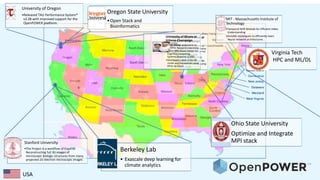
This document lists various universities and research projects related to high performance computing, machine learning, and deep learning. It mentions Rohit Mulay interning at IBM-Illinois Center for Cognitive Computing Systems Research where he developed a web UI for machine learning models and frameworks using GPUs in the cloud. It also lists projects at MIT on temporal shift modules for video understanding and AutoML techniques, Berkeley Lab on exascale deep learning for climate analytics, and Stanford on cryo-electron microscopy image reconstruction.
We live in a digital-world filled with application of matrices. Linear algebra is study of matrices and it's properties. The slides describes some of the major application of linear algebra.
Community detection in graphs with NetworKitBenj Pettit
This is a "lightning talk" I gave at the 22nd PyData London meetup on 5 April 2016. The accompanying demonstration code is at https://github.com/benjpettit/networkit-demo
We live in a digital-world filled with application of matrices. Linear algebra is study of matrices and it's properties. The slides describes some of the major application of linear algebra.
Community detection in graphs with NetworKitBenj Pettit
This is a "lightning talk" I gave at the 22nd PyData London meetup on 5 April 2016. The accompanying demonstration code is at https://github.com/benjpettit/networkit-demo
Eric Nyberg's Presentation "From Jeopardy! To Cognitive Agents: Effective Learning in the Wild" on Cognitive Systems Institute Group Speaker Series July 9, 2015
Presentation on "Practical Competences in Engineering and Technology Enhanced Learning: MOOCs and Emerging Areas at the IEEE Education Society" from the IEEE Education Society Special Technical Community on Learning Sciences at the The Chinese University of Hong Kong
In this webinar, data science expert and CEO of cnvrg.io Yochay Ettun discusses continual learning in production. This webinar examines continual learning, and will help you apply continual learning into your production models using tools like Tensorflow, Kubernetes, and cnvrg.io. This webinar for professional data scientists will go over how to monitor models when in production, and how to set up automatically adaptive machine learning.
Key webinar takeaways:
Understanding of continual learning
Optimizing your models for accuracy with continual learning
How to use TensorFlow, Kubernetes and cnvrg.io to apply CL to your models
How you can build automatically adaptive machine learning
Adapting to shifting data distributions
Coping with outliers
Retraining in production
Adapting to new tasks
A/B test your models
Deploying your machine learning pipeline to production
Watch all our webinars at https://cnvrg.io/webinars-and-workshops/
Learn why continual learning is important, and how to use it in your machine learning models to improve accuracy. You can download the full webinar here: https://info.cnvrg.io/continual-learning-webinar
These are the slides for Module 2 of Data Engineering Track, for University of Toronto, March 2022. The video playlist is available at https://www.youtube.com/playlist?list=PLWoneCyhdP1DWijBQo7zj2uJbuEXaE6E2
Keynote presentation at IEEE TALE 2013 conference - A Second Step Ahead in the Future of Labs and Learning: MOOCs, Widgets, Ubiquity and Mobility - Bali, Indonesia, August 2013 http://www.tale-conference.org/tale2013/
Silicon Electronic Photonic Integrated Circuits (SiEPIC) – Research TrainingLukas Chrostowski
June 23, 2015
Webinar
Presented for the OSA, osa.peachnewmedia.com/store/seminar/seminar.php?seminar=43624
In this webinar, Lukas Chrostowski will discuss the Canada-wide NSERC CREATE research training Program – Silicon Electronic Photonic Integrated Circuits (Si-EPIC) – which has established a large community of silicon photonics researchers. This program is based in Canada and is open to international academic and industrial participants. Since 2008, we have been offering training workshops and courses. Common to all these experiences is that they all have a design–fabricate–test cycle, namely we provide participants with feedback and get their designs fabricated. We have four design workshops that are each one week long: 1) Passive silicon photonics, 2) active silicon photonics (e.g., design of 40 Gb/s travelling-wave modulators), 3) CMOS electronics for photonics, and 4) systems, integration and packaging. We also offer half-day workshops at conferences (Group IV Photonics, IEEE Photonics Conference). Finally, we have our first on-line course starting July 7, namely edX Silicon Photonics Design, Fabrication and Data Analysis. In the conference and edX course, we include automated testing so participants can get real data to analyze. Lukas will also provide examples of research innovations, including sub-wavelength grating devices, Bragg gratings, contra-directional grating-assisted couplers, and others.
