- 1일차 :Tuning 도구
- D/B Tuning이 어려운 이유
- Oracle D/B 구조
- Tuning Tools : AutoTrace, SQL*Trace, V$SQLAREA
- 2일차 : SQL Tuning #1 : Optimizer
- Rule-based Optimizer
- Cost-based Optimizer
- 통계정보, Histogram
- Hint
- 3일차 : SQL Tuning #2 : Index, Join
- Index
- Join
- 4일차 : Server Tuning
- Shared pool tuning
- Data buffer cache tuning
* NoSQL 소개
3.
INDEX 설계 시주의사항
1. 조건에 만족하는 Data가 전체의 10% 내외일때 가장 이상적
2. 대용량 Data를 가진 Table에 적용
( 20 ~ 30만건 이상인 경우는 적극적 고려)
3. 분포도가 나쁘더라도 Fast Index Scan이 가능한 경우 효과적
4. 여러가지 Index 중 적합한 Index로 생성해야 함
5. Index가 생성되는 Tablespace와 물리적 크기에 대해 고려
(Extent, Block 크기)
4.
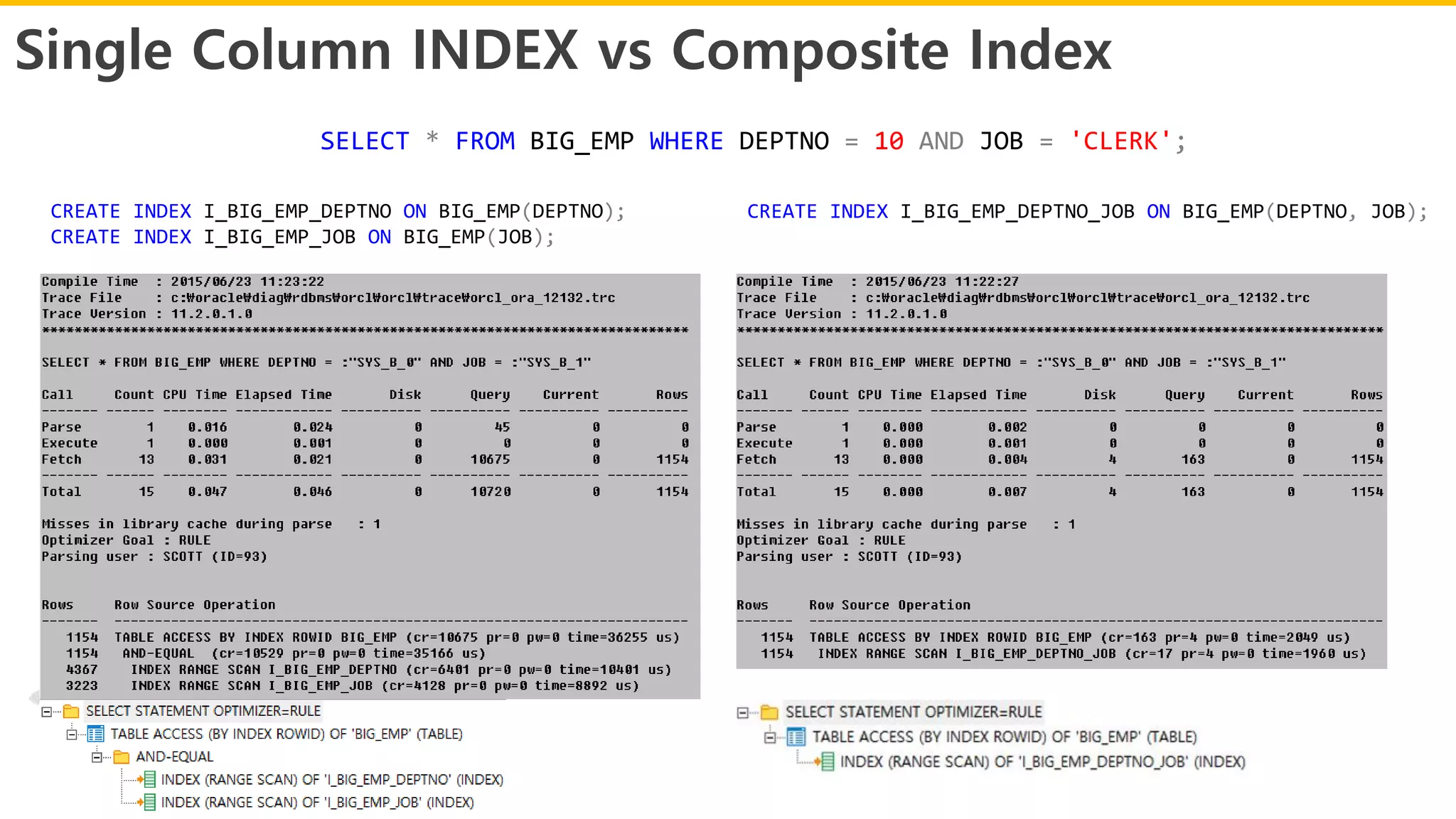
Single Column INDEXvs Composite Index
SELECT * FROM BIG_EMP WHERE DEPTNO = 10 AND JOB = 'CLERK';
CREATE INDEX I_BIG_EMP_DEPTNO ON BIG_EMP(DEPTNO);
CREATE INDEX I_BIG_EMP_JOB ON BIG_EMP(JOB);
CREATE INDEX I_BIG_EMP_DEPTNO_JOB ON BIG_EMP(DEPTNO, JOB);
5.
Composite INDEX 선행Column 결정 기준
1. WHERE 절에서 자주 검색될수록
2. 분포도가 좋을수록
3. Data가 적을수록
4. 범위검색 (BETWEEN, >, <, LIKE)로 검색되지 않을 수록
6.
