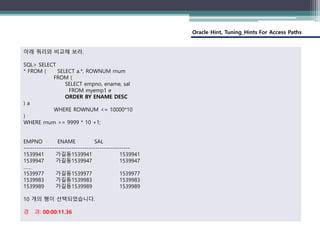
INDEX 힌트는 테이블의 칼럼에 대해 생성되어 있는 인덱스를 사용할 수 있도록 해주는 힌트 구문으로 비트맵 인덱스에 대해서도 사용이 가능하지만 Bitmap Index는 INDEX_COMBINE 사용하는 것이 원칙이다.
인덱스 영역에서 인덱스가 생성된 형태대로 순방향 스캐닝 하므로 INDEX_ASC와 동일하다.
대량의 데이터라면 ORDER BY의 사용을 자제하고 인덱스를 적절히 이용하자.
Oracle Hint, Tuning_HintsFor Access Paths
6.4 Hints for Access Paths
(Index, Index_Combine)
• INDEX 힌트는 테이블의 칼럼에 대해 생성되어 있는 인덱스를 사용할 수 있도록
해주는 힌트 구문으로 비트맵 인덱스에 대해서도 사용이 가능하지만 Bitmap
Index는 INDEX_COMBINE 사용하는 것이 원칙이다.
• 인덱스 영역에서 인덱스가 생성된 형태대로 순방향 스캐닝 하므로 INDEX_ASC와
동일하다.
• 대량의 데이터라면 ORDER BY의 사용을 자제하고 인덱스를 적절히 이용하자.
/*+ INDEX(테이블명 [인덱스명 [인덱스명] … ]) */
[형식]
3.
Oracle Hint, Tuning_HintsFor Access Paths
6.4 Hints for Access Paths
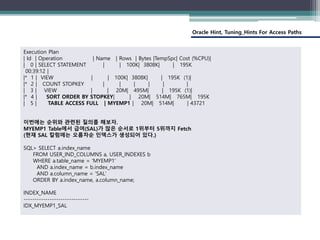
(Index_ASC)
• INDEX 힌트와 동일한데 인덱스가 생성된 형태대로 인덱스를 스캔하라는 의미의
힌트이다. 이 힌트를 이용하여 데이터를 추출하게 되면 화면에 나타나는
데이터는 인덱스를 생성한 순서대로 데이터가 추출된다.
• 인덱스 영역에서 인덱스가 생성된 형태대로 순방향 스캐닝 하므로 INDEX 힌트와
동일하다.
/*+ INDEX_ASC(테이블명 [인덱스명 [인덱스명] … ]) */
[형식]
4.
Oracle Hint, Tuning_HintsFor Access Paths
6.4 Hints for Access Paths
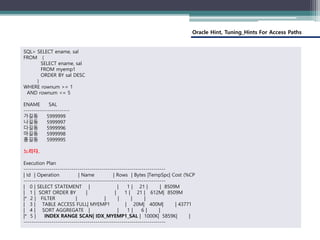
(Index_DESC)
• INDEX, INDEX_ASC 힌트의 반대로 인덱스 영역에서 생성된 인덱스의 역순으로
스캐닝하라는 의미로 데이터 값을 역순 정렬하라는 의미는 아니다. 인덱스가
내림차순으로 생성되었을 때 이 힌트를 사용한다면 데이터 값은 오름차순으로
나타나게 된다.
/*+ INDEX_DESC(테이블명 [인덱스명 [인덱스명] … ]) */
[형식]
5.
Oracle Hint, Tuning_HintsFor Access Paths
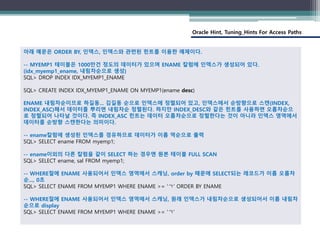
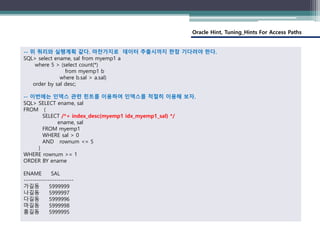
아래 예문은 ORDER BY, 인덱스, 인덱스와 관련된 힌트를 이용한 예제이다.
-- MYEMP1 테이블은 1000만건 정도의 데이터가 있으며 ENAME 칼럼에 인덱스가 생성되어 있다.
(idx_myemp1_ename, 내림차순으로 생성)
SQL> DROP INDEX IDX_MYEMP1_ENAME
SQL> CREATE INDEX IDX_MYEMP1_ENAME ON MYEMP1(ename desc)
ENAME 내림차순이므로 하길동... 김길동 순으로 인덱스에 정렬되어 있고, 인덱스에서 순방향으로 스캔(INDEX,
INDEX_ASC)해서 데이터를 뿌리면 내림차순 정렬된다. 하지만 INDEX_DESC와 같은 힌트를 사용하면 오름차순으
로 정렬되어 나타날 것이다. 즉 INDEX_ASC 힌트는 데이터 오름차순으로 정렬한다는 것이 아니라 인덱스 영역에서
데이터를 순방향 스캔한다는 의미이다.
-- ename칼럼에 생성된 인덱스를 경유하므로 데이터가 이름 역순으로 출력
SQL> SELECT ename FROM myemp1;
-- ename이외의 다른 칼럼을 같이 SELECT 하는 경우엔 원본 테이블 FULL SCAN
SQL> SELECT ename, sal FROM myemp1;
-- WHERE절에 ENAME 사용되어서 인덱스 영역에서 스캐닝, order by 때문에 SELECT되는 레코드가 이름 오름차
순..., 0초
SQL> SELECT ENAME FROM MYEMP1 WHERE ENAME >= 'ㄱ' ORDER BY ENAME
-- WHERE절에 ENAME 사용되어서 인덱스 영역에서 스캐닝, 원래 인덱스가 내림차순으로 생성되어서 이름 내림차
