khattab](https://image.slidesharecdn.com/sparksql-170702093401/75/Spark-SQL-58-2048.jpg)


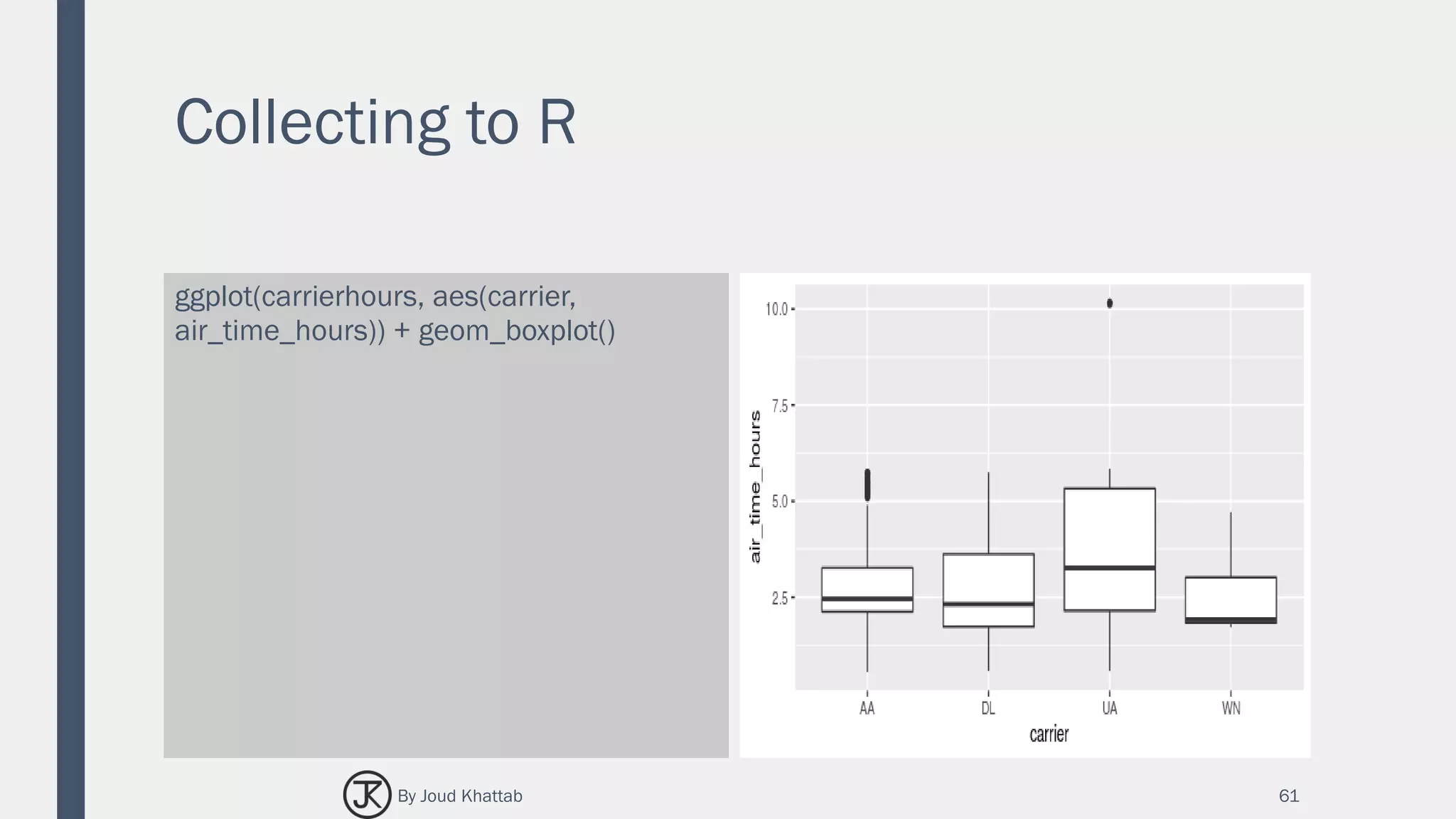


![Window Functions
ranked # Source: lazy query [?? x 20]
# Database: spark_connection
year month day dep_delay rank
<int> <int> <int> <dbl> <int>
1 2013 1 5 327 1
2 2013 1 5 257 2
3 2013 1 5 225 3
4 2013 1 5 128 4
5 2013 1 5 127 5
6 2013 1 5 117 6
7 2013 1 5 111 7
8 2013 1 5 108 8
9 2013 1 5 105 9
10 2013 1 5 101 10
# ... with more rows
66By Joud Khattab](https://image.slidesharecdn.com/sparksql-170702093401/75/Spark-SQL-64-2048.jpg)

![Performing Joins
The following statements are equivalent:
flights %>% left_join(airlines)
flights %>% left_join(airlines, by =
"carrier")
# Source: lazy query [?? x 20]
# Database: spark_connection
year month day dep_time sched_dep_time dep_delay arr_time
<int> <int> <int> <int> <int> <dbl> <int>
1 2013 1 1 517 515 2 830
2 2013 1 1 533 529 4 850
3 2013 1 1 542 540 2 923
4 2013 1 1 544 545 -1 1004
5 2013 1 1 554 600 -6 812
6 2013 1 1 554 558 -4 740
7 2013 1 1 555 600 -5 913
8 2013 1 1 557 600 -3 709
9 2013 1 1 557 600 -3 838
10 2013 1 1 558 600 -2 753
# ... with more rows
68By Joud Khattab](https://image.slidesharecdn.com/sparksql-170702093401/75/Spark-SQL-66-2048.jpg)