Downloaded 12 times










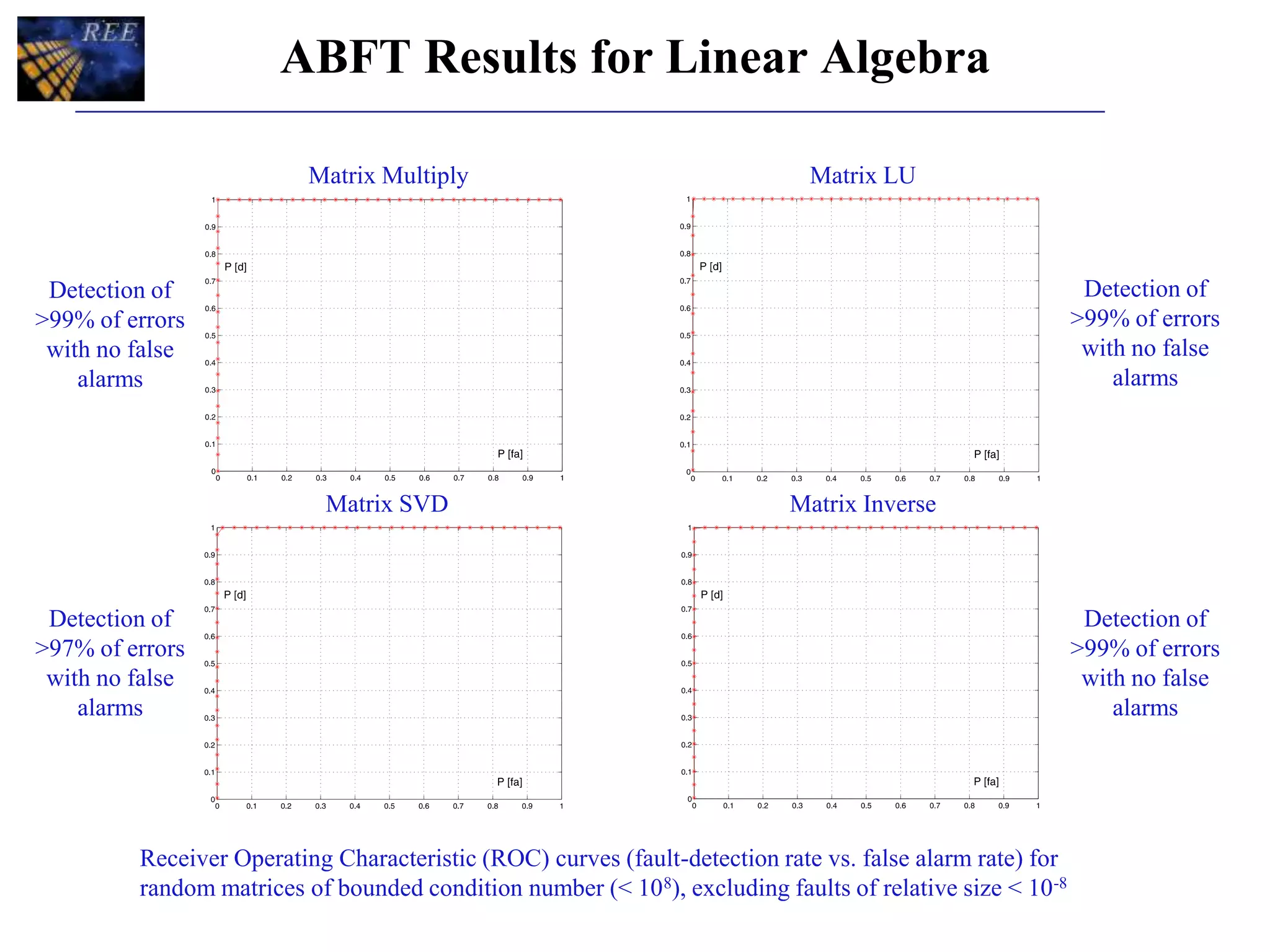


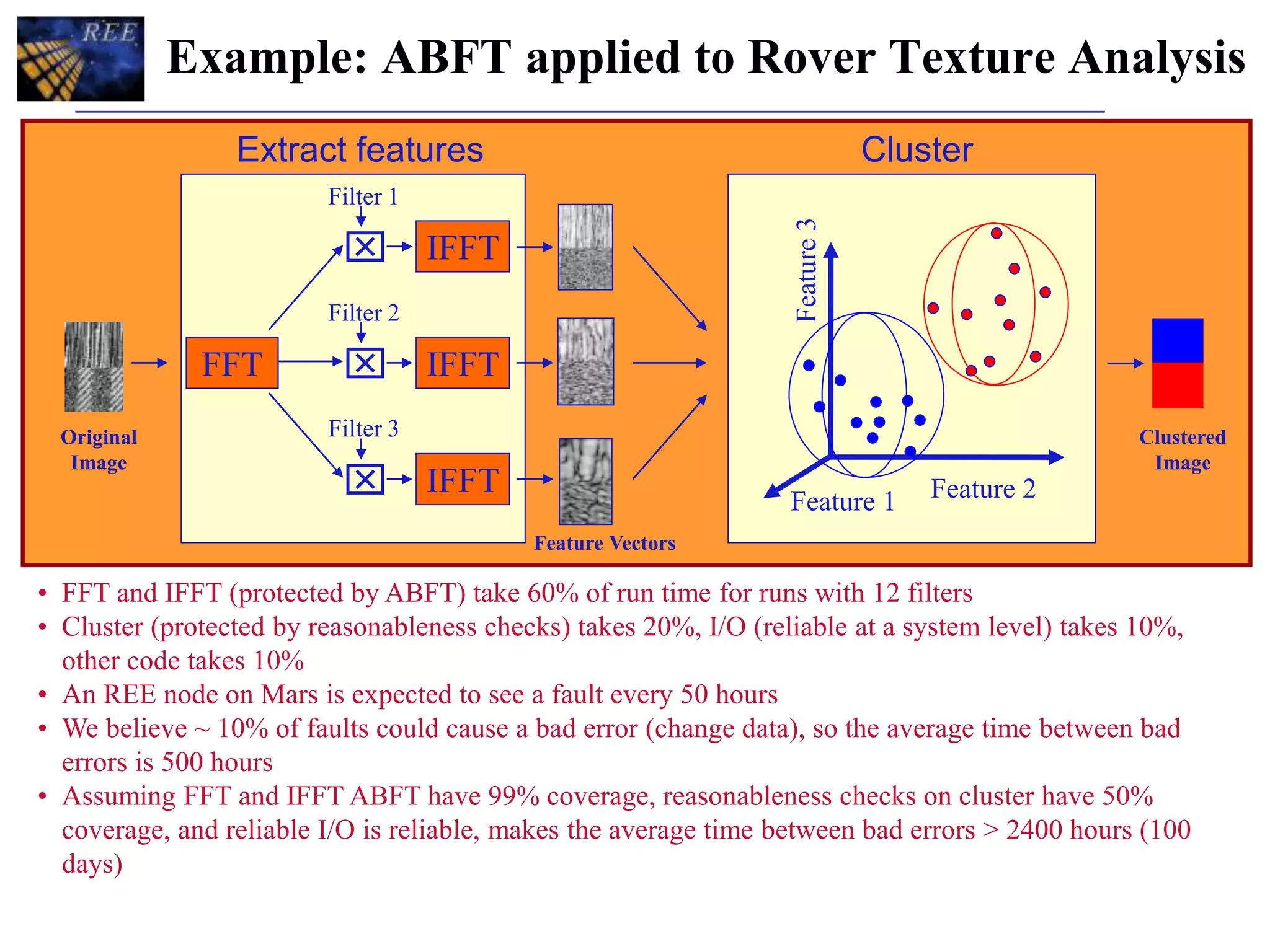









The document discusses application fault tolerance (AFT) strategies for using non-radiation-hardened processors in onboard processing systems to handle errors and faults. It emphasizes the importance of periodic error reporting, state checkpointing, and algorithm-based fault tolerance (ABFT) techniques to safeguard against errors in critical computations like matrix multiplications and fast Fourier transform (FFT). Additionally, it covers application layer fault tolerance and detection (ALFTD) principles, which enable physical nodes to manage fault detection while maintaining acceptable performance levels.























































