순으로 display
SQL> SELECT ENAME FROM MYEMP1 WHERE ENAME >= 'ㄱ'
6.
Oracle Hint, Tuning_HintsFor Access Paths
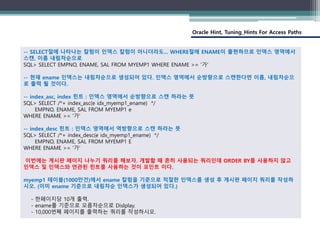
-- SELECT절에 나타나는 칼럼이 인덱스 칼럼이 아니더라도... WHERE절에 ENAME이 출현하므로 인덱스 영역에서
스캔, 이름 내림차순으로
SQL> SELECT EMPNO, ENAME, SAL FROM MYEMP1 WHERE ENAME >= '가'
-- 현재 ename 인덱스는 내림차순으로 생성되어 있다. 인덱스 영역에서 순방향으로 스캔한다면 이름, 내림차순으
로 출력 될 것이다.
-- index_asc, index 힌트 : 인덱스 영역에서 순방향으로 스캔 하라는 뜻
SQL> SELECT /*+ index_asc(e idx_myemp1_ename) */
EMPNO, ENAME, SAL FROM MYEMP1 e
WHERE ENAME >= '가'
-- index_desc 힌트 : 인덱스 영역에서 역방향으로 스캔 하라는 뜻
SQL> SELECT /*+ index_desc(e idx_myemp1_ename) */
EMPNO, ENAME, SAL FROM MYEMP1 E
WHERE ENAME >= '가'
이번에는 게시판 페이지 나누기 쿼리를 해보자. 개발할 때 흔히 사용되는 쿼리인데 ORDER BY를 사용하지 않고
인덱스 및 인덱스와 연관된 힌트를 사용하는 것이 포인트 이다.
myemp1 테이블(1000만건)에서 ename 칼럼을 기준으로 적절한 인덱스를 생성 후 게시판 페이지 쿼리를 작성하
시오. (이미 ename 기준으로 내림차순 인덱스가 생성되어 있다.)
- 한페이지당 10개 출력.
- ename를 기준으로 오름차순으로 Dislplay.
- 10,000번째 페이지를 출력하는 쿼리를 작성하시오.
7.
Oracle Hint, Tuning_HintsFor Access Paths
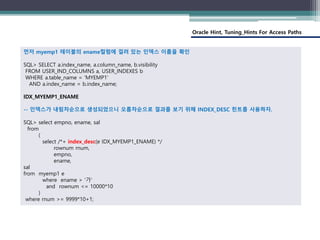
먼저 myemp1 테이블의 ename컬럼에 걸려 있는 인덱스 이름을 확인
SQL> SELECT a.index_name, a.column_name, b.visibility
FROM USER_IND_COLUMNS a, USER_INDEXES b
WHERE a.table_name = 'MYEMP1'
AND a.index_name = b.index_name;
IDX_MYEMP1_ENAME
-- 인덱스가 내림차순으로 생성되었으니 오름차순으로 결과를 보기 위해 INDEX_DESC 힌트를 사용하자.
SQL> select empno, ename, sal
from
(
select /*+ index_desc(e IDX_MYEMP1_ENAME) */
rownum rnum,
empno,
ename,
sal
from myemp1 e
where ename > ‘가’
and rownum <= 10000*10
)
where rnum >= 9999*10+1;
Oracle Hint, Tuning_HintsFor Access Paths
아래 쿼리와 비교해 보라.
SQL> SELECT
* FROM ( SELECT a.*, ROWNUM rnum
FROM (
SELECT empno, ename, sal
FROM myemp1 e
ORDER BY ENAME DESC
) a
WHERE ROWNUM <= 10000*10
)
WHERE rnum >= 9999 * 10 +1;
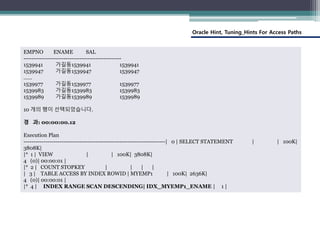
EMPNO ENAME SAL
-------------------------------------------------
1539941 가길동1539941 1539941
1539947 가길동1539947 1539947
……
1539977 가길동1539977 1539977
1539983 가길동1539983 1539983
1539989 가길동1539989 1539989
10 개의 행이 선택되었습니다.
경 과: 00:00:11.36
10.
Oracle Hint, Tuning_HintsFor Access Paths
Execution Plan
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)|
| 0 | SELECT STATEMENT | | 100K| 3808K| | 195K