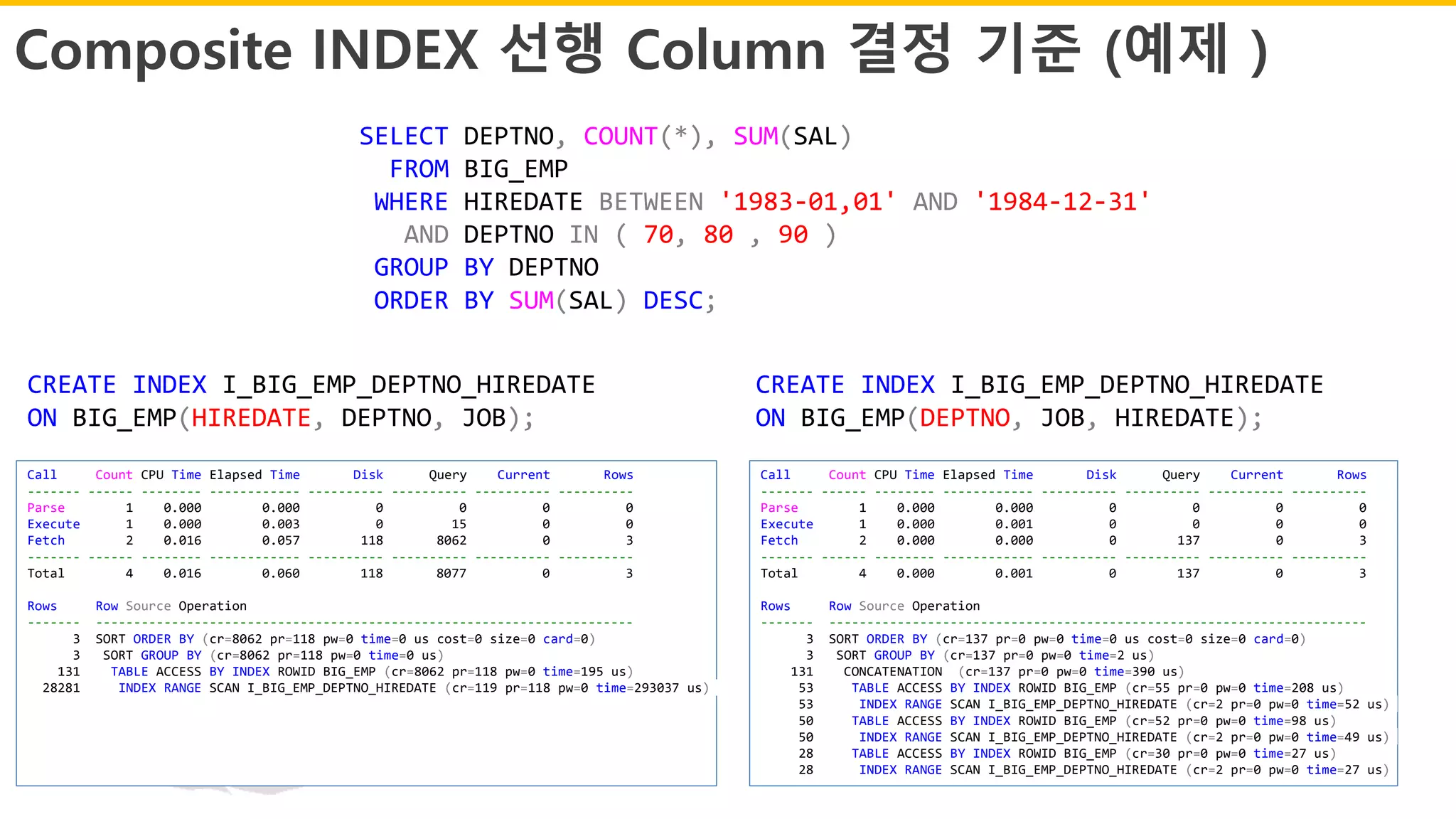
Composite INDEX 선행Column 결정 기준 (예제 )
CREATE INDEX I_BIG_EMP_DEPTNO_HIREDATE
ON BIG_EMP(DEPTNO, JOB, HIREDATE);
Call Count CPU Time Elapsed Time Disk Query Current Rows
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Parse 1 0.000 0.000 0 0 0 0
Execute 1 0.000 0.001 0 0 0 0
Fetch 2 0.000 0.000 0 137 0 3
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Total 4 0.000 0.001 0 137 0 3
Rows Row Source Operation
------- -----------------------------------------------------------------------
3 SORT ORDER BY (cr=137 pr=0 pw=0 time=0 us cost=0 size=0 card=0)
3 SORT GROUP BY (cr=137 pr=0 pw=0 time=2 us)
131 CONCATENATION (cr=137 pr=0 pw=0 time=390 us)
53 TABLE ACCESS BY INDEX ROWID BIG_EMP (cr=55 pr=0 pw=0 time=208 us)
53 INDEX RANGE SCAN I_BIG_EMP_DEPTNO_HIREDATE (cr=2 pr=0 pw=0 time=52 us)
50 TABLE ACCESS BY INDEX ROWID BIG_EMP (cr=52 pr=0 pw=0 time=98 us)
50 INDEX RANGE SCAN I_BIG_EMP_DEPTNO_HIREDATE (cr=2 pr=0 pw=0 time=49 us)
28 TABLE ACCESS BY INDEX ROWID BIG_EMP (cr=30 pr=0 pw=0 time=27 us)