What You Will Learn/Seminar Objectives
Overview of the Canada-wide NSERC CREATE research training Program – Silicon Electronic Photonic Integrated Circuits (Si-EPIC)
Overview of our online course - edX Silicon Photonics Design, Fabrication and Data Analysis
Who Should Attend:
Graduate students, postdocs and researchers interested in the field of Silicon Photonics and Photonic Integrated Circuits.
Photonic scientists working on the design and fabrication of novel silicon nanophotonic devices.
Level: The level of the webinar is intermediate. The basic concepts will be explained. However, a basic knowledge of Silicon Photonics is assumed.
From idea to production in a day – Leveraging Azure ML and Streamlit to build...Florian Roscheck
How to leverage Azure ML, automated machine learning, and Streamlit to build and test machine learning apps quickly? Find out about our favorite Hackathon stack and walk away with some code to build and user-test your own machine learning ideas fast.
Experimentation, bringing machine learning ideas in front of users, is essential to innovation. Yet, in our corporate hackathons, our data science team has struggled many times with how to build and deploy user-facing machine learning ideas in just a single day.
Over the past 2+ years, we have developed a routine around using Azure Machine Learning, automated machine learning, and Streamlit to build and user test machine learning ideas quickly. The aim of this talk is to pass on practical, technical knowledge to fellow data scientists about how to leverage this stack to achieve high build and user test speeds.
During the talk, we will walk through the process of building a computer vision system for identifying trash in images via an app using the open-source TACO dataset (http://tacodataset.org/). Working through a Jupyter notebook, we will load the data into Azure Machine Learning and trigger an automated machine learning run on the data. In this context, we will quickly get to know the training and testing metrics available in Azure ML to evaluate the model. We will then download the machine learning model as a file packaged in the open-source ONNX format (https://onnx.ai/). Using the open-source Python web application framework Streamlit (https://github.com/streamlit/streamlit), we will program an application in which users can upload images and embed the machine learning model in it to identify trash in these images. Using a to-be-published infrastructure-as-code pipeline on Azure DevOps, we will deploy the application to the public internet on the Azure platform. From here, users can test it.
The stack and code presented in this talk will enable fellow data scientists to accelerate their data science development, leading to quicker experimentation and, therefore, to faster innovation of products with machine learning at their core.
Eric Nyberg's Presentation "From Jeopardy! To Cognitive Agents: Effective Learning in the Wild" on Cognitive Systems Institute Group Speaker Series July 9, 2015
Presentation on "Practical Competences in Engineering and Technology Enhanced Learning: MOOCs and Emerging Areas at the IEEE Education Society" from the IEEE Education Society Special Technical Community on Learning Sciences at the The Chinese University of Hong Kong
In this webinar, data science expert and CEO of cnvrg.io Yochay Ettun discusses continual learning in production. This webinar examines continual learning, and will help you apply continual learning into your production models using tools like Tensorflow, Kubernetes, and cnvrg.io. This webinar for professional data scientists will go over how to monitor models when in production, and how to set up automatically adaptive machine learning.
Key webinar takeaways:
Understanding of continual learning
Optimizing your models for accuracy with continual learning
How to use TensorFlow, Kubernetes and cnvrg.io to apply CL to your models
How you can build automatically adaptive machine learning
Adapting to shifting data distributions
Coping with outliers
Retraining in production
Adapting to new tasks
A/B test your models
Deploying your machine learning pipeline to production
Watch all our webinars at https://cnvrg.io/webinars-and-workshops/
Learn why continual learning is important, and how to use it in your machine learning models to improve accuracy. You can download the full webinar here: https://info.cnvrg.io/continual-learning-webinar
These are the slides for Module 2 of Data Engineering Track, for University of Toronto, March 2022. The video playlist is available at https://www.youtube.com/playlist?list=PLWoneCyhdP1DWijBQo7zj2uJbuEXaE6E2
Keynote presentation at IEEE TALE 2013 conference - A Second Step Ahead in the Future of Labs and Learning: MOOCs, Widgets, Ubiquity and Mobility - Bali, Indonesia, August 2013 http://www.tale-conference.org/tale2013/
Silicon Electronic Photonic Integrated Circuits (SiEPIC) – Research TrainingLukas Chrostowski
June 23, 2015
Webinar
Presented for the OSA, osa.peachnewmedia.com/store/seminar/seminar.php?seminar=43624
In this webinar, Lukas Chrostowski will discuss the Canada-wide NSERC CREATE research training Program – Silicon Electronic Photonic Integrated Circuits (Si-EPIC) – which has established a large community of silicon photonics researchers. This program is based in Canada and is open to international academic and industrial participants. Since 2008, we have been offering training workshops and courses. Common to all these experiences is that they all have a design–fabricate–test cycle, namely we provide participants with feedback and get their designs fabricated. We have four design workshops that are each one week long: 1) Passive silicon photonics, 2) active silicon photonics (e.g., design of 40 Gb/s travelling-wave modulators), 3) CMOS electronics for photonics, and 4) systems, integration and packaging. We also offer half-day workshops at conferences (Group IV Photonics, IEEE Photonics Conference). Finally, we have our first on-line course starting July 7, namely edX Silicon Photonics Design, Fabrication and Data Analysis. In the conference and edX course, we include automated testing so participants can get real data to analyze. Lukas will also provide examples of research innovations, including sub-wavelength grating devices, Bragg gratings, contra-directional grating-assisted couplers, and others.