00:39:12 |
|* 1 | VIEW | | 100K| 3808K| | 195K (1)|
|* 2 | COUNT STOPKEY | | | | | |
| 3 | VIEW | | 20M| 495M| | 195K (1)|
|* 4 | SORT ORDER BY STOPKEY| | 20M| 514M| 765M| 195K
| 5 | TABLE ACCESS FULL | MYEMP1 | 20M| 514M| | 43721
이번에는 순위와 관련된 질의를 해보자.
MYEMP1 Table에서 급여(SAL)가 많은 순서로 1위부터 5위까지 Fetch
(현재 SAL 칼럼에는 오름차순 인덱스가 생성되어 있다.)
SQL> SELECT a.index_name
FROM USER_IND_COLUMNS a, USER_INDEXES b
WHERE a.table_name = 'MYEMP1'
AND a.index_name = b.index_name
AND a.column_name = 'SAL'
ORDER BY a.index_name, a.column_name;
INDEX_NAME
------------------------------
IDX_MYEMP1_SAL
11.
Oracle Hint, Tuning_HintsFor Access Paths
SQL> SELECT ename, sal
FROM (
SELECT ename, sal
FROM myemp1
ORDER BY sal DESC
)
WHERE rownum >= 1
AND rownum <= 5
ENAME SAL
-----------------------
가길동 5999999
나길동 5999997
다길동 5999996
마길동 5999998
홍길동 5999995
느리다.
Execution Plan
-----------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CP
-----------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 21 | | 8509M
| 1 | SORT ORDER BY | | 1 | 21 | 612M| 8509M
|* 2 | FILTER | | | | |
| 3 | TABLE ACCESS FULL| MYEMP1 | 20M| 400M| | 43771
| 4 | SORT AGGREGATE | | 1 | 6 | |
|* 5 | INDEX RANGE SCAN| IDX_MYEMP1_SAL | 1000K| 5859K| |
-----------------------------------------------------------------------
12.
Oracle Hint, Tuning_HintsFor Access Paths
-- 위 쿼리와 실행계획 같다. 마찬가지로 데이터 추출시까지 한참 기다려야 한다.
SQL> select ename, sal from myemp1 a
where 5 > (select count(*)
from myemp1 b
where b.sal > a.sal)
order by sal desc;
-- 이번에는 인덱스 관련 힌트를 이용하여 인덱스를 적절히 이용해 보자.
SQL> SELECT ename, sal
FROM (
SELECT /*+ index_desc(myemp1 idx_myemp1_sal) */
ename, sal
FROM myemp1
WHERE sal > 0
AND rownum <= 5
)
WHERE rownum >= 1
ORDER BY ename
ENAME SAL
-----------------------
가길동 5999999
나길동 5999997
다길동 5999996
마길동 5999998
홍길동 5999995
13.
Oracle Hint, Tuning_HintsFor Access Paths
Execution Plan
-----------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%
-----------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 4 | 84 | 7
|* 1 | COUNT STOPKEY | | | |
| 2 | TABLE ACCESS BY INDEX ROWID | MYEMP1 | 4 | 84 |
|* 3 | INDEX RANGE SCAN DESCENDING| IDX_MYEMP1_SAL | 19M| |
-----------------------------------------------------------------------
