Download to read offline



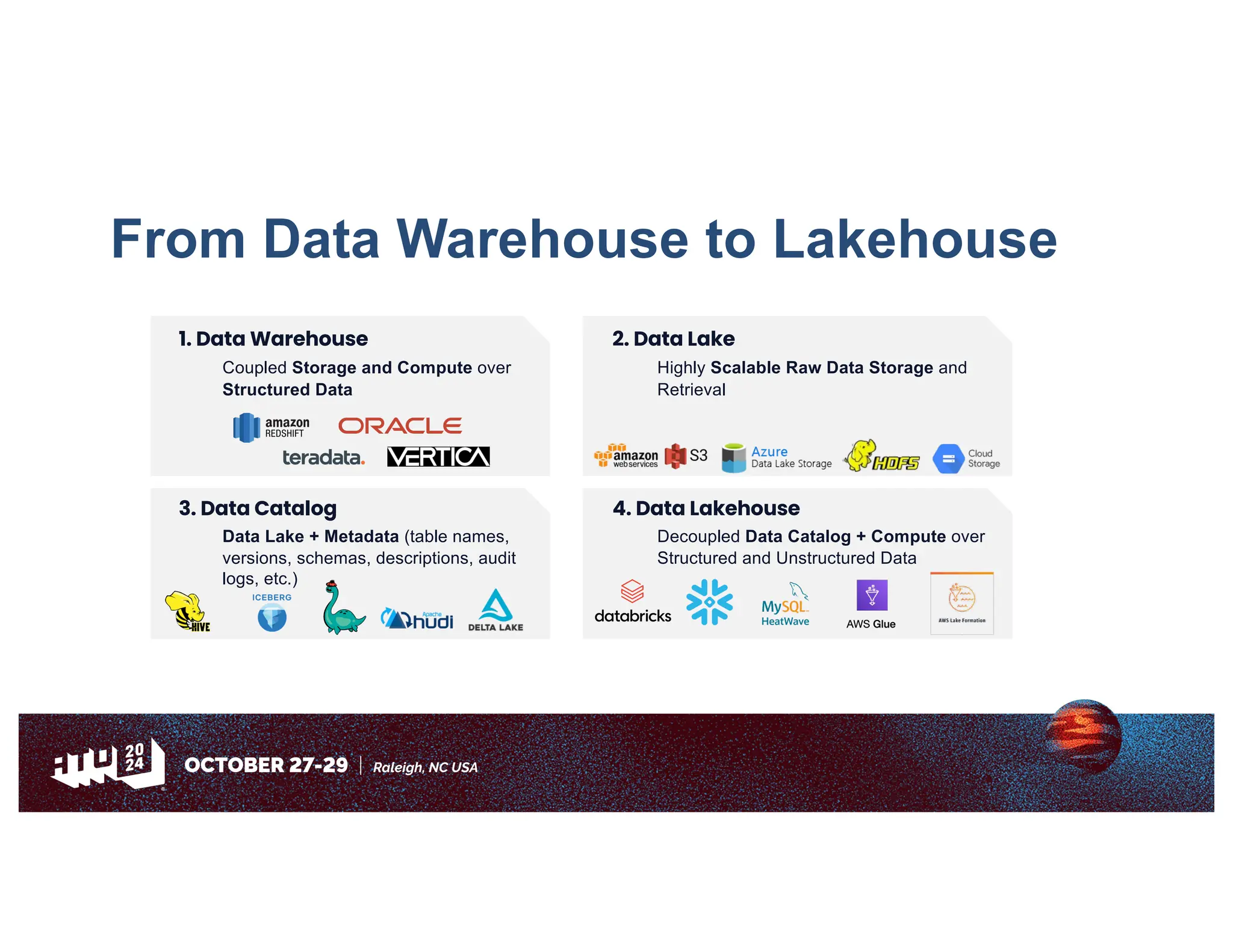
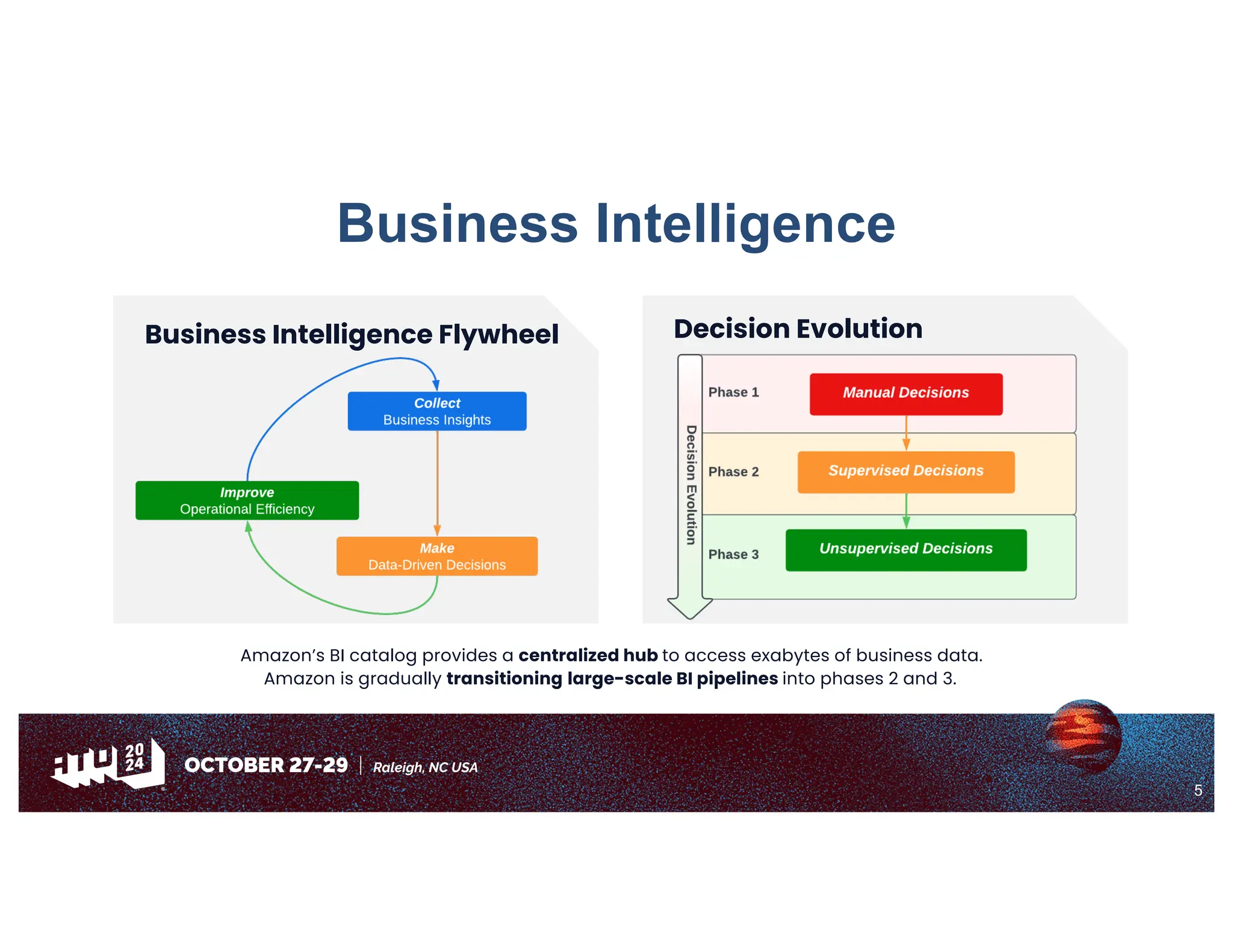

