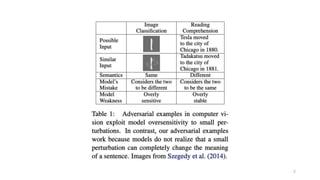
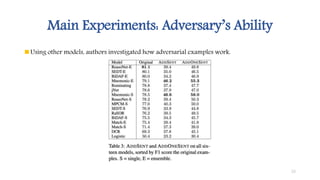
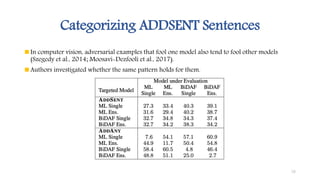
The document summarizes a research paper that proposes using adversarial examples to evaluate reading comprehension systems. The researchers generated adversarial examples for the SQuAD question answering dataset by adding sentences to paragraphs that maintain the original answer but cause systems to predict the wrong answer. They introduced four methods for generating adversarial examples and showed their ability to significantly reduce the accuracy of two state-of-the-art question answering models, demonstrating limitations in these systems' understanding of language.


































![[Paper Review] Audio adversarial examples](https://cdn.slidesharecdn.com/ss_thumbnails/labmeeting20180114audioadversarialexamples-180126121342-thumbnail.jpg?width=640&height=640&fit=bounds)

































