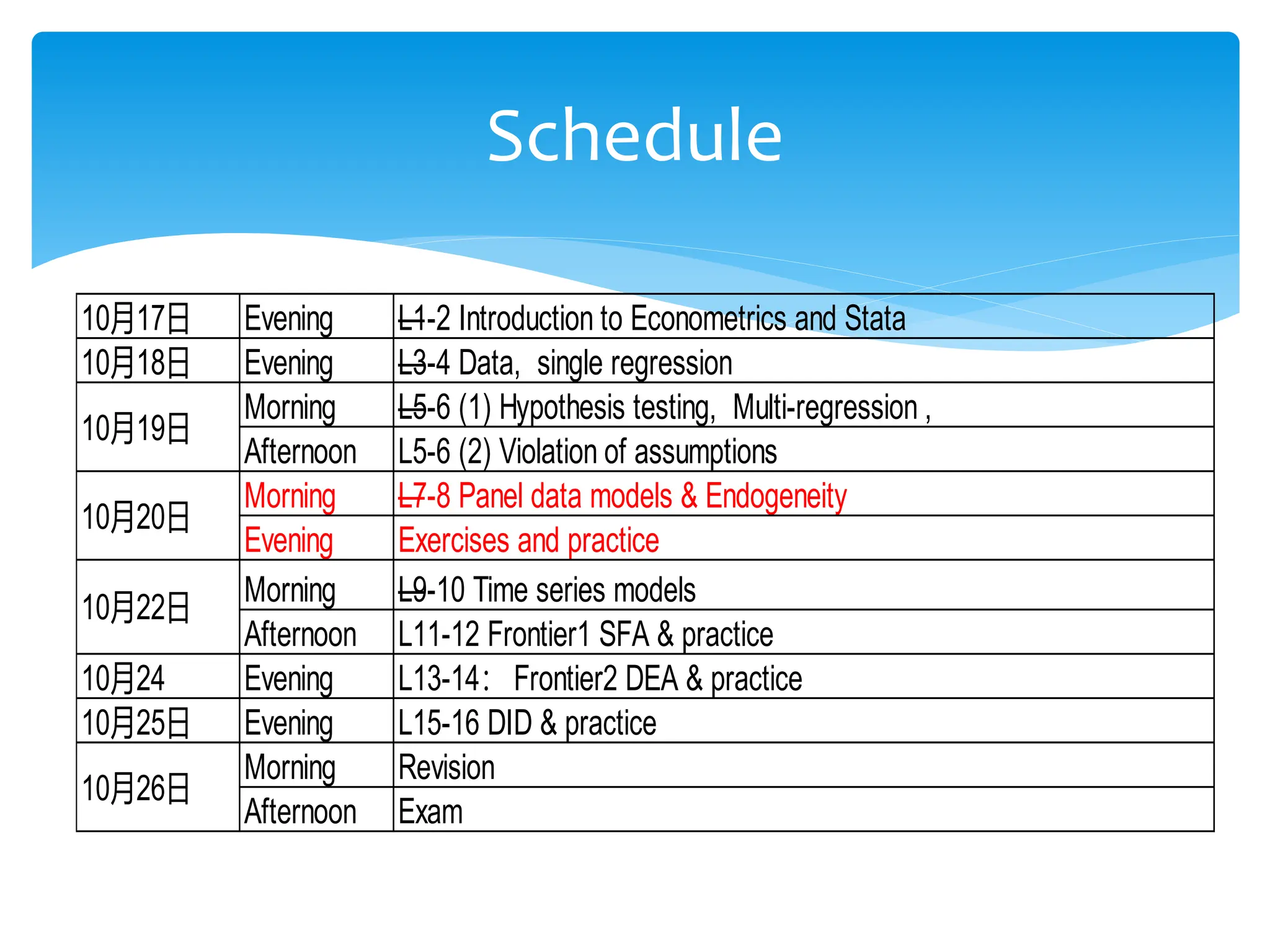
This document provides an overview of a panel data analysis course, including:
- The schedule, which covers topics like panel data models, endogeneity, time series models, and difference-in-differences.