28 INDEX RANGE SCAN I_BIG_EMP_DEPTNO_HIREDATE (cr=2 pr=0 pw=0 time=27 us)
Call Count CPU Time Elapsed Time Disk Query Current Rows
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Parse 1 0.000 0.000 0 0 0 0
Execute 1 0.000 0.003 0 15 0 0
Fetch 2 0.016 0.057 118 8062 0 3
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Total 4 0.016 0.060 118 8077 0 3
Rows Row Source Operation
------- -----------------------------------------------------------------------
3 SORT ORDER BY (cr=8062 pr=118 pw=0 time=0 us cost=0 size=0 card=0)
3 SORT GROUP BY (cr=8062 pr=118 pw=0 time=0 us)
131 TABLE ACCESS BY INDEX ROWID BIG_EMP (cr=8062 pr=118 pw=0 time=195 us)
28281 INDEX RANGE SCAN I_BIG_EMP_DEPTNO_HIREDATE (cr=119 pr=118 pw=0 time=293037 us)
CREATE INDEX I_BIG_EMP_DEPTNO_HIREDATE
ON BIG_EMP(HIREDATE, DEPTNO, JOB);
SELECT DEPTNO, COUNT(*), SUM(SAL)
FROM BIG_EMP
WHERE HIREDATE BETWEEN '1983-01,01' AND '1984-12-31'
AND DEPTNO IN ( 70, 80 , 90 )
GROUP BY DEPTNO
ORDER BY SUM(SAL) DESC;
7.