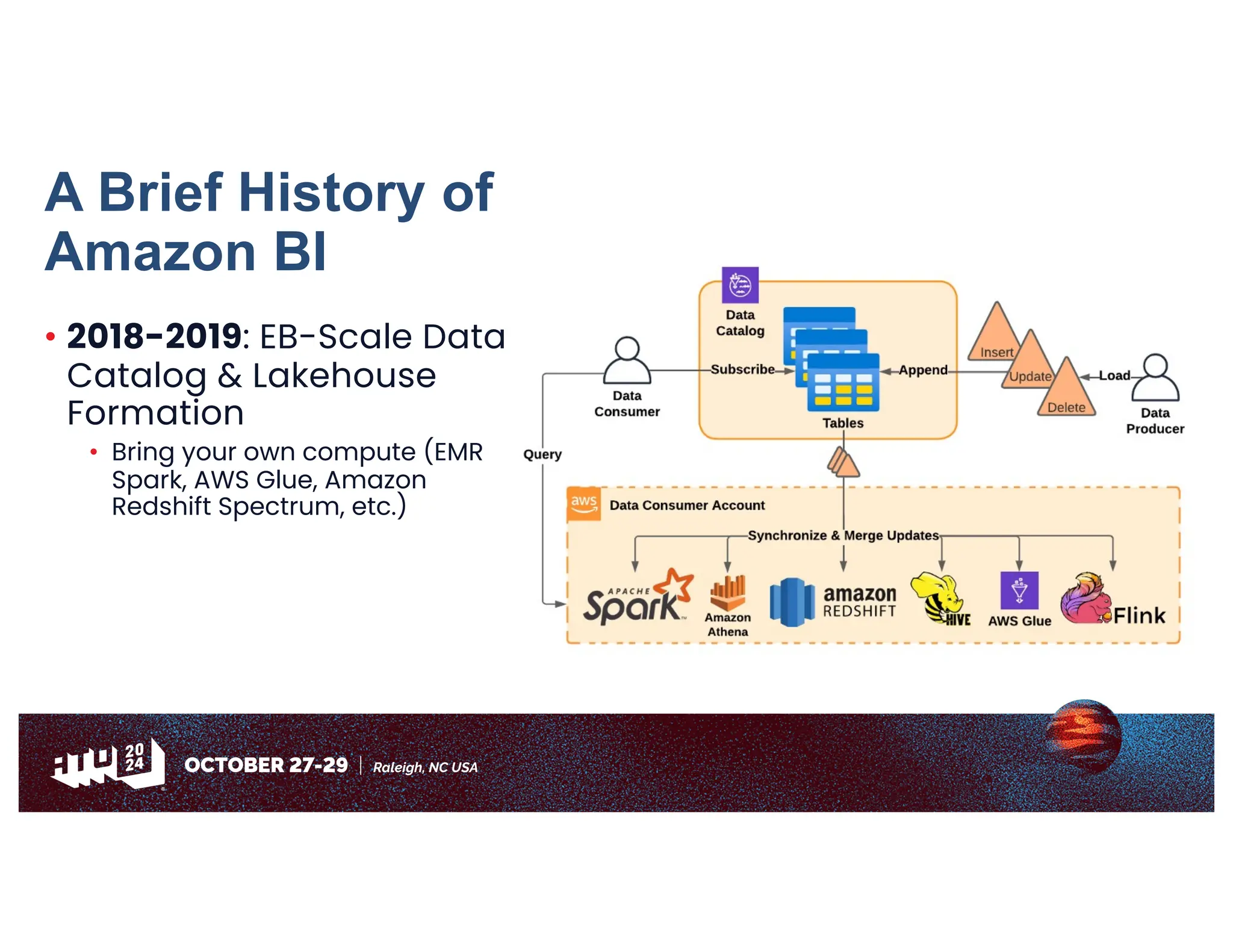
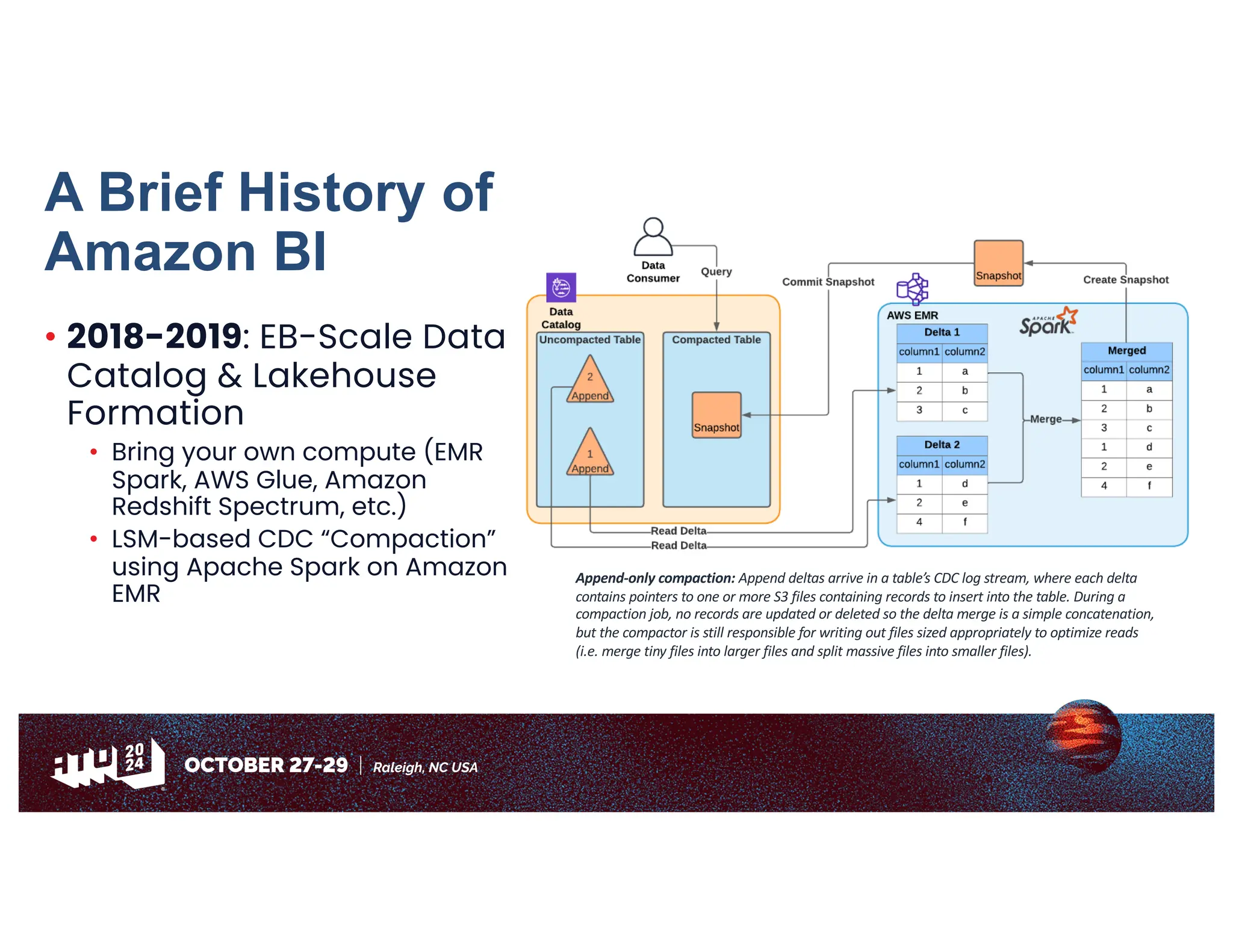
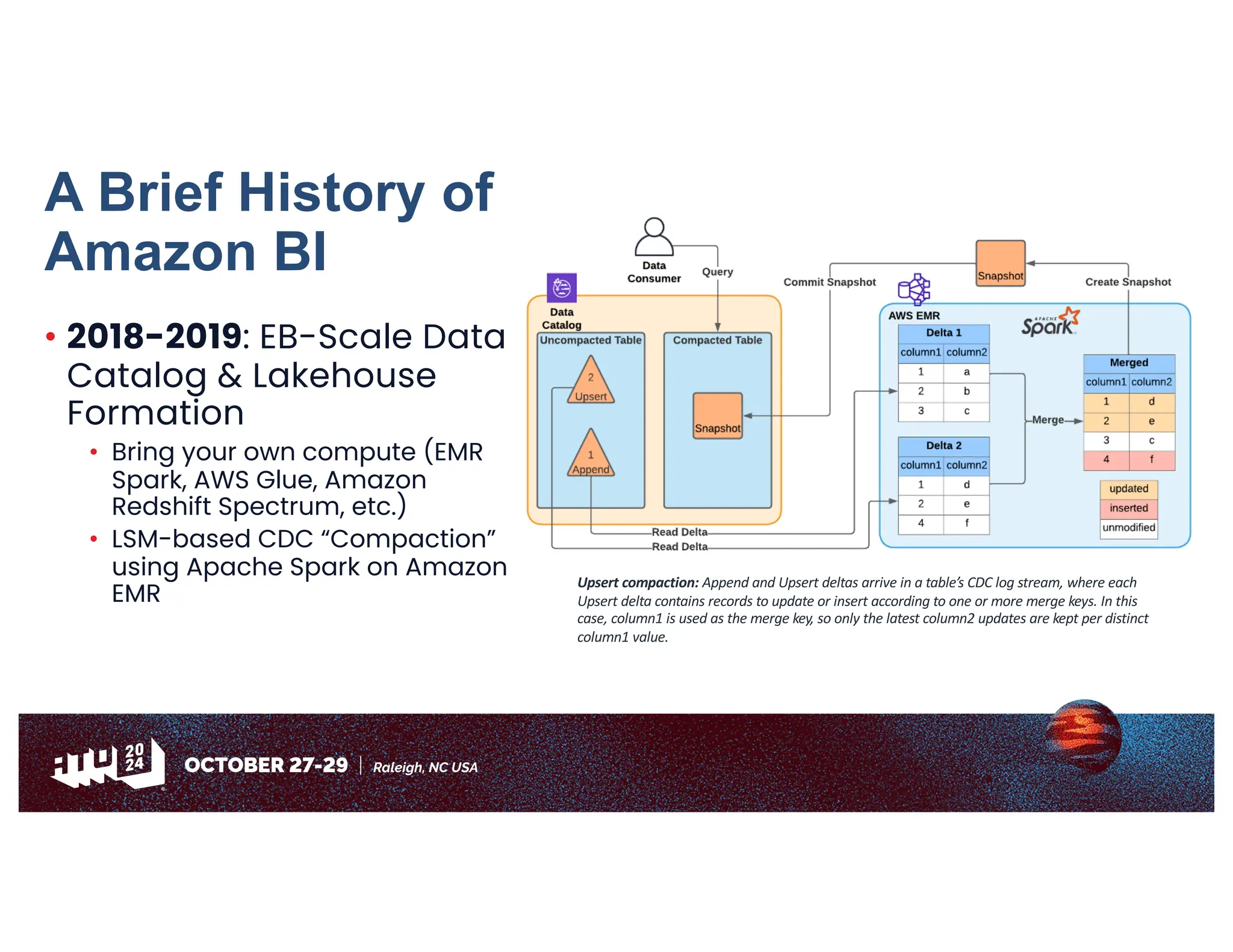