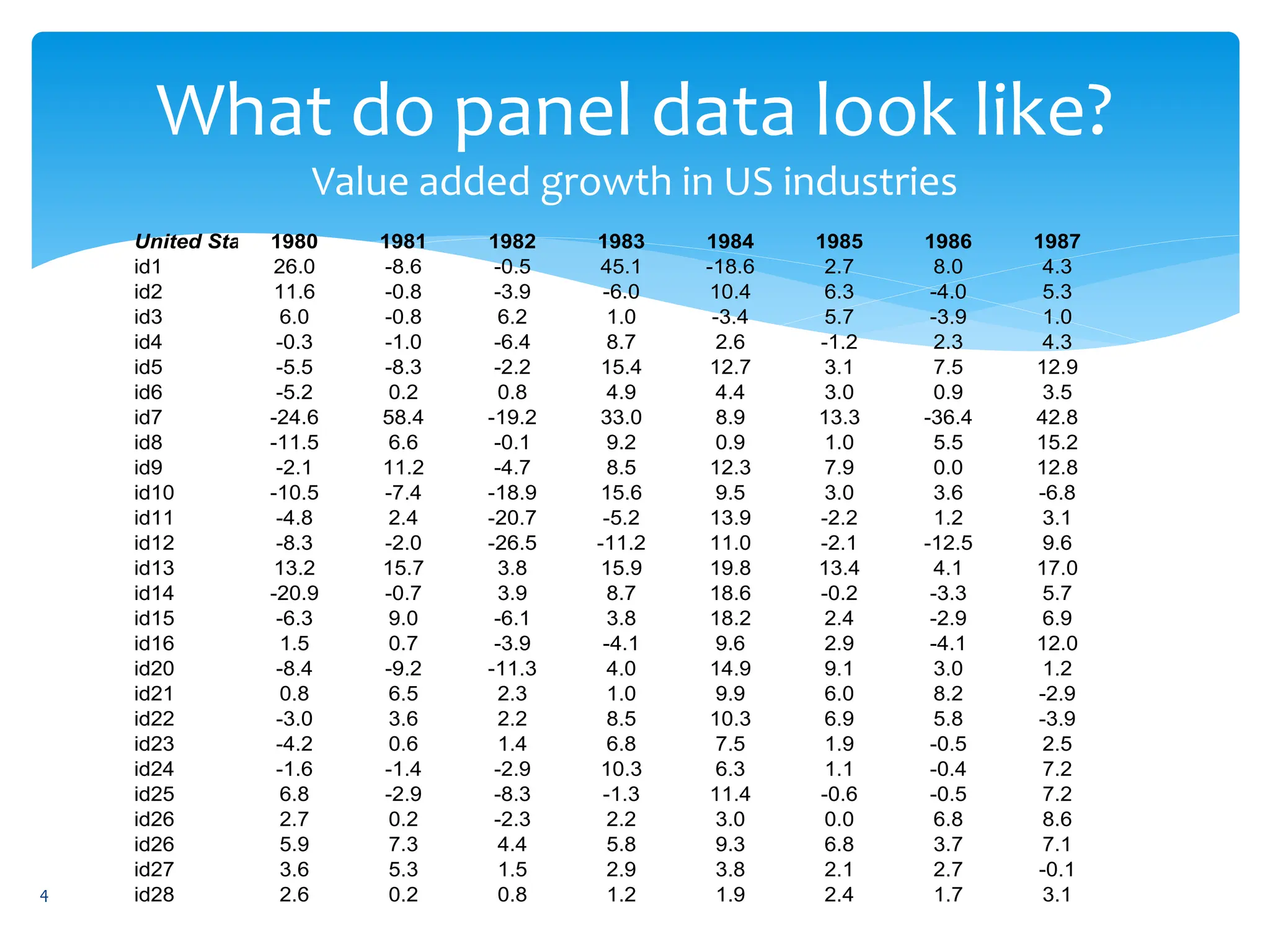
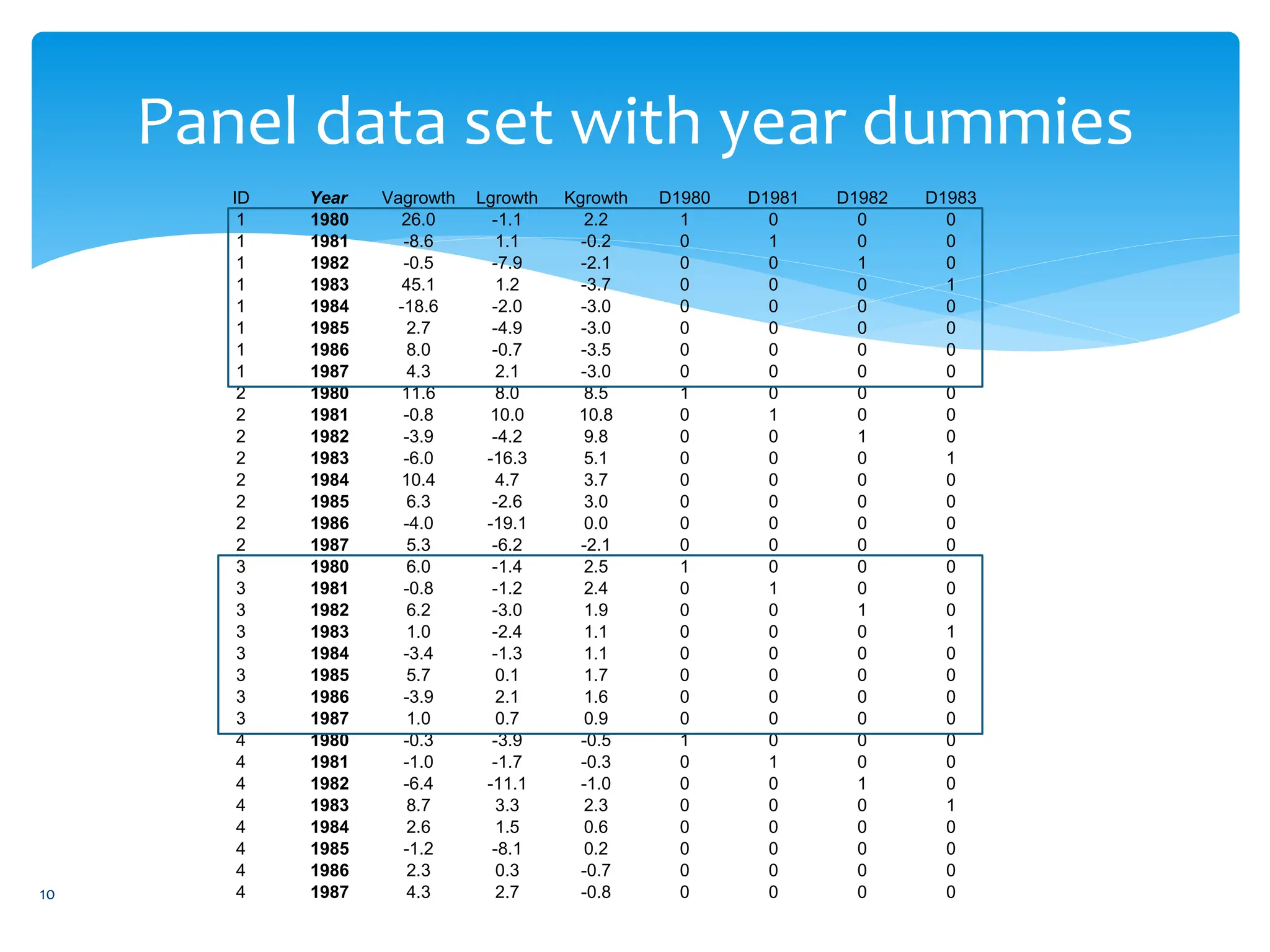
- An explanation of panel data, which has multiple cross-sections observed over time, and how it can be balanced or unbalanced.
- Examples of how panel data is structured and why it is useful for studying dynamic changes and effects not seen in cross-section or time series data alone.