-- 분포도가 좋지않은 컬럼(B*Tree인덱스)의 count연산시 index fast full scan과 index range scan의 성능 차이
비교
비트리 인덱스인 경우 분포도가 좋지 않은 컬럼을 count하는 경우라면 index fast full scan보다 index range scan
이 좋을 것 같다.
myemp1 테이블의 성별(sungbyul) 칼럼은 'M' or 'F' 값을 가지며 값의 분포도는 50%이다.
SQL> desc myemp1
이름 널 유형
-------- -------- -------------
EMPNO NOT NULL NUMBER
ENAME VARCHAR2(100)
DEPTNO VARCHAR2(1)
ADDR VARCHAR2(100)
SAL NUMBER
SUNGBYUL VARCHAR2(1)
14.
Oracle Hint, Tuning_HintsFor Access Paths
-- 비트리 인덱스를 만들자.
SQL> create index idx_myemp1_sungbyul on myemp1(SUNGBYUL)
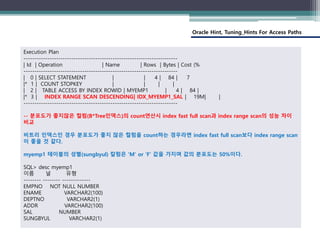
1. CBO MODE에서 COUNT를 하면 기본적으로 index fast full 스캔을 한다.
(수행시간 : 2초)
SQL> alter session set optimizer_mode = all_rows;
SQL> select count(*) from myemp1 where sungbyul = 'M';
COUNT(*)
----------
12000000
경 과: 00:00:02.03
Execution Plan
----------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU
----------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 2 | 9995 (2
| 1 | SORT AGGREGATE | | 1 | 2 |
|* 2 | INDEX FAST FULL SCAN| IDX_MYEMP1_SUNGBYUL | 10M| 19M| 9995 (2
--------------------------------------------------------------------------------
15.
Oracle Hint, Tuning_HintsFor Access Paths
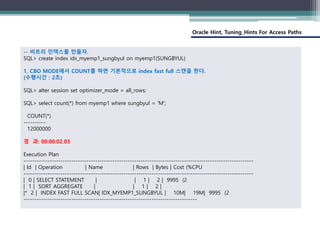
2. RBO MODE에서 COUNT를 하면 기본적으로 index range 스캔을 한다.
(수행시간 : 0초)
SQL> alter session set optimizer_mode = rule;
SQL> select count(*) from myemp1 where sungbyul = 'M';
COUNT(*)
----------
12000000
경 과: 00:00:00.70
Execution Plan
-------------------------------------------------
| Id | Operation | Name |
-------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | SORT AGGREGATE | |
|* 2 | INDEX RANGE SCAN| IDX_MYEMP1_SUNGBYUL |
--------------------------------------------
16.
Oracle Hint, Tuning_HintsFor Access Paths
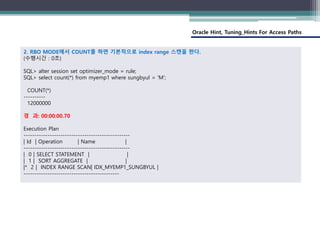
3. 아래처럼 CBO 모드라면 index 힌트를 사용해도 된다.
SQL> select /*+ index(myemp1 idx_myemp1_sungbyul) */ count(*) from myemp1 where sungbyul = 'M';
COUNT(*)
----------
10000002
경 과: 00:00:00.75
Execution Plan
----------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 1 | 18223 (1)| 0
| 1 | SORT AGGREGATE | | 1 | 1 | |
|* 2 | INDEX RANGE SCAN| IDX_MYEMP1_SUNGBYUL | 10M| 9765K| 18223 (1)| 0


