Downloaded 319 times
















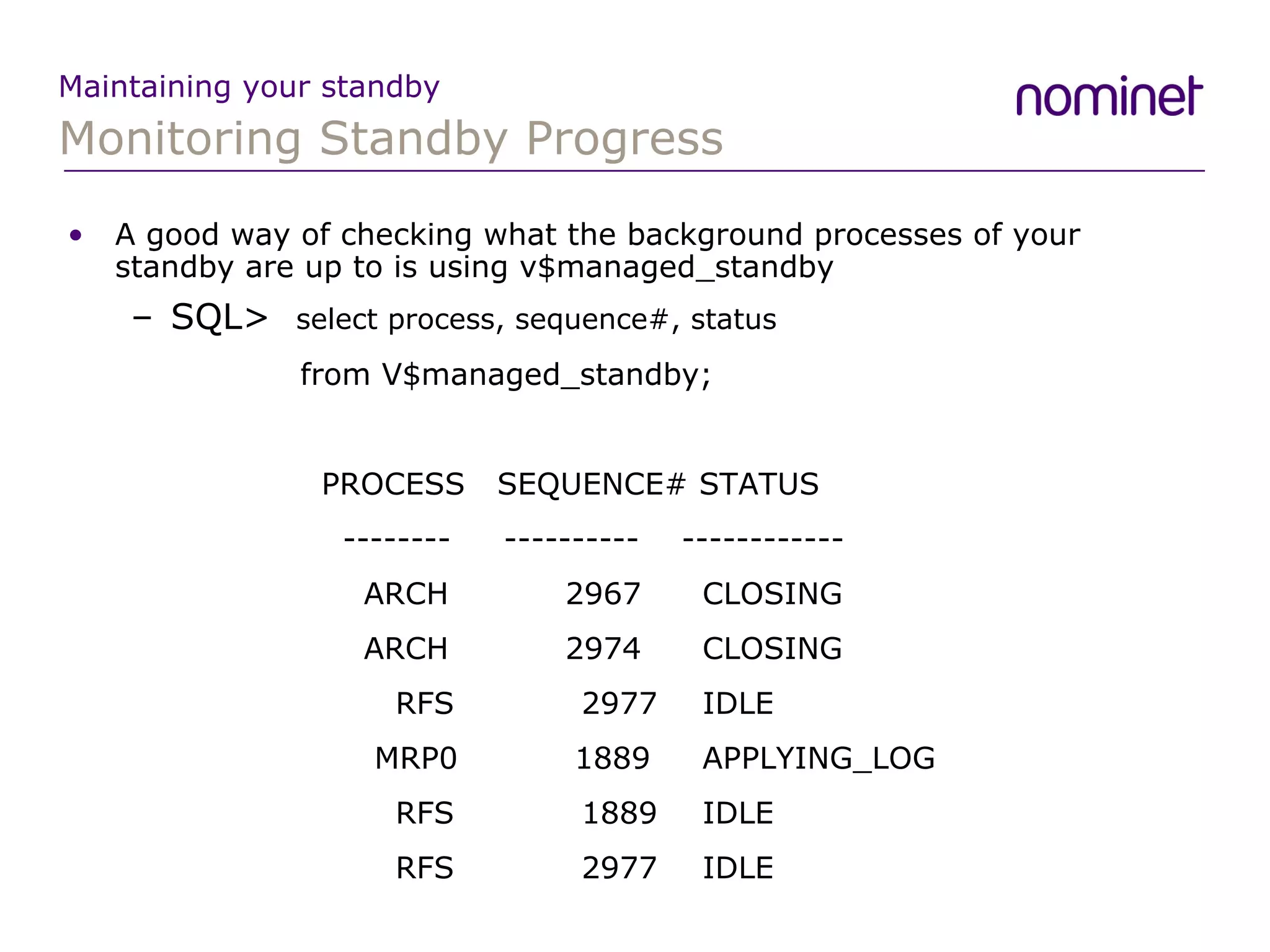

![Monitoring Your Standby Maintaining your standby A way of finding out what has been happening to your standby over a period time is to look at the v$dataguard_status view Log Apply Services 01-AUG-07 Media Recovery Waiting for thread 1 sequence 2977 (in transit) Log Apply Services 01-AUG-07 Media Recovery Waiting for thread 1 sequence 2977 (in transit) Log Apply Services 01-AUG-07 Media Recovery Waiting for thread 2 sequence 1889 (in transit) Remote File Server 01-AUG-07 Primary database is in MAXIMUM PERFORMANCE mode Remote File Server 01-AUG-07 RFS[53]: Successfully opened standby log 14: '+DATA2/standby/standbyredo02.log'](https://image.slidesharecdn.com/dataguard07-090311145821-phpapp01/75/Adventures-in-Dataguard-20-2048.jpg)
![Oracle can’t divide by 0 Maintaining your standby Standby was happily working away ORA-07445: exception encountered: core dump [kcrarmb()+152] [SIGFPE] [Integer divide by zero] [0x00085C300 MRP process crashes No redo gets applied from this point Logs after the one that caused the ORA-07445 still being shipped A simple restart of the managed recovery process does a FAL and the standby is back up-to-date](https://image.slidesharecdn.com/dataguard07-090311145821-phpapp01/75/Adventures-in-Dataguard-21-2048.jpg)
![kcrfr_resize2 Maintaining your standby Lots of problems after upgrade to 10.2.0.3 Recovery of Online Redo Log: Thread 2 Group 23 Seq 999 Reading mem 0 Mem# 0: +DATA3/standby/standbyredo11.log ORA-00600: internal error code, arguments: [kcrfr_resize2], [652614828032], [268423168], [], [], [], [], [] Perhaps caused by the following: Bug 3306010 OERI[kcrfr_resize2] possible in MEDIA recovery Media recovery may fail with ORA-600 [kcrfr_resize2] when the number of redo strands is set to a high value using log_parallelism.](https://image.slidesharecdn.com/dataguard07-090311145821-phpapp01/75/Adventures-in-Dataguard-22-2048.jpg)