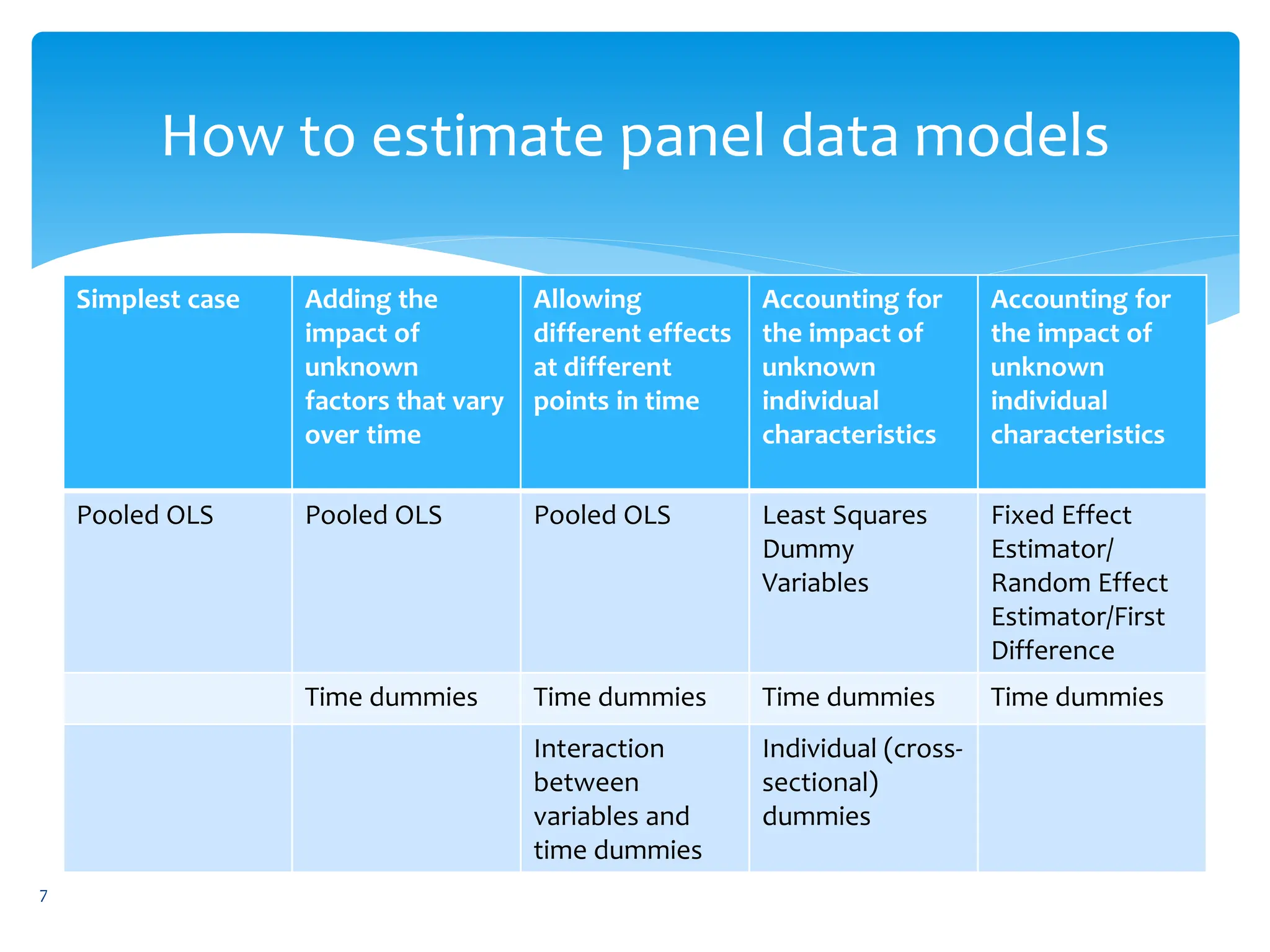
- Methods for estimating panel data models, ranging from simple pooled OLS to fixed effects and random effects models.














