Downloaded 4,713 times




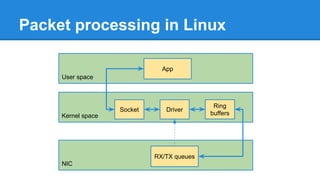

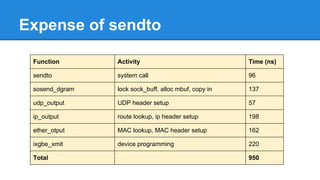
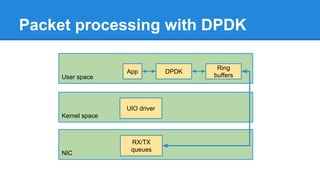
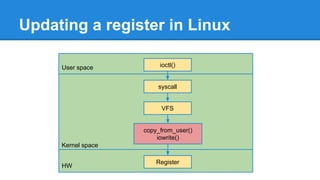
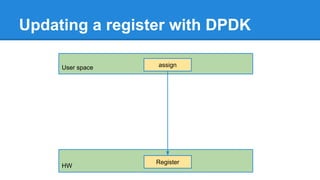

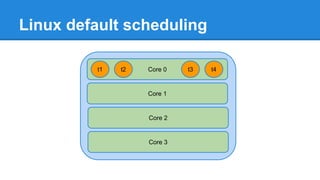

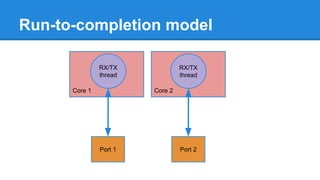
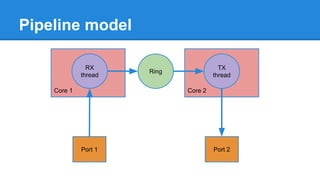
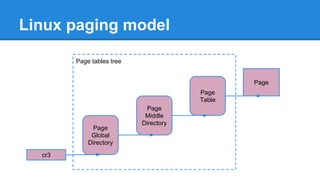
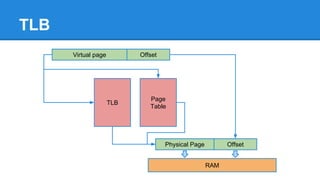



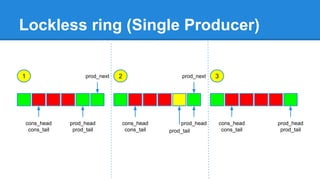
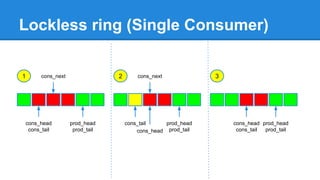
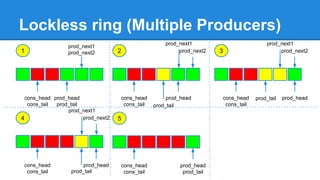
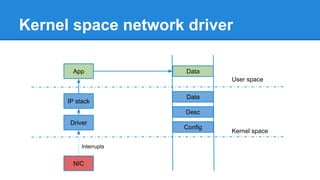

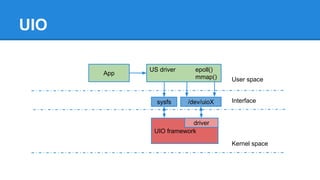
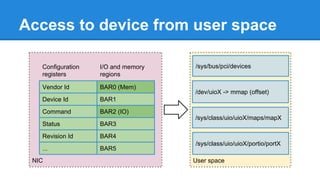
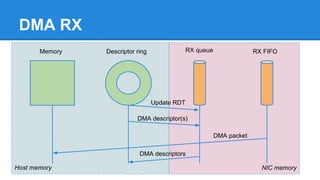
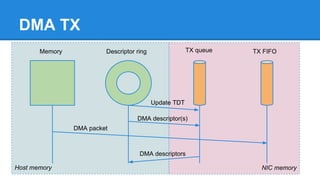
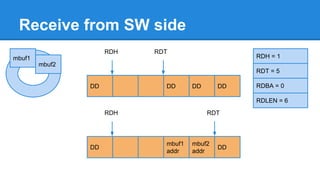
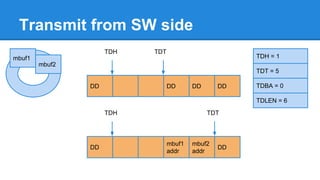
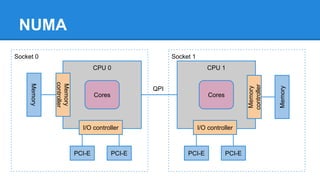
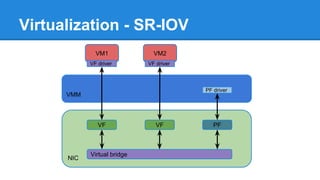
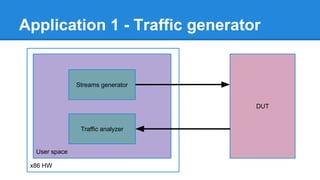
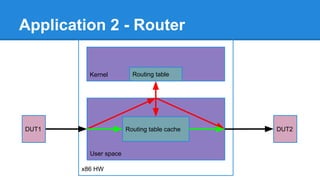
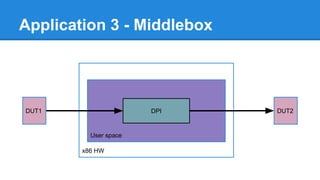

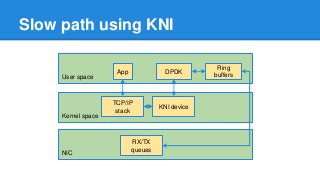
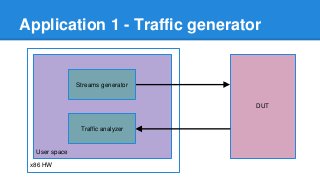
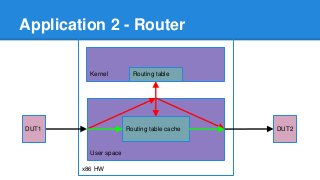
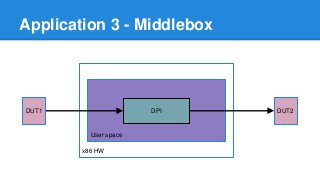



1. DPDK achieves high throughput packet processing on commodity hardware by reducing kernel overhead through techniques like polling, huge pages, and userspace drivers. 2. In Linux, packet processing involves expensive operations like system calls, interrupts, and data copying between kernel and userspace. DPDK avoids these by doing all packet processing in userspace. 3. DPDK uses techniques like isolating cores for packet I/O threads, lockless ring buffers, and NUMA awareness to further optimize performance. It can achieve throughput of over 14 million packets per second on 10GbE interfaces.























































![CETH for XDP [Linux Meetup Santa Clara | July 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/ceth5overview1-160801192921-thumbnail.jpg?width=640&height=640&fit=bounds)

































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)