What You Will Learn/Seminar Objectives
Overview of the Canada-wide NSERC CREATE research training Program – Silicon Electronic Photonic Integrated Circuits (Si-EPIC)
Overview of our online course - edX Silicon Photonics Design, Fabrication and Data Analysis
Who Should Attend:
Graduate students, postdocs and researchers interested in the field of Silicon Photonics and Photonic Integrated Circuits.
Photonic scientists working on the design and fabrication of novel silicon nanophotonic devices.
Level: The level of the webinar is intermediate. The basic concepts will be explained. However, a basic knowledge of Silicon Photonics is assumed.
From idea to production in a day – Leveraging Azure ML and Streamlit to build...Florian Roscheck
How to leverage Azure ML, automated machine learning, and Streamlit to build and test machine learning apps quickly? Find out about our favorite Hackathon stack and walk away with some code to build and user-test your own machine learning ideas fast.
Experimentation, bringing machine learning ideas in front of users, is essential to innovation. Yet, in our corporate hackathons, our data science team has struggled many times with how to build and deploy user-facing machine learning ideas in just a single day.
Over the past 2+ years, we have developed a routine around using Azure Machine Learning, automated machine learning, and Streamlit to build and user test machine learning ideas quickly. The aim of this talk is to pass on practical, technical knowledge to fellow data scientists about how to leverage this stack to achieve high build and user test speeds.
During the talk, we will walk through the process of building a computer vision system for identifying trash in images via an app using the open-source TACO dataset (http://tacodataset.org/). Working through a Jupyter notebook, we will load the data into Azure Machine Learning and trigger an automated machine learning run on the data. In this context, we will quickly get to know the training and testing metrics available in Azure ML to evaluate the model. We will then download the machine learning model as a file packaged in the open-source ONNX format (https://onnx.ai/). Using the open-source Python web application framework Streamlit (https://github.com/streamlit/streamlit), we will program an application in which users can upload images and embed the machine learning model in it to identify trash in these images. Using a to-be-published infrastructure-as-code pipeline on Azure DevOps, we will deploy the application to the public internet on the Azure platform. From here, users can test it.
The stack and code presented in this talk will enable fellow data scientists to accelerate their data science development, leading to quicker experimentation and, therefore, to faster innovation of products with machine learning at their core.
The Libre-SOC Project aims to create an entirely Libre-Licensed, transparently-developed fully auditable Hybrid 3D CPU-GPU-VPU, using the Supercomputer-class OpenPOWER ISA as the foundation.
Our first test ASIC is a 180nm "Fixed-Point" Power ISA v3.0B processor, 5.1mm x 5.9mm, as a proof-of-concept for the team, whose primary expertise is in Software Engineering. Software Engineering training brings a radically different approach to Hardware development: extensive unit tests, source code revision control, automated development tools are normal. Libre Project Management brings even more: bug trackers, mailing lists, auditable IRC logs and a wiki are standard fare for Libre Projects that are simply not normal Industry-Standard practice.