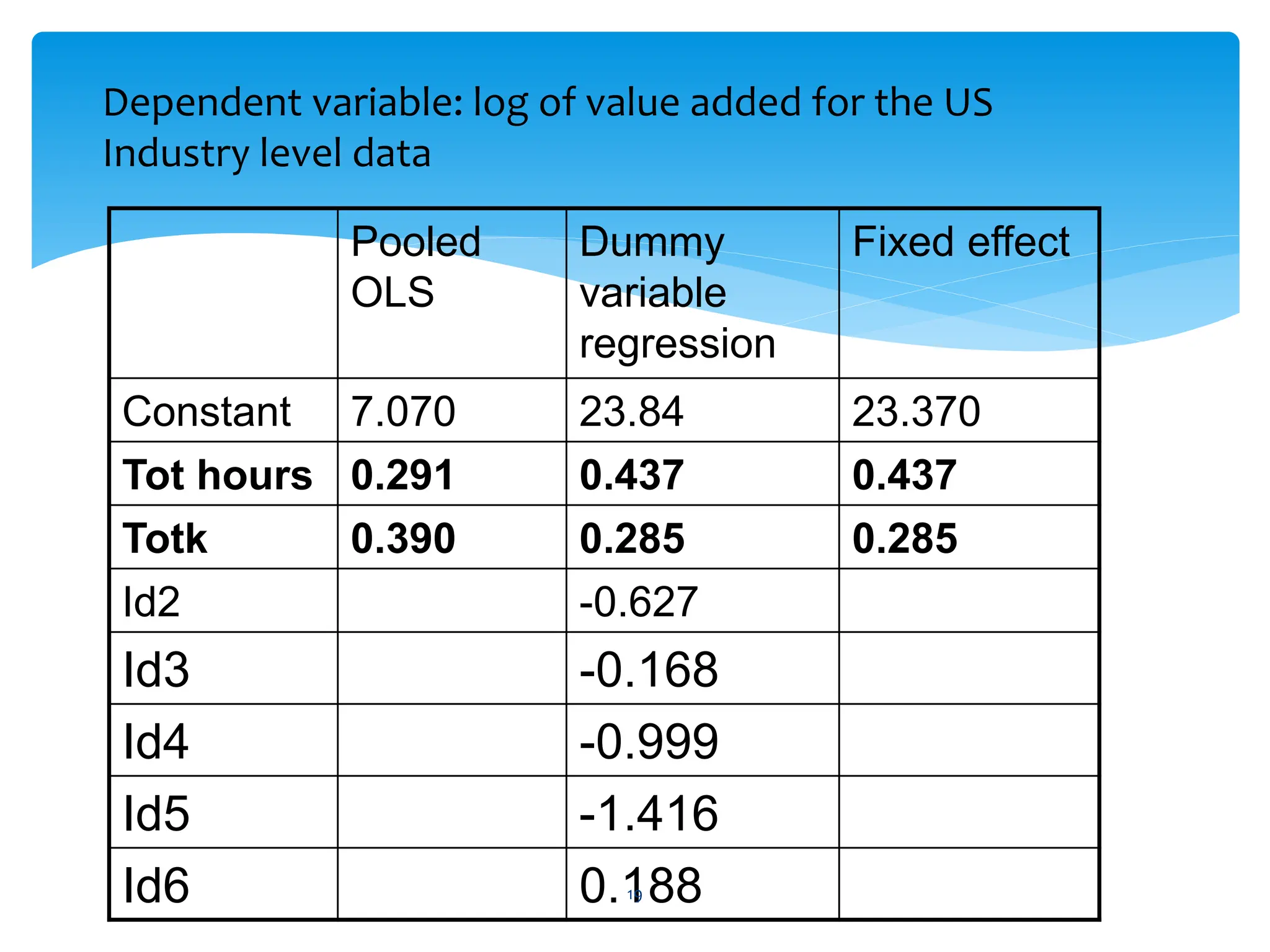















![ restrict the slope coefficients to be constant over
both units and time, and allow for an intercept
coefficient that varies by unit or by time. For a given
observation, an intercept varying over units
There are two interpretations of ai in this context: as a
parameter to be estimated in the model (a so-called
fixed effect) or alternatively, as a component of the
disturbance process, giving rise to a composite error
term [ai + vit ]: a so-called random effect. Under either
interpretation, ai is taken as a random variable.