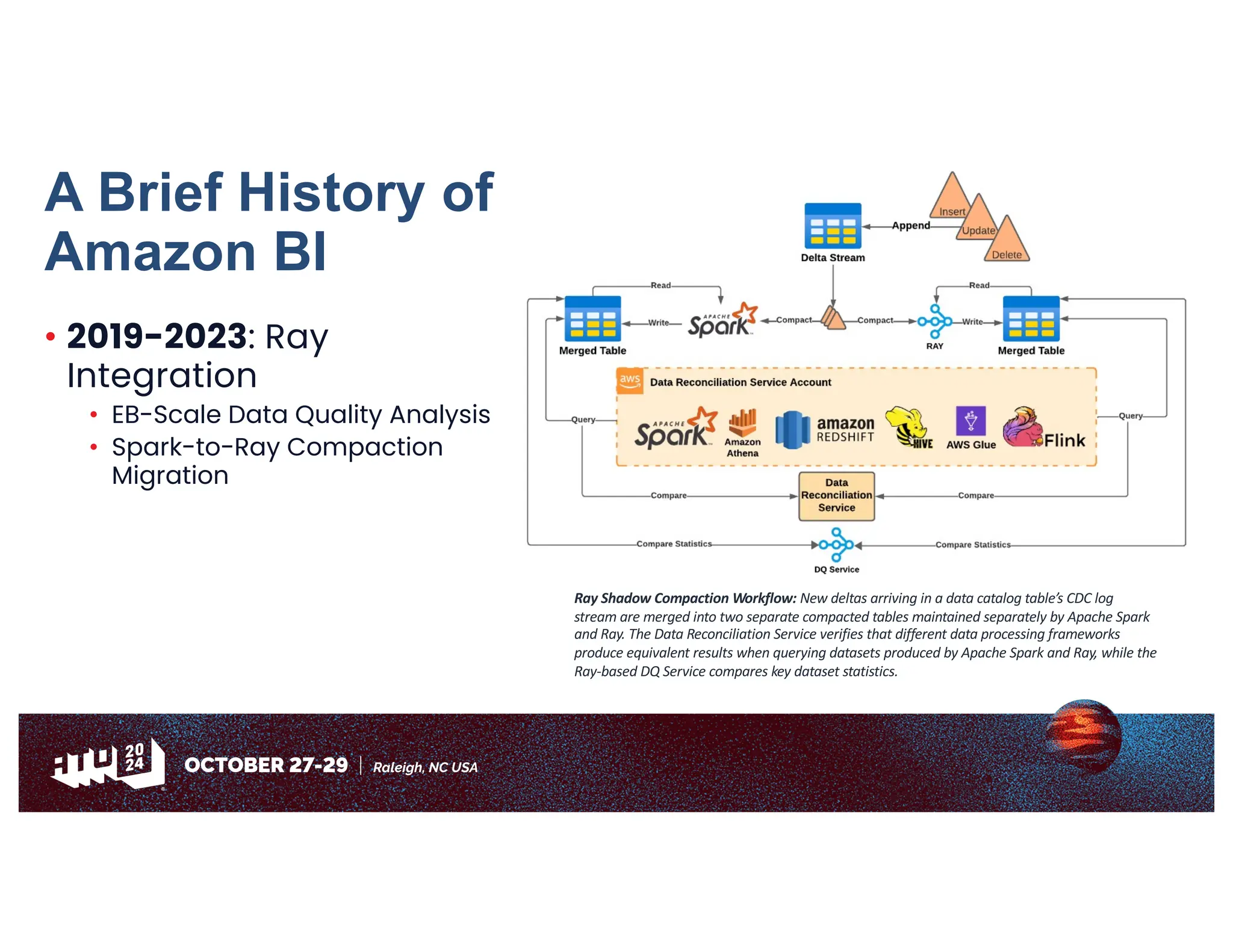






















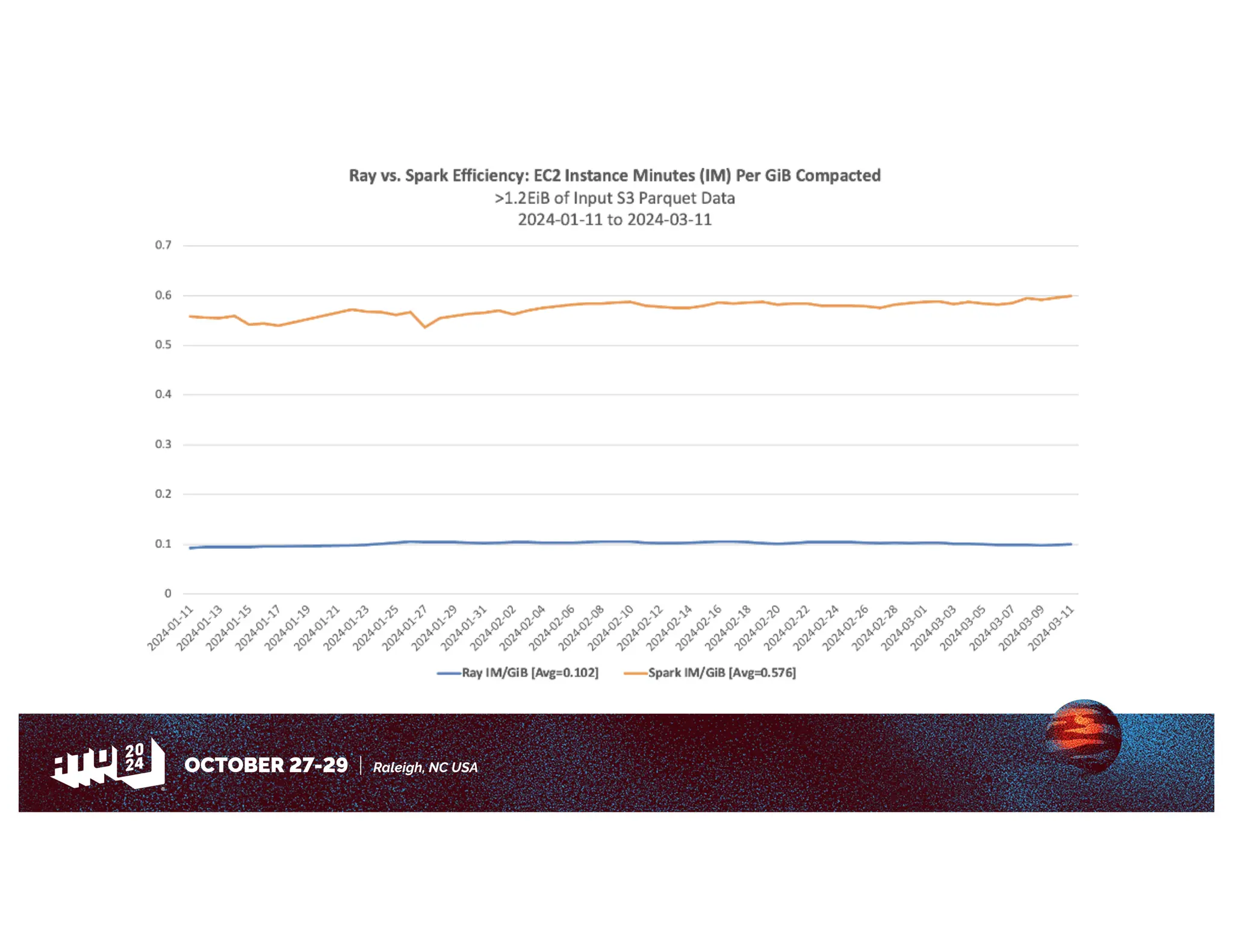
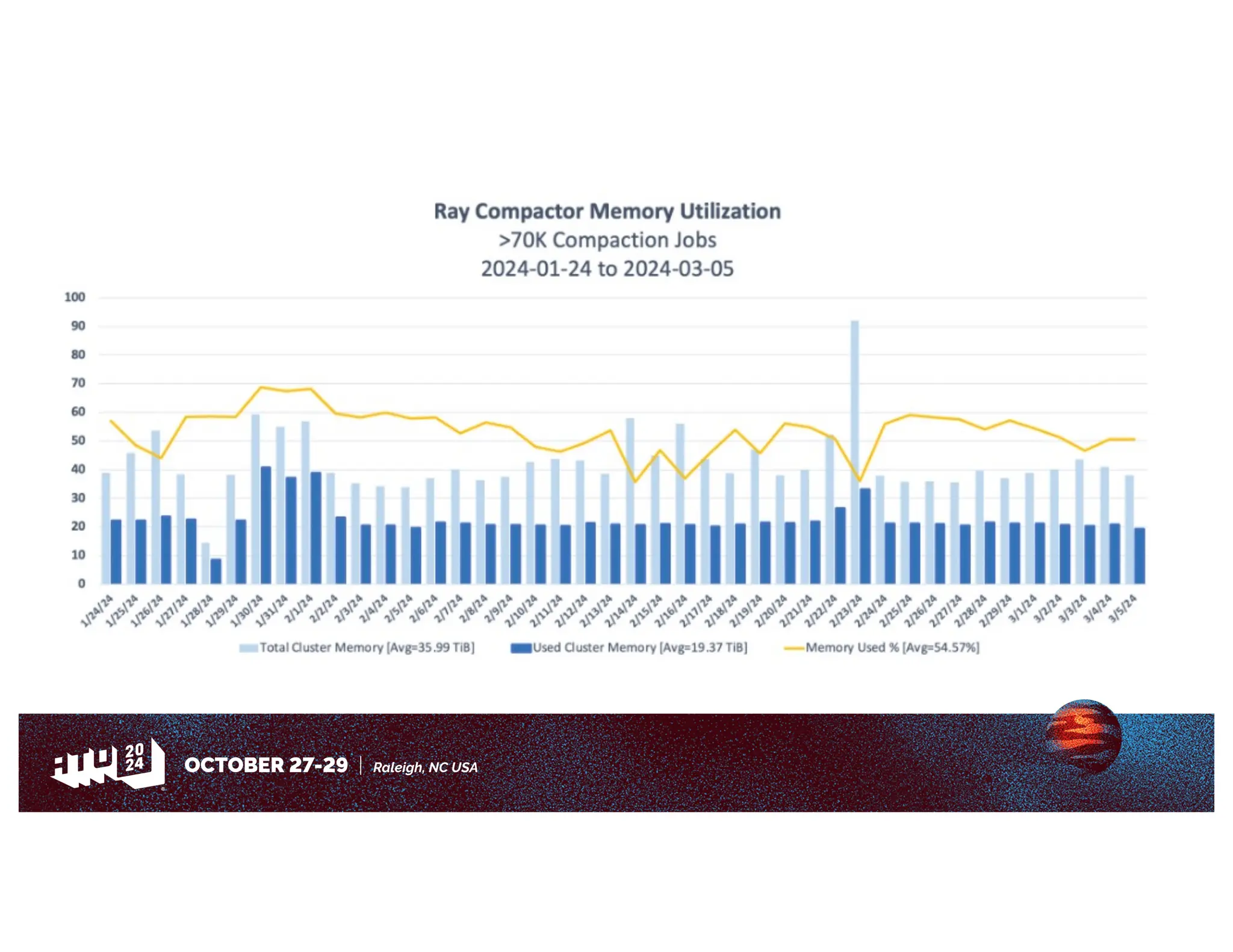