This talk therefore goes through the workflow, from the original HDL through to the GDS-II layout, showing how we were able to keep track of the development that led to the IMEC 180nm tape-out in July 2021. In particular, by following a parallel development process involving "Real" and "Symbolic" Cell Libraries, developed by Chips4Makers, will be shown how our developers did not need to sign a Foundry NDA, but were still able to work side-by-side with a University that did. With this parallel development process, the University upheld their NDA obligations, and Libre-SOC were simultaneously able to honour its Transparency Objectives.
Workload Transformation and Innovations in POWER Architecture Ganesan Narayanasamy
IT Industry is going through two major transformations. One is adaption of AI and tight integration of the same in the commercial applications and enterprise workflow. Two the transformation in software architecture through the concepts like microservices and the cloud native architecture. These transformation alongside the aggressive adaption of IoT/mobile and 5G in all our day today activities is making the world operate in more real time manner which opens-up a new challenge to improve the hardware architecture to adapt to these requirements. These above two major transformation pushes the boundary of the entire systems stack making the designer rethink hardware. This talk presents you a picture of how the enterprise Industry leading POWER architecture is transforming to fulfill the performance demands of these newer generation workloads with primary focus on the AI acceleration on the chip.
July 16th 2021 , Friday for our newest workshop with DoMS, IIT Roorkee, Concept to Solutions using OpenPOWER Stack. It's time to discover advances in #DeepLearning tools and techniques from the world's leading innovators across industries, research, and public speakers.
Register here:
https://lnkd.in/ggxMq2N
This presentation covers two uses cases using OpenPOWER Systems
1. Diabetic Retinopathy using AI on NVIDIA Jetson Nano: The objective is to classify the diabetic level solely on retina image in a remote area with minimum doctor's inference. The model uses VGG16 network architecture and gets trained from scratch on POWER9. The model was deployed on the Jetson Nano board.
1. Classifying Covid positivity using lung X-ray images: The idea is to build ML models to detect positive cases using X-ray images. The model was trained on POWER9, and the application was developed using Python.
IBM Bayesian Optimization Accelerator (BOA) is a do-it-yourself toolkit to apply state-of-the-art Bayesian inferencing techniques and obtain optimal solutions for complex, real-world design simulations without requiring deep machine learning skills. This talk will describe IBM BOA, its differentiation and ease of use, and how researchers can take advantage of it for optimizing any arbitrary HPC simulation.
This presentation covers various partners and collaborators who are currently working with OpenPOWER foundation ,Use cases of OpenPOWER systems in multiple Industries , OpenPOWER Workgroups and OpenCAPI features .
The IBM POWER10 processor represents the 10th generation of the POWER family of enterprise computing engines. Its performance is a result of both powerful processing cores and high-bandwidth intra- and inter-chip interconnect. POWER10 systems can be configured with up to 16 processor chips and 1920 simultaneous threads of execution. Cross-system memory sharing, through the new Memory Inception technology, and 2 Petabytes of addressing space support an expansive memory system. The POWER10 processing core has been significantly enhanced over its POWER9 predecessor, including a doubling of vector units and the addition of an all-new matrix math engine. Throughput gains from POWER9 to POWER10 average 30% at the core level and three-fold at the socket level. Those gains can reach ten- or twenty-fold at the socket level for matrix-intensive computations.
Everything is changing from Health Care to the Automotive markets without forgetting Financial markets or any type of engineering everything has stopped being created as an individual or best-case scenario a team effort to something that is being developed and perfectioned by using AI and hundreds of computers. And even AI is something that we no longer can run in a single computer, no matter how powerful it is. What drives everything today is HPC or High-Performance Computing heavily linked to AI In this session we will discuss about AI, HPC computing, IBM Power architecture and how it can help develop better Healthcare, better Automobiles, better financials and better everything that we run on them
Macromolecular crystallography is an experimental technique allowing to explore 3D atomic structure of proteins, used by academics for research in biology and by pharmaceutical companies in rational drug design. While up to now development of the technique was limited by scientific instruments performance, recently computing performance becomes a key limitation. In my presentation I will present a computing challenge to handle 18 GB/s data stream coming from the new X-ray detector. I will show PSI experiences in applying conventional hardware for the task and why this attempt failed. I will then present how IC 922 server with OpenCAPI enabled FPGA boards allowed to build a sustainable and scalable solution for high speed data acquisition. Finally, I will give a perspective, how the advancement in hardware development will enable better science by users of the Swiss Light Source.
