Downloaded 632 times




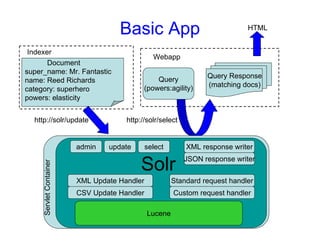
















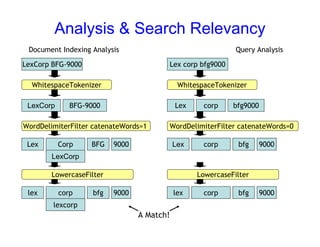



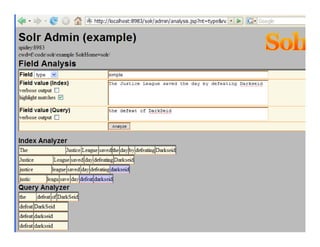




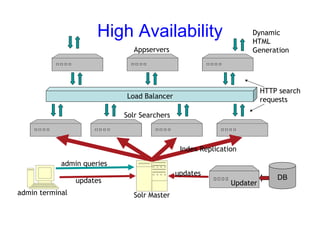


This document provides an overview of Solr, an open source enterprise search platform. It describes Solr's core functions like indexing, searching, and analyzing documents. It also explains how to configure Solr for indexing, querying, highlighting search results, and more. Various Solr query syntax and relevancy tuning options are demonstrated through examples.




















![Introduction to MySQL Query Tuning for Dev[Op]s](https://cdn.slidesharecdn.com/ss_thumbnails/qtdevops-191005204425-thumbnail.jpg?width=640&height=640&fit=bounds)


































