INDEX를 사용하지 못하는경우
1. Column을 함수로 변경
(SQL문을 적절히 바꾸던가… 아니면 Function-based Index를 사용하던가)
2. 부정문으로 비교 (<>, !=, ^=, NOT =, NOT BETWEEN, NOT LIKE)
( NOT EXISTS (SELECT 1 FROM … WHERE … ) 로 대체 가능 )
3. IS NULL, IS NOT NULL로 비교
(Index에 NULL값은 없다. 즉 모든 값이 NOT NULL)
(IN NOT NULL 대신 > ‘ ’ 이런식의 존재하는 한 무조건 만족하는 조건으로 검색을 할 수 있다.)
4. LIKE 연산자에서 %(와일드카드)가 앞에 있는 경우
8.
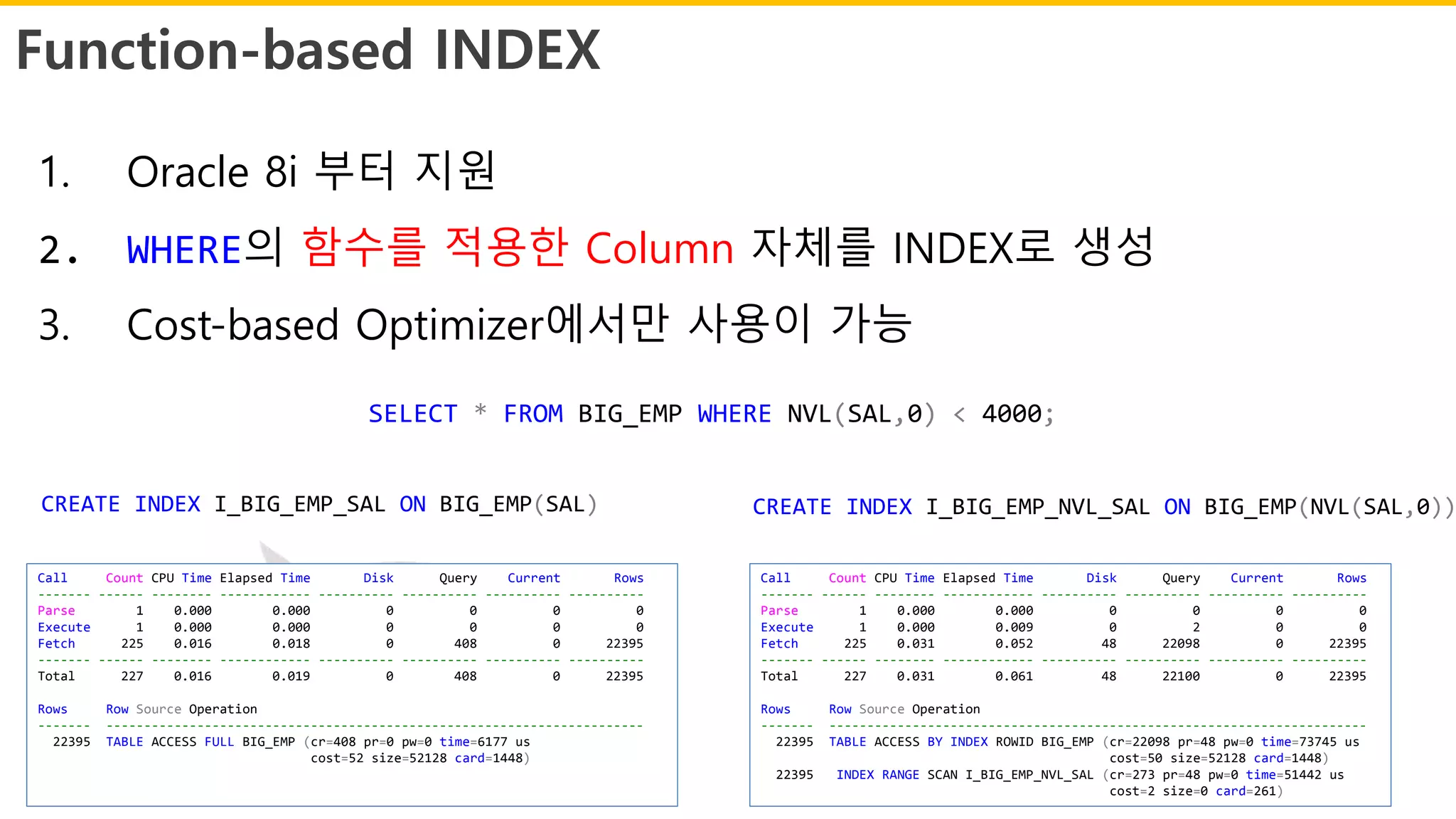
Function-based INDEX
1. Oracle8i 부터 지원
2. WHERE의 함수를 적용한 Column 자체를 INDEX로 생성
3. Cost-based Optimizer에서만 사용이 가능
SELECT * FROM BIG_EMP WHERE NVL(SAL,0) < 4000;
CREATE INDEX I_BIG_EMP_SAL ON BIG_EMP(SAL) CREATE INDEX I_BIG_EMP_NVL_SAL ON BIG_EMP(NVL(SAL,0))
Call Count CPU Time Elapsed Time Disk Query Current Rows
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Parse 1 0.000 0.000 0 0 0 0
Execute 1 0.000 0.000 0 0 0 0
Fetch 225 0.016 0.018 0 408 0 22395
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Total 227 0.016 0.019 0 408 0 22395
Rows Row Source Operation
------- -----------------------------------------------------------------------
22395 TABLE ACCESS FULL BIG_EMP (cr=408 pr=0 pw=0 time=6177 us
cost=52 size=52128 card=1448)
Call Count CPU Time Elapsed Time Disk Query Current Rows
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Parse 1 0.000 0.000 0 0 0 0
Execute 1 0.000 0.009 0 2 0 0
Fetch 225 0.031 0.052 48 22098 0 22395
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Total 227 0.031 0.061 48 22100 0 22395
Rows Row Source Operation
------- -----------------------------------------------------------------------
22395 TABLE ACCESS BY INDEX ROWID BIG_EMP (cr=22098 pr=48 pw=0 time=73745 us
cost=50 size=52128 card=1448)
22395 INDEX RANGE SCAN I_BIG_EMP_NVL_SAL (cr=273 pr=48 pw=0 time=51442 us
cost=2 size=0 card=261)
9.
