Download to read offline
![SQL초보에서 Schema Objects까지
11. 인덱스(INDEX)
테이블의 칼럼에 대해 생성되는 객체로 별도의 영역(테이블스페이스)에 칼럼값들을 정렬한 후
생성한다. 데이터 검색 속도를 향상 시키기 위해 사용되며, 포인터를 이용하여 데이터를 램덤
액세스 한다.
한번 생성되면 오라클에 의해 내부적으로 자동 관리된다.
오라클에서 Create Index로 인덱스를 생성하면 B*Tree(balanced Tree) 인덱스가 생성되며 어떠
한 행을 접근하든지 액세스 타임이 동일한다.
WHERE절 or 조인절에 빈번히 출현되는 칼럼의 경우 대부분 인덱스가 필요하다.
칼럼값의 분포도가 10%~15% 인 경우 인덱스가 효율적이다.
삽입, 삭제가 빈번한 테이블에는 인덱스의 사용을 자제해야 한다.
[형식]
CREATE [UNIQUE] INDEX index_name
ON table_name (Column|Expr[,Column|Expr]...);
11.1 단일/복합(결합) 인덱스(Single Column/Composite Index)](https://image.slidesharecdn.com/sqlschemaobjects25-170213084908/85/25-SQL-Schema-Objects-_-IT-IT-IT-1-320.jpg)
![SQL초보에서 Schema Objects까지
11. 인덱스(INDEX)
테이블의 칼럼에 대해 생성되는 객체로 별도의 영역(테이블스페이스)에 칼럼값들을 정렬한 후
생성한다. 데이터 검색 속도를 향상 시키기 위해 사용되며, 포인터를 이용하여 데이터를 램덤
액세스 한다.
한번 생성되면 오라클에 의해 내부적으로 자동 관리된다.
오라클에서 Create Index로 인덱스를 생성하면 B*Tree(balanced Tree) 인덱스가 생성되며 어떠
한 행을 접근하든지 액세스 타임이 동일한다.
WHERE절 or 조인절에 빈번히 출현되는 칼럼의 경우 대부분 인덱스가 필요하다.
칼럼값의 분포도가 10%~15% 인 경우 인덱스가 효율적이다.
삽입, 삭제가 빈번한 테이블에는 인덱스의 사용을 자제해야 한다.
[형식]
CREATE [UNIQUE] INDEX index_name
ON table_name (Column|Expr[,Column|Expr]...);
11.1 단일/복합(결합) 인덱스(Single Column/Composite Index)](https://image.slidesharecdn.com/sqlschemaobjects25-170213084908/75/25-SQL-Schema-Objects-_-IT-IT-IT-1-2048.jpg)





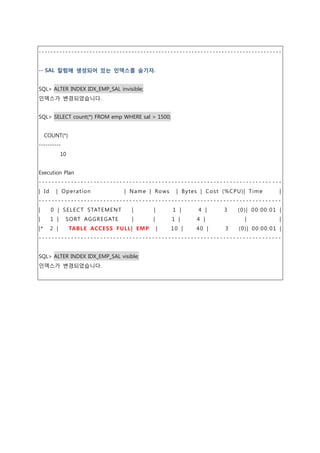

탑크리에듀교육센터(topcredu.co.kr)에서 제공하는 자료입니다. SQL초보에서 Schema Objects까지 25번째 자료입니다. 단일/복합(결합) 인덱스(Single Column/Composite Index),고유/비고유 인덱스(Unique/Non Unique Index), Descending Index, 함수기반 인덱스(Function Based Index), 인덱스 재구성 및 삭제, 인덱스 숨기기(Index Invisible)에 대하여 설명한 자료이오니 확인 후 많은 도움 되셨길 바랍니다^^.