AI in healthcare and Automobile Industry using OpenPOWER/IBM POWER9 systemsGanesan Narayanasamy
As the adoption of AI technologies increases and matures, the focus will shift from exploration to time to market, productivity and integration with existing workflows. Governing Enterprise data, scaling AI model development, selecting a complete, collaborative hybrid platform and tools for rapid solution deployments are key focus areas for growing data scientist teams tasked to respond to business challenges. This talk will cover the challenges and innovations for AI at scale for the Industires such as Healthcare and Automotive , the AI ladder and AI life cycle and infrastructure architecture considerations.
This talk gives an introduction about Healthcare Use cases - The AI ladder and Lifestyle AI at Scale Themes The iterative nature of the workflow and some of the important components to be aware in developing AI health care solutions were being discussed. The different types of algorithms and when machine learning might be more appropriate in deep learning or the other way will also be discussed. Use cases in terms of examples are also shared as part of this presentation .
Healthcare has became one of the most important aspects of everyones life. Its importance has surged due to the latests outbreaks and due to this latest pandemic it has become mandatory to collaborate to improve everyones Healthcare as soon as possible.
IBM has reacted quickly sharing not only its knowledge but also its Artificial Intelligence Supercomputers all around the world.
Those Supercomputers are helping to prevail this outbreak and also future ones.
They have completely different features compared to proposals from other players of this Supercomputers market.
We will try to make a quick look at the differences of those AI focused Supercomputers and how they can help in the R&D of Healthcare solutions for everyone, from those ones with access to a big IBM AI Supercomputer to those ones with access to only one small IBM AI focused server.
Healthcare has became one of the most important aspects of everyones life. Its importance has surged due to the latests outbreaks and due to this latest pandemic it has become mandatory to collaborate to improve everyones Healthcare as soon as possible.
IBM has reacted quickly sharing not only its knowledge but also its Artificial Intelligence Supercomputers all around the world.
Those Supercomputers are helping to prevail this outbreak and also future ones.
They have completely different features compared to proposals from other players of this Supercomputers market.
We will try to make a quick look at the differences of those AI focused Supercomputers and how they can help in the R&D of Healthcare solutions for everyone, from those ones with access to a big IBM AI Supercomputer to those ones with access to only one small IBM AI focused server.
Moving object recognition (MOR) corresponds to the localization and classification of moving objects in videos. Discriminating moving objects from static objects and background in videos is an essential task for many computer vision applications. MOR has widespread applications in intelligent visual surveillance, intrusion detection, anomaly detection and monitoring, industrial sites monitoring, detection-based tracking, autonomous vehicles, etc. In this session, Murari provided a poster about the deep learning algorithms to identify both locations and corresponding categories of moving objects with a convolutional network. The challenges in developing such algorithms have been discussed.
Clarisse Hedglin from IBM presented this as part of 3 days International Summit .. She shared the scenarios AI can solve for today using the IBM AI infrastructure.
GraphRAG is All You need? LLM & Knowledge GraphGuy Korland
Guy Korland, CEO and Co-founder of FalkorDB, will review two articles on the integration of language models with knowledge graphs.
1. Unifying Large Language Models and Knowledge Graphs: A Roadmap.
https://arxiv.org/abs/2306.08302
2. Microsoft Research's GraphRAG paper and a review paper on various uses of knowledge graphs:
https://www.microsoft.com/en-us/research/blog/graphrag-unlocking-llm-discovery-on-narrative-private-data/
Software Delivery At the Speed of AI: Inflectra Invests In AI-Powered QualityInflectra
In this insightful webinar, Inflectra explores how artificial intelligence (AI) is transforming software development and testing. Discover how AI-powered tools are revolutionizing every stage of the software development lifecycle (SDLC), from design and prototyping to testing, deployment, and monitoring.
Learn about:
• The Future of Testing: How AI is shifting testing towards verification, analysis, and higher-level skills, while reducing repetitive tasks.
• Test Automation: How AI-powered test case generation, optimization, and self-healing tests are making testing more efficient and effective.
• Visual Testing: Explore the emerging capabilities of AI in visual testing and how it's set to revolutionize UI verification.
• Inflectra's AI Solutions: See demonstrations of Inflectra's cutting-edge AI tools like the ChatGPT plugin and Azure Open AI platform, designed to streamline your testing process.
Whether you're a developer, tester, or QA professional, this webinar will give you valuable insights into how AI is shaping the future of software delivery.