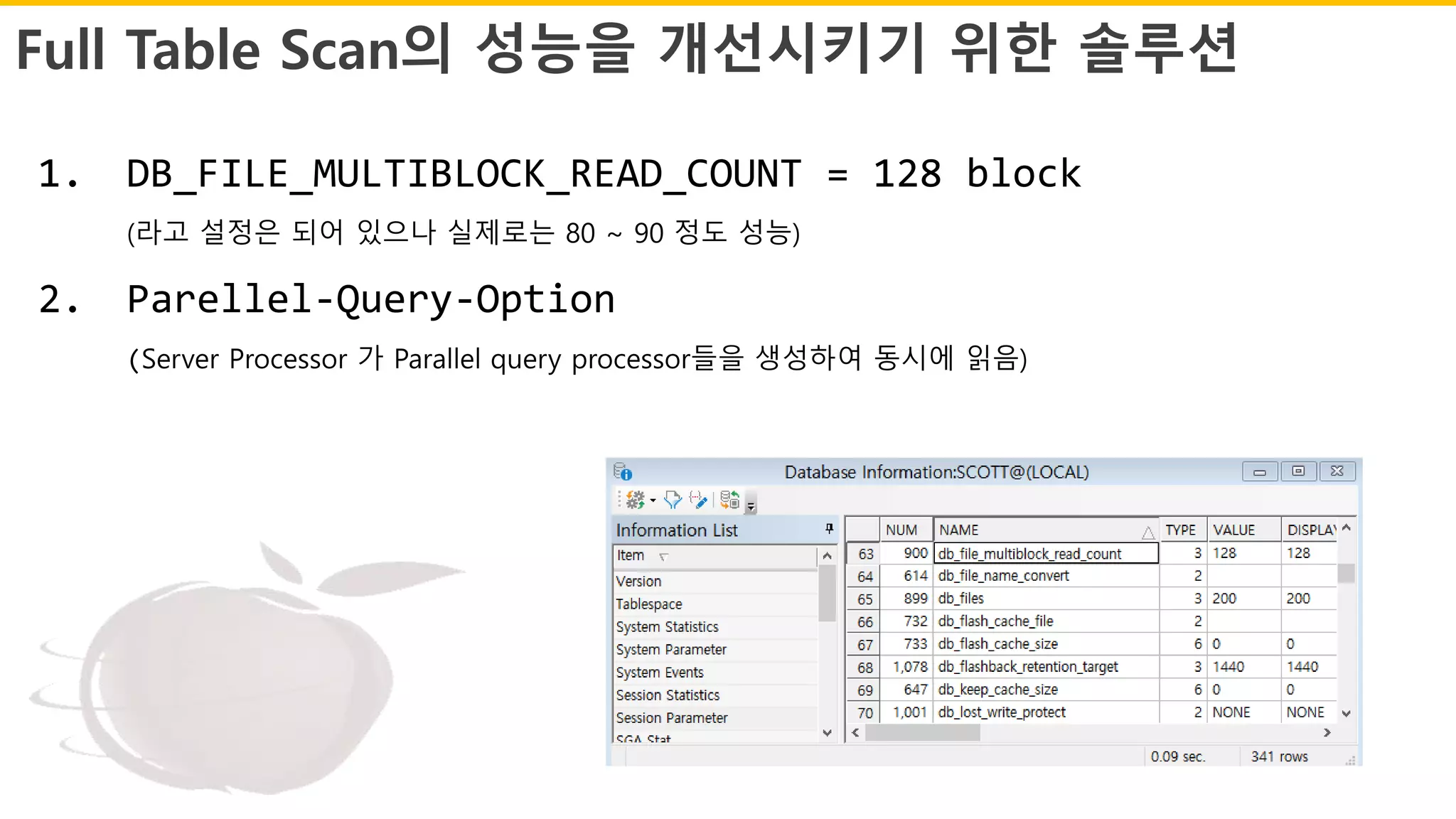
Full Table Scan의성능을 개선시키기 위한 솔루션
1. DB_FILE_MULTIBLOCK_READ_COUNT = 128 block
(라고 설정은 되어 있으나 실제로는 80 ~ 90 정도 성능)
2. Parellel-Query-Option
(Server Processor 가 Parallel query processor들을 생성하여 동시에 읽음)
10.