![[오라클교육/SQL교육/IT교육/실무중심교육학원추천_탑크리에듀]#4.SQL초보에서 Schema Objectes까지](https://cdn.slidesharecdn.com/ss_thumbnails/sqlschemaobjects4-170123085836-thumbnail.jpg?width=640&height=640&fit=bounds)








![[구로IT학원추천/구로디지털단지IT학원/국비지원IT학원/재직자/구직자환급교육]#9.SQL초보에서 Schema Objects까지](https://cdn.slidesharecdn.com/ss_thumbnails/sqlschemaobjects9-170126020830-thumbnail.jpg?width=640&height=640&fit=bounds)













![[오라클교육/닷넷교육/자바교육/SQL기초/스프링학원/국비지원학원/자마린교육]#16.SQL초보에서 Schema Objects까지](https://cdn.slidesharecdn.com/ss_thumbnails/sqlschemaobjects16-170203081623-thumbnail.jpg?width=640&height=640&fit=bounds)




![[2015-06-26] Oracle 성능 최적화 및 품질 고도화 3](https://cdn.slidesharecdn.com/ss_thumbnails/2015-06-26oracle3-150623063728-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)










![[제3회 스포카콘] SQL 쿼리 최적화 맛보기](https://cdn.slidesharecdn.com/ss_thumbnails/spoqacon2021keynotejhuni-210222015014-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2015-06-19] Oracle 성능 최적화 및 품질 고도화 2](https://cdn.slidesharecdn.com/ss_thumbnails/2015-06-19oracle2-150618090026-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)










![[IT교육/IT학원]Develope를 위한 IT실무교육](https://cdn.slidesharecdn.com/ss_thumbnails/random-180126054238-thumbnail.jpg?width=640&height=640&fit=bounds)
![[아이오닉학원]아이오닉 하이브리드 앱 개발 과정(아이오닉2로 동적 모바일 앱 만들기)](https://cdn.slidesharecdn.com/ss_thumbnails/2-180116062601-thumbnail.jpg?width=640&height=640&fit=bounds)
![[뷰제이에스학원]뷰제이에스(Vue.js) 프로그래밍 입문(프로그레시브 자바스크립트 프레임워크)](https://cdn.slidesharecdn.com/ss_thumbnails/vue-180116043929-thumbnail.jpg?width=640&height=640&fit=bounds)
![[씨샵학원/씨샵교육]C#, 윈폼, 네트워크, ado.net 실무프로젝트 과정](https://cdn.slidesharecdn.com/ss_thumbnails/cado-180116013552-thumbnail.jpg?width=640&height=640&fit=bounds)
![[정보처리기사자격증학원]정보처리기사 취득 양성과정(국비무료 자격증과정)](https://cdn.slidesharecdn.com/ss_thumbnails/random-180116010303-thumbnail.jpg?width=640&height=640&fit=bounds)
![[wpf학원,wpf교육]닷넷, c#기반 wpf 프로그래밍 인터페이스구현 재직자 향상과정](https://cdn.slidesharecdn.com/ss_thumbnails/11-180102064615-thumbnail.jpg?width=640&height=640&fit=bounds)

![[자마린교육/자마린실습]자바,스프링프레임워크(스프링부트) RESTful 웹서비스 구현 실습,자마린에서 스프링 웹서비스를 호출하고 응답 JS...](https://cdn.slidesharecdn.com/ss_thumbnails/restfuljson-171119094451-thumbnail.jpg?width=640&height=640&fit=bounds)
![[구로자마린학원/자마린강좌/자마린교육]3. xamarin.ios 3.3.5 추가적인 사항](https://cdn.slidesharecdn.com/ss_thumbnails/3-171109005415-thumbnail.jpg?width=640&height=640&fit=bounds)




![자바, 웹 기초와 스프링 프레임워크 & 마이바티스 재직자 향상과정(자바학원/자바교육/자바기업출강]](https://cdn.slidesharecdn.com/ss_thumbnails/01-171017011030-thumbnail.jpg?width=640&height=640&fit=bounds)

![3. 안드로이드 애플리케이션 구성요소 3.2인텐트 part01(안드로이드학원/안드로이드교육/안드로이드강좌/안드로이드기업출강]](https://cdn.slidesharecdn.com/ss_thumbnails/3-171010074659-thumbnail.jpg?width=640&height=640&fit=bounds)