![kcrrupirfs Maintaining your standby ARC processes died on primary: ORA-00600: [kcrrupirfs.20] [4] [368] Trace file showed the following: Corrupt redo block 479421 detected: bad block number Flag: 0x0 Format: 0x0 Block: 0x00000000 Seq: 0x00000000 Beg: 0x0 Cks:0x0 <<<<<<<-- ----- Dump of Corrupt Redo Buffer -----000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000](https://image.slidesharecdn.com/dataguard07-090311145821-phpapp01/75/Adventures-in-Dataguard-24-2048.jpg)





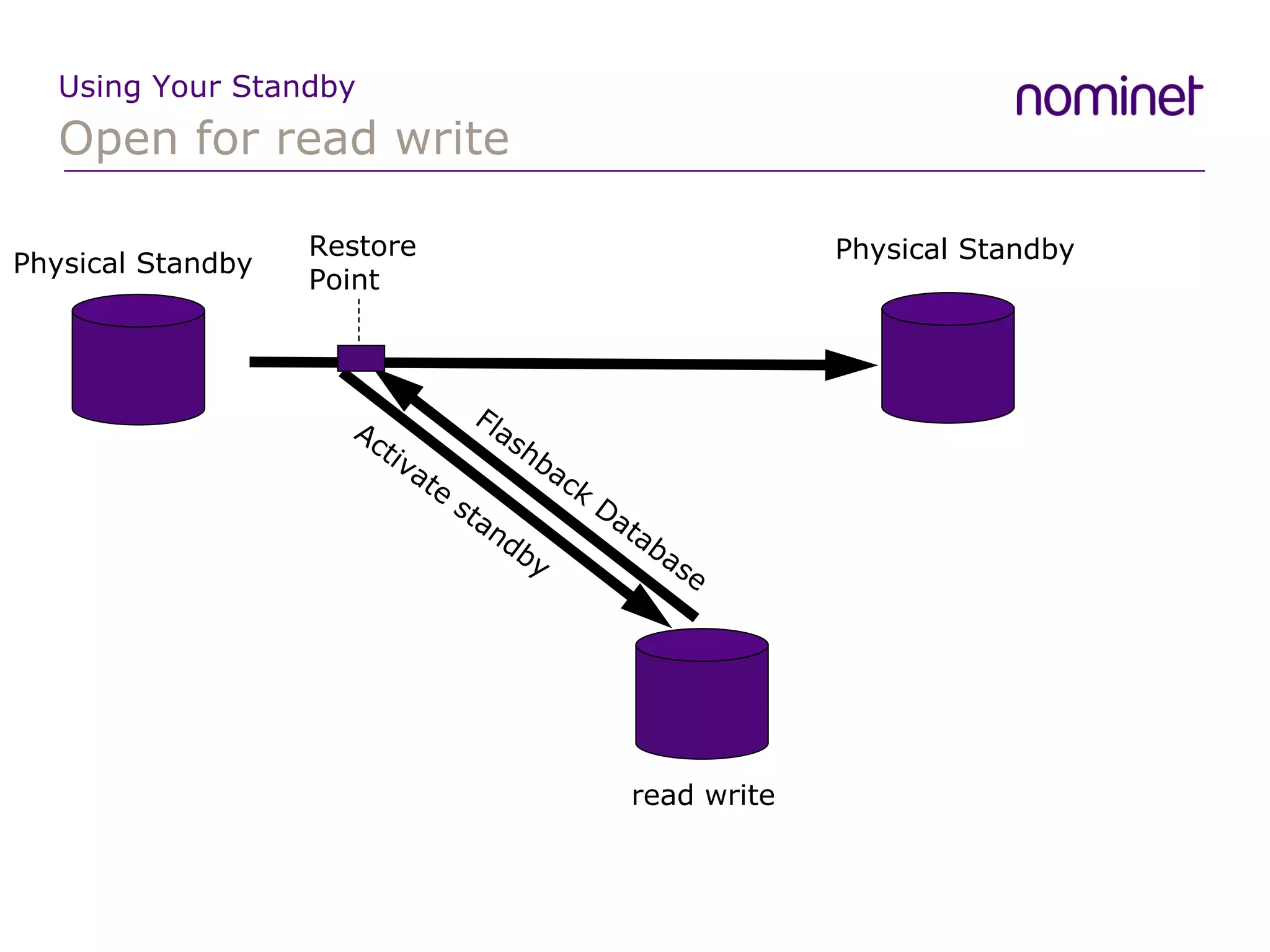


![Open for read write Using Your Standby However things never go according to plan ORA-00600: internal error code, arguments: [3705], [1], [8], [3], [8], [], [] This was bug 4479323 which is a bug with recovery (not standby specific) and only occurs in a RAC environment This is fixed in 10.2.0.3](https://image.slidesharecdn.com/dataguard07-090311145821-phpapp01/75/Adventures-in-Dataguard-34-2048.jpg)



![Questions? Adventures in Dataguard Contact: [email_address] http://blog.nominet.org.uk](https://image.slidesharecdn.com/dataguard07-090311145821-phpapp01/75/Adventures-in-Dataguard-39-2048.jpg)

This document summarizes the key aspects of configuring and using Oracle Dataguard for disaster recovery. It discusses setting up a physical standby database, monitoring the replication process, and utilizing the standby for tasks like reporting and testing. Switching the primary and standby roles is also covered.


































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)