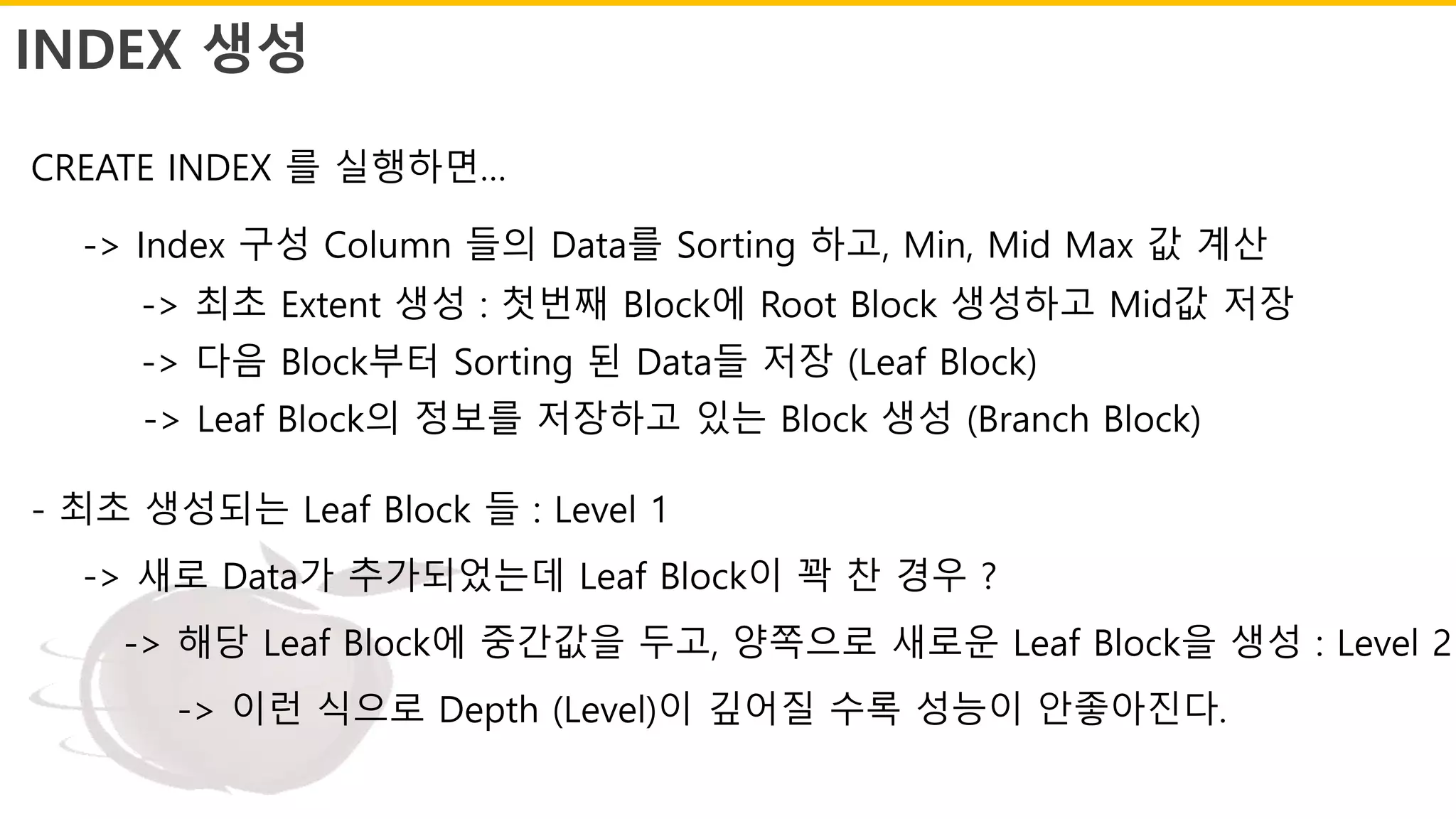
INDEX 생성
CREATE INDEX를 실행하면…
-> Index 구성 Column 들의 Data를 Sorting 하고, Min, Mid Max 값 계산
-> 최초 Extent 생성 : 첫번째 Block에 Root Block 생성하고 Mid값 저장
-> 다음 Block부터 Sorting 된 Data들 저장 (Leaf Block)
-> Leaf Block의 정보를 저장하고 있는 Block 생성 (Branch Block)
- 최초 생성되는 Leaf Block 들 : Level 1
-> 새로 Data가 추가되었는데 Leaf Block이 꽉 찬 경우 ?
-> 해당 Leaf Block에 중간값을 두고, 양쪽으로 새로운 Leaf