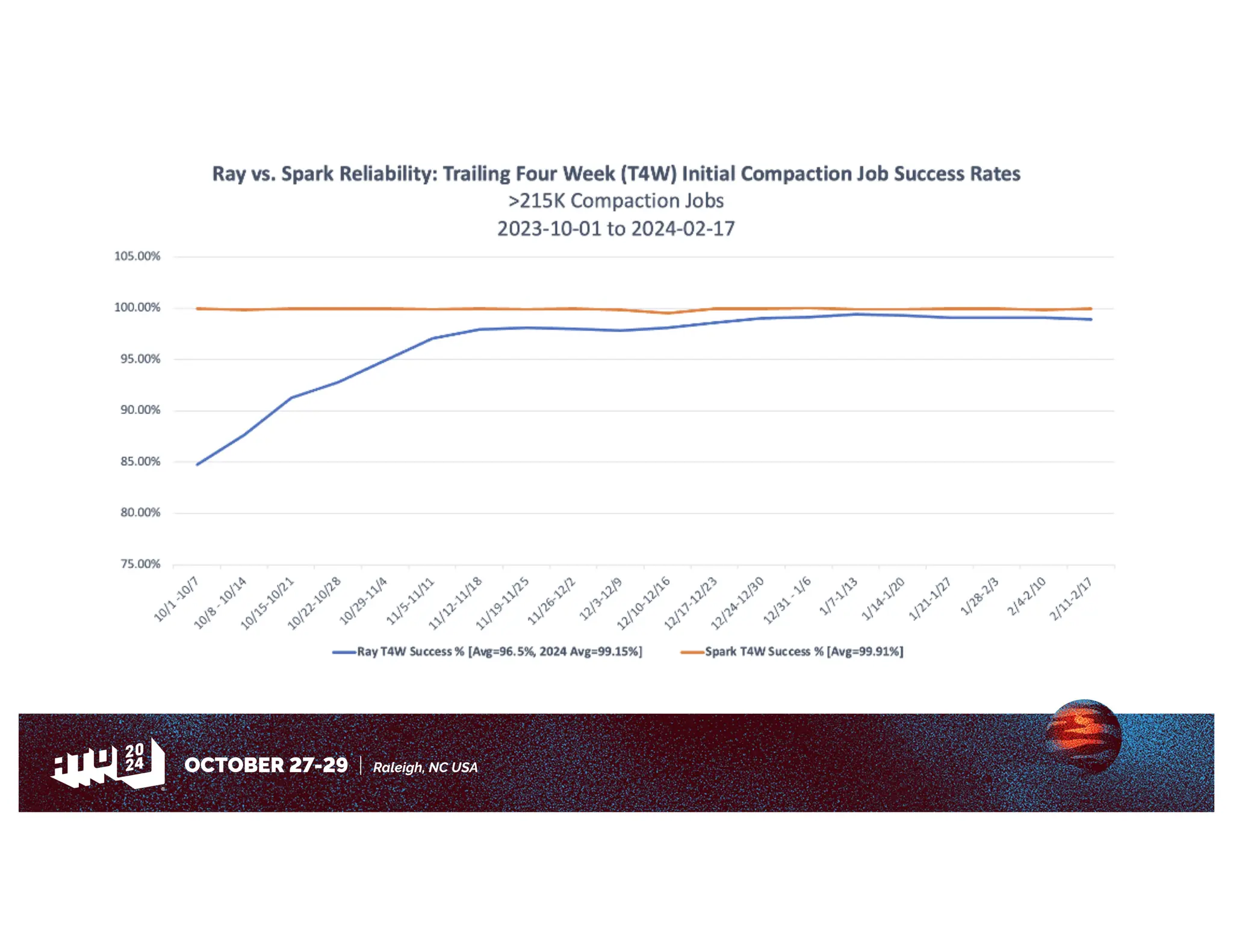
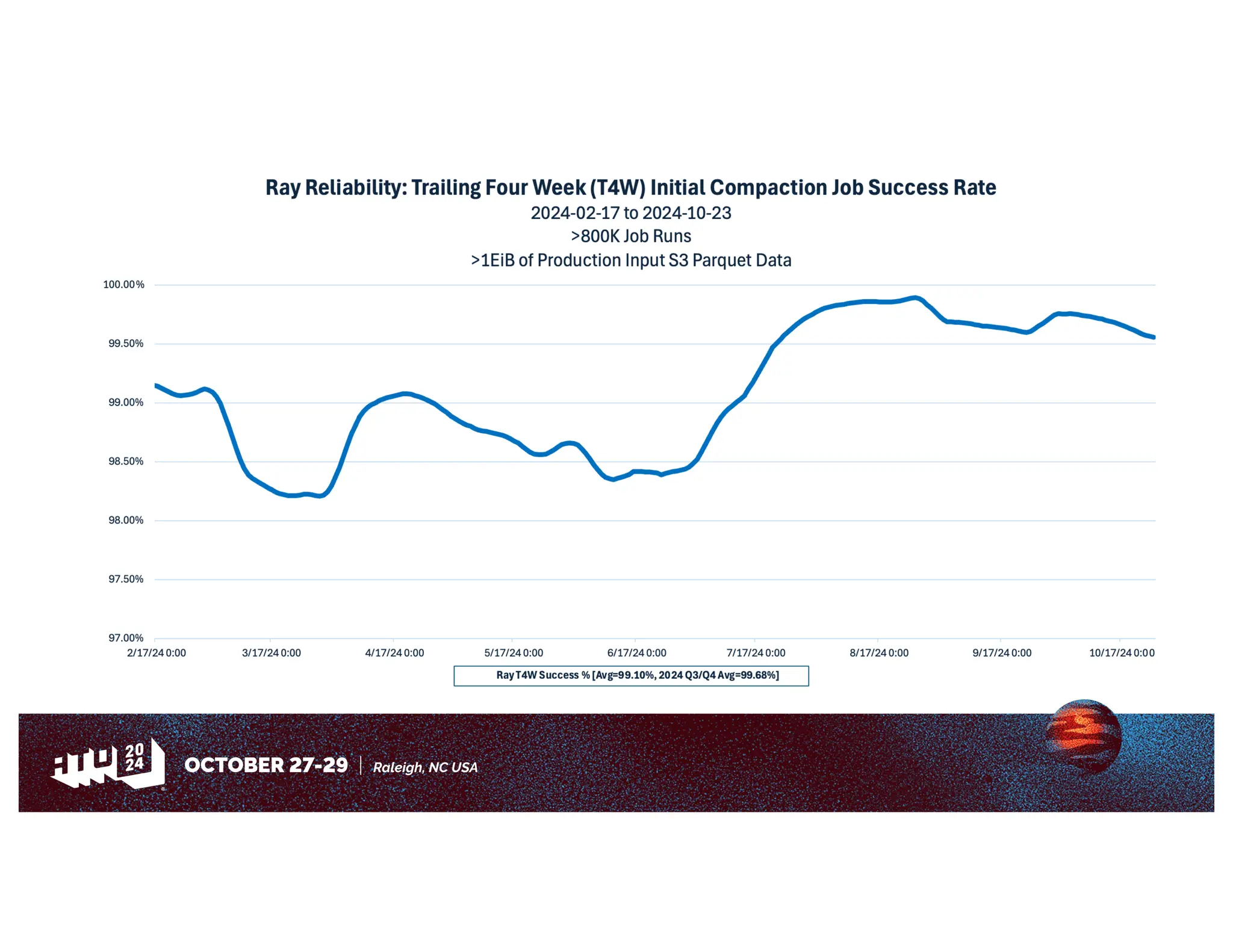
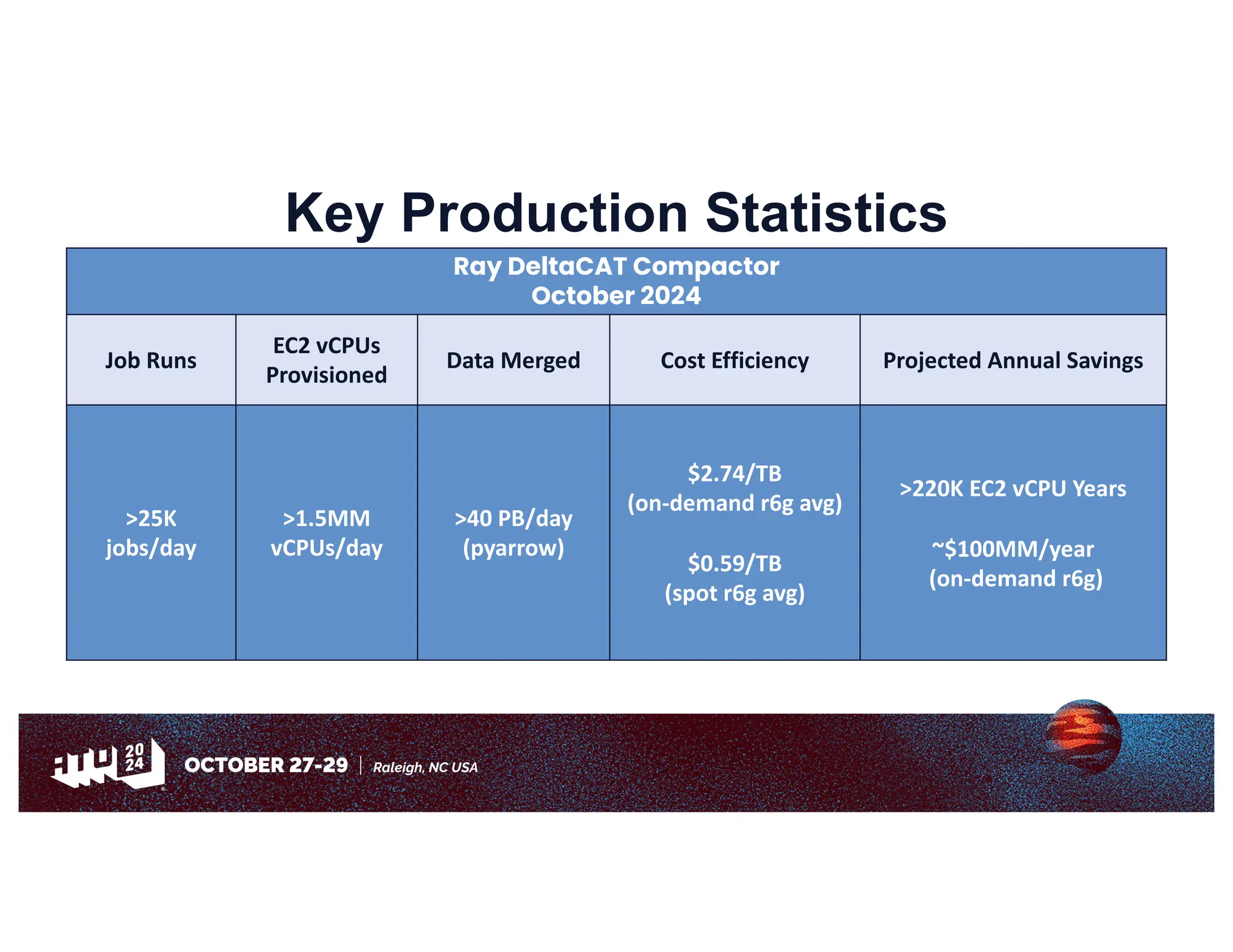








Amazon has migrated its data processing from Spark to Ray to improve efficiency and scalability of its bi pipelines. The transition involves moving compaction processes and adopting new technologies while addressing challenges such as cost, compatibility, and operational sustainability. Future work includes enhancing Apache Iceberg integration and optimizing performance across data processing workflows.


























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)