Builder.ai Founder Sachin Dev Duggal's Strategic Approach to Create an Innova...Ramesh Iyer
In today's fast-changing business world, Companies that adapt and embrace new ideas often need help to keep up with the competition. However, fostering a culture of innovation takes much work. It takes vision, leadership and willingness to take risks in the right proportion. Sachin Dev Duggal, co-founder of Builder.ai, has perfected the art of this balance, creating a company culture where creativity and growth are nurtured at each stage.
Epistemic Interaction - tuning interfaces to provide information for AI supportAlan Dix
Paper presented at SYNERGY workshop at AVI 2024, Genoa, Italy. 3rd June 2024
https://alandix.com/academic/papers/synergy2024-epistemic/
As machine learning integrates deeper into human-computer interactions, the concept of epistemic interaction emerges, aiming to refine these interactions to enhance system adaptability. This approach encourages minor, intentional adjustments in user behaviour to enrich the data available for system learning. This paper introduces epistemic interaction within the context of human-system communication, illustrating how deliberate interaction design can improve system understanding and adaptation. Through concrete examples, we demonstrate the potential of epistemic interaction to significantly advance human-computer interaction by leveraging intuitive human communication strategies to inform system design and functionality, offering a novel pathway for enriching user-system engagements.
DevOps and Testing slides at DASA ConnectKari Kakkonen
My and Rik Marselis slides at 30.5.2024 DASA Connect conference. We discuss about what is testing, then what is agile testing and finally what is Testing in DevOps. Finally we had lovely workshop with the participants trying to find out different ways to think about quality and testing in different parts of the DevOps infinity loop.
Search and Society: Reimagining Information Access for Radical FuturesBhaskar Mitra
The field of Information retrieval (IR) is currently undergoing a transformative shift, at least partly due to the emerging applications of generative AI to information access. In this talk, we will deliberate on the sociotechnical implications of generative AI for information access. We will argue that there is both a critical necessity and an exciting opportunity for the IR community to re-center our research agendas on societal needs while dismantling the artificial separation between the work on fairness, accountability, transparency, and ethics in IR and the rest of IR research. Instead of adopting a reactionary strategy of trying to mitigate potential social harms from emerging technologies, the community should aim to proactively set the research agenda for the kinds of systems we should build inspired by diverse explicitly stated sociotechnical imaginaries. The sociotechnical imaginaries that underpin the design and development of information access technologies needs to be explicitly articulated, and we need to develop theories of change in context of these diverse perspectives. Our guiding future imaginaries must be informed by other academic fields, such as democratic theory and critical theory, and should be co-developed with social science scholars, legal scholars, civil rights and social justice activists, and artists, among others.
Essentials of Automations: Optimizing FME Workflows with ParametersSafe Software
Are you looking to streamline your workflows and boost your projects’ efficiency? Do you find yourself searching for ways to add flexibility and control over your FME workflows? If so, you’re in the right place.
Join us for an insightful dive into the world of FME parameters, a critical element in optimizing workflow efficiency. This webinar marks the beginning of our three-part “Essentials of Automation” series. This first webinar is designed to equip you with the knowledge and skills to utilize parameters effectively: enhancing the flexibility, maintainability, and user control of your FME projects.
Here’s what you’ll gain:
- Essentials of FME Parameters: Understand the pivotal role of parameters, including Reader/Writer, Transformer, User, and FME Flow categories. Discover how they are the key to unlocking automation and optimization within your workflows.
- Practical Applications in FME Form: Delve into key user parameter types including choice, connections, and file URLs. Allow users to control how a workflow runs, making your workflows more reusable. Learn to import values and deliver the best user experience for your workflows while enhancing accuracy.
- Optimization Strategies in FME Flow: Explore the creation and strategic deployment of parameters in FME Flow, including the use of deployment and geometry parameters, to maximize workflow efficiency.
- Pro Tips for Success: Gain insights on parameterizing connections and leveraging new features like Conditional Visibility for clarity and simplicity.
We’ll wrap up with a glimpse into future webinars, followed by a Q&A session to address your specific questions surrounding this topic.
Don’t miss this opportunity to elevate your FME expertise and drive your projects to new heights of efficiency.
Connector Corner: Automate dynamic content and events by pushing a buttonDianaGray10
Here is something new! In our next Connector Corner webinar, we will demonstrate how you can use a single workflow to:
Create a campaign using Mailchimp with merge tags/fields
Send an interactive Slack channel message (using buttons)
Have the message received by managers and peers along with a test email for review
But there’s more:
In a second workflow supporting the same use case, you’ll see:
Your campaign sent to target colleagues for approval
If the “Approve” button is clicked, a Jira/Zendesk ticket is created for the marketing design team
But—if the “Reject” button is pushed, colleagues will be alerted via Slack message
Join us to learn more about this new, human-in-the-loop capability, brought to you by Integration Service connectors.