![Oracle Hint, Tuning_Hints For Access Paths
6.4 Hints for Access Paths
(Index, Index_Combine)
• INDEX 힌트는 테이블의 칼럼에 대해 생성되어 있는 인덱스를 사용할 수 있도록
해주는 힌트 구문으로 비트맵 인덱스에 대해서도 사용이 가능하지만 Bitmap
Index는 INDEX_COMBINE 사용하는 것이 원칙이다.
• 인덱스 영역에서 인덱스가 생성된 형태대로 순방향 스캐닝 하므로 INDEX_ASC와
동일하다.
• 대량의 데이터라면 ORDER BY의 사용을 자제하고 인덱스를 적절히 이용하자.
/*+ INDEX(테이블명 [인덱스명 [인덱스명] … ]) */
[형식]](https://image.slidesharecdn.com/6-170616130258/85/6-4-hints-for-access-paths-index-2-320.jpg)
![Oracle Hint, Tuning_Hints For Access Paths
6.4 Hints for Access Paths
(Index_ASC)
• INDEX 힌트와 동일한데 인덱스가 생성된 형태대로 인덱스를 스캔하라는 의미의
힌트이다. 이 힌트를 이용하여 데이터를 추출하게 되면 화면에 나타나는
데이터는 인덱스를 생성한 순서대로 데이터가 추출된다.
• 인덱스 영역에서 인덱스가 생성된 형태대로 순방향 스캐닝 하므로 INDEX 힌트와
동일하다.
/*+ INDEX_ASC(테이블명 [인덱스명 [인덱스명] … ]) */
[형식]](https://image.slidesharecdn.com/6-170616130258/85/6-4-hints-for-access-paths-index-3-320.jpg)
![Oracle Hint, Tuning_Hints For Access Paths
6.4 Hints for Access Paths
(Index_DESC)
• INDEX, INDEX_ASC 힌트의 반대로 인덱스 영역에서 생성된 인덱스의 역순으로
스캐닝하라는 의미로 데이터 값을 역순 정렬하라는 의미는 아니다. 인덱스가
내림차순으로 생성되었을 때 이 힌트를 사용한다면 데이터 값은 오름차순으로
나타나게 된다.
/*+ INDEX_DESC(테이블명 [인덱스명 [인덱스명] … ]) */
[형식]](https://image.slidesharecdn.com/6-170616130258/85/6-4-hints-for-access-paths-index-4-320.jpg)