36
Fixed effect estimator](https://image.slidesharecdn.com/advancedeconometricsl7-8-240128103146-a6bb73e6/75/Advanced-Econometrics-L7-8-pptx-36-2048.jpg)


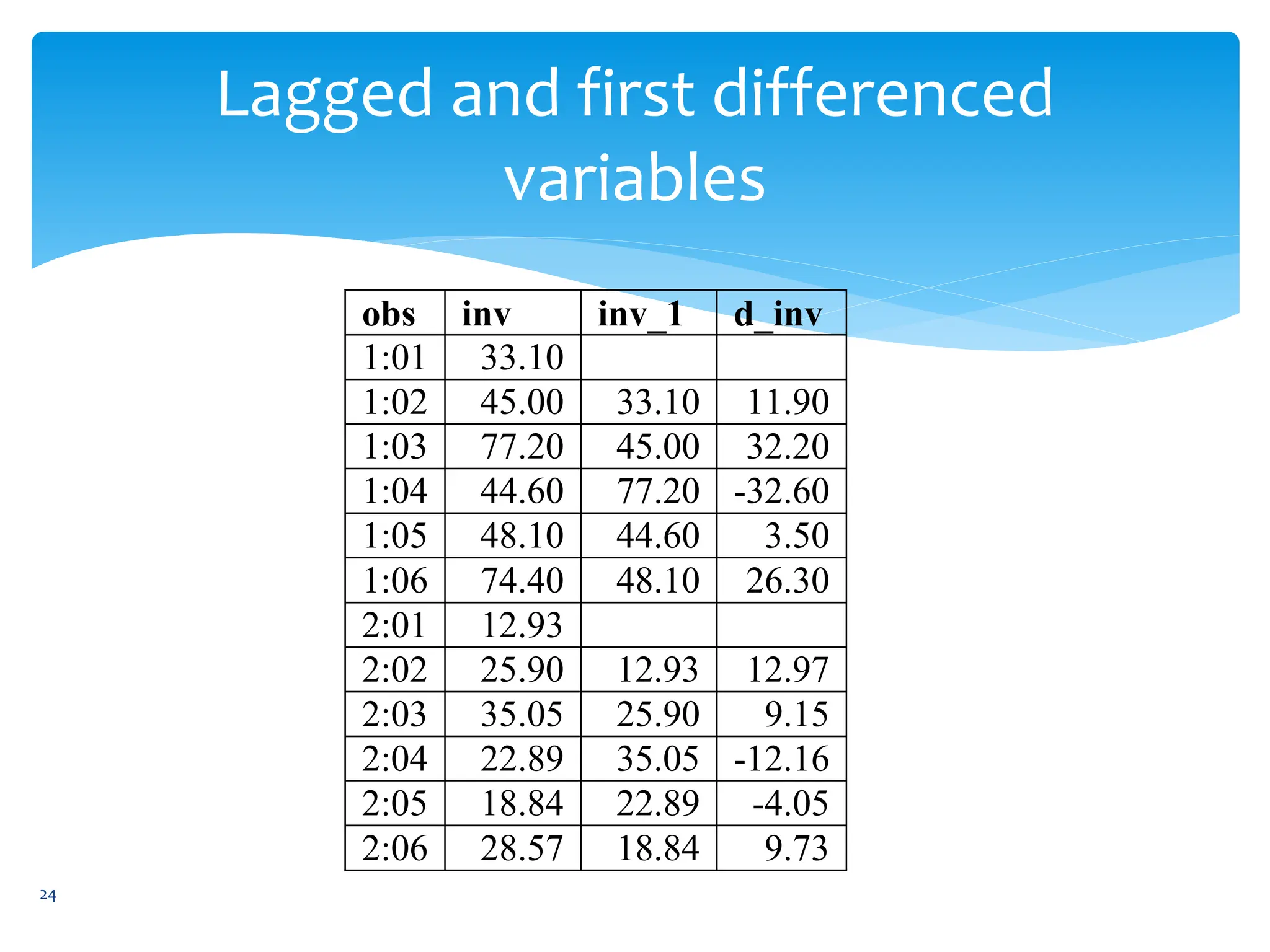
![ xtreg depvar indepvars, fe [options]
Use traffice data
In this example, we have 1982–1988 state-level data for 48
U.S. states on traffic fatality rates (deaths per 100,000).
We model the highway fatality rates as a function of
several common factors: beertax, the tax on a case of beer,
spircons, a measure of spirits consumption and two
economic factors: the state unemployment rate (unrate)
andstate per capita personal income, $000 (perincK). We
present descriptive statistics for these variables of the
traffic.dta dataset.
39
Fixed effect estimator](https://image.slidesharecdn.com/advancedeconometricsl7-8-240128103146-a6bb73e6/75/Advanced-Econometrics-L7-8-pptx-39-2048.jpg)













































