And...
Speakers:
Akshay Agnihotri, Product Manager
Charlie Greenberg, Host
"Impact of front-end architecture on development cost", Viktor TurskyiFwdays
I have heard many times that architecture is not important for the front-end. Also, many times I have seen how developers implement features on the front-end just following the standard rules for a framework and think that this is enough to successfully launch the project, and then the project fails. How to prevent this and what approach to choose? I have launched dozens of complex projects and during the talk we will analyze which approaches have worked for me and which have not.
UiPath Test Automation using UiPath Test Suite series, part 4DianaGray10
Welcome to UiPath Test Automation using UiPath Test Suite series part 4. In this session, we will cover Test Manager overview along with SAP heatmap.
The UiPath Test Manager overview with SAP heatmap webinar offers a concise yet comprehensive exploration of the role of a Test Manager within SAP environments, coupled with the utilization of heatmaps for effective testing strategies.
Participants will gain insights into the responsibilities, challenges, and best practices associated with test management in SAP projects. Additionally, the webinar delves into the significance of heatmaps as a visual aid for identifying testing priorities, areas of risk, and resource allocation within SAP landscapes. Through this session, attendees can expect to enhance their understanding of test management principles while learning practical approaches to optimize testing processes in SAP environments using heatmap visualization techniques
What will you get from this session?
1. Insights into SAP testing best practices
2. Heatmap utilization for testing
3. Optimization of testing processes
4. Demo
Topics covered:
Execution from the test manager
Orchestrator execution result
Defect reporting
SAP heatmap example with demo
Speaker:
Deepak Rai, Automation Practice Lead, Boundaryless Group and UiPath MVP
LF Energy Webinar: Electrical Grid Modelling and Simulation Through PowSyBl -...DanBrown980551
Do you want to learn how to model and simulate an electrical network from scratch in under an hour?
Then welcome to this PowSyBl workshop, hosted by Rte, the French Transmission System Operator (TSO)!
During the webinar, you will discover the PowSyBl ecosystem as well as handle and study an electrical network through an interactive Python notebook.
PowSyBl is an open source project hosted by LF Energy, which offers a comprehensive set of features for electrical grid modelling and simulation. Among other advanced features, PowSyBl provides:
- A fully editable and extendable library for grid component modelling;
- Visualization tools to display your network;
- Grid simulation tools, such as power flows, security analyses (with or without remedial actions) and sensitivity analyses;
The framework is mostly written in Java, with a Python binding so that Python developers can access PowSyBl functionalities as well.
What you will learn during the webinar:
- For beginners: discover PowSyBl's functionalities through a quick general presentation and the notebook, without needing any expert coding skills;
- For advanced developers: master the skills to efficiently apply PowSyBl functionalities to your real-world scenarios.
LF Energy Webinar: Electrical Grid Modelling and Simulation Through PowSyBl -...
AI collaborations in US
1. University of Illinois at
Urbana-Champaign
•Rohit Mulay underwent an
Summer Research Internship
at the IBM-Illinois Center for
Cognitive Computing
Systems Research (C3SR).
•Developed a Web UI for ML
model and frameworks using
GPUs on Cloud.
Oregon State University
•Open Stack and
Bioinformatics
University of Oregon
•Released TAU Performance System®
v2.28 with improved support for the
OpenPOWER platform.
MIT - Massachusetts Institute of
Technology
•Temporal Shift Module for Efficient Video
Understanding
•AutoML techniques to efficiently learn
neural network architectures .
Berkeley Lab
• Exascale deep learning for
climate analytics
Stanford University
•The Project is a workflow of CryoEM:
Reconstructing full 3D images of
microscopic biologic structures from many
projected 2D electron microscopic images
USA
F Virginia Tech
HPC and ML/DL
University of Illinois at
Urbana-Champaign
•Rohit Mulay underwent an
Summer Research Internship
at the IBM-Illinois Center for
Cognitive Computing
Systems Research (C3SR).
•Developed a Web UI for ML
model and frameworks using
GPUs on Cloud.
Ohio State University
Optimize and Integrate
MPI stack