![[오라클교육/SQL교육/IT교육/실무중심교육학원추천_탑크리에듀]#4.SQL초보에서 Schema Objectes까지](https://cdn.slidesharecdn.com/ss_thumbnails/sqlschemaobjects4-170123085836-thumbnail.jpg?width=640&height=640&fit=bounds)



![[구로IT학원추천/구로디지털단지IT학원/국비지원IT학원/재직자/구직자환급교육]#9.SQL초보에서 Schema Objects까지](https://cdn.slidesharecdn.com/ss_thumbnails/sqlschemaobjects9-170126020830-thumbnail.jpg?width=640&height=640&fit=bounds)









![[오라클교육/닷넷교육/자바교육/SQL기초/스프링학원/국비지원학원/자마린교육]#16.SQL초보에서 Schema Objects까지](https://cdn.slidesharecdn.com/ss_thumbnails/sqlschemaobjects16-170203081623-thumbnail.jpg?width=640&height=640&fit=bounds)














![[2015-06-26] Oracle 성능 최적화 및 품질 고도화 3](https://cdn.slidesharecdn.com/ss_thumbnails/2015-06-26oracle3-150623063728-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)












![[2015-06-19] Oracle 성능 최적화 및 품질 고도화 2](https://cdn.slidesharecdn.com/ss_thumbnails/2015-06-19oracle2-150618090026-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)


![[제3회 스포카콘] SQL 쿼리 최적화 맛보기](https://cdn.slidesharecdn.com/ss_thumbnails/spoqacon2021keynotejhuni-210222015014-thumbnail.jpg?width=640&height=640&fit=bounds)




![[IT교육/IT학원]Develope를 위한 IT실무교육](https://cdn.slidesharecdn.com/ss_thumbnails/random-180126054238-thumbnail.jpg?width=640&height=640&fit=bounds)
![[아이오닉학원]아이오닉 하이브리드 앱 개발 과정(아이오닉2로 동적 모바일 앱 만들기)](https://cdn.slidesharecdn.com/ss_thumbnails/2-180116062601-thumbnail.jpg?width=640&height=640&fit=bounds)
![[뷰제이에스학원]뷰제이에스(Vue.js) 프로그래밍 입문(프로그레시브 자바스크립트 프레임워크)](https://cdn.slidesharecdn.com/ss_thumbnails/vue-180116043929-thumbnail.jpg?width=640&height=640&fit=bounds)
![[씨샵학원/씨샵교육]C#, 윈폼, 네트워크, ado.net 실무프로젝트 과정](https://cdn.slidesharecdn.com/ss_thumbnails/cado-180116013552-thumbnail.jpg?width=640&height=640&fit=bounds)
![[정보처리기사자격증학원]정보처리기사 취득 양성과정(국비무료 자격증과정)](https://cdn.slidesharecdn.com/ss_thumbnails/random-180116010303-thumbnail.jpg?width=640&height=640&fit=bounds)
![[wpf학원,wpf교육]닷넷, c#기반 wpf 프로그래밍 인터페이스구현 재직자 향상과정](https://cdn.slidesharecdn.com/ss_thumbnails/11-180102064615-thumbnail.jpg?width=640&height=640&fit=bounds)

![[자마린교육/자마린실습]자바,스프링프레임워크(스프링부트) RESTful 웹서비스 구현 실습,자마린에서 스프링 웹서비스를 호출하고 응답 JS...](https://cdn.slidesharecdn.com/ss_thumbnails/restfuljson-171119094451-thumbnail.jpg?width=640&height=640&fit=bounds)
![[구로자마린학원/자마린강좌/자마린교육]3. xamarin.ios 3.3.5 추가적인 사항](https://cdn.slidesharecdn.com/ss_thumbnails/3-171109005415-thumbnail.jpg?width=640&height=640&fit=bounds)





![자바, 웹 기초와 스프링 프레임워크 & 마이바티스 재직자 향상과정(자바학원/자바교육/자바기업출강]](https://cdn.slidesharecdn.com/ss_thumbnails/01-171017011030-thumbnail.jpg?width=640&height=640&fit=bounds)

![3. 안드로이드 애플리케이션 구성요소 3.2인텐트 part01(안드로이드학원/안드로이드교육/안드로이드강좌/안드로이드기업출강]](https://cdn.slidesharecdn.com/ss_thumbnails/3-171010074659-thumbnail.jpg?width=640&height=640&fit=bounds)