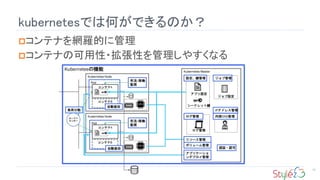
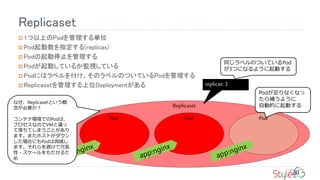
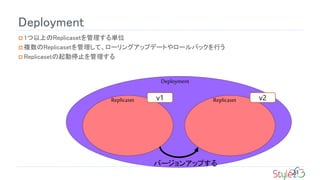
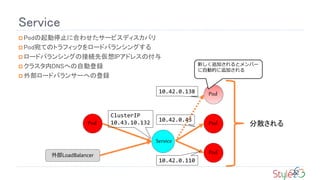
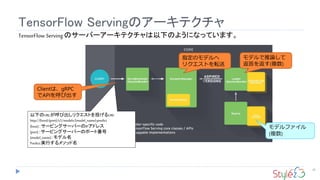
Service
Podの起動停止に合わせたサービスディスカバリ
Pod宛てのトラフィックをロードバランシングする
ロードバランシングの接続先仮想IPアドレスの付与
クラスタ内DNSへの自動登録
外部ロードバランサーへの登録
22
Service
Pod
Pod
Pod
Pod
外部LoadBalancer
10.42.0.138
10.42.0.43
10.42.0.110
ClusterIP
10.43.10.132 分散される
新しく追加されるとメンバー
に自動的に追加される













![Config
Map
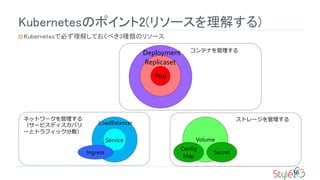
ConfigMap&Secret
設定用情報を管理する
環境変数で参照することができる
ファイルから作成し、Volumeとしてマウントするとファイルとして参照することができる
24
Config
Map
設定ファイル
設定ファイル
Config
Map
Config
Map
環境変数
環境変数
Pod
Pod
設定ファイル
環境変数
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user
[$time_local] "$request" '
'$status $body_bytes_sent
"$http_referer" '
'"$http_user_agent"
"$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
include /etc/nginx/conf.d/*.conf;
}
nginx.conf
nginx.conf](https://image.slidesharecdn.com/containerorchestrationai-190418024240/85/AI-25-320.jpg)



































![Re: ご注文は自動化ですか?[2]](https://cdn.slidesharecdn.com/ss_thumbnails/reistheorderanautomation2-140721190205-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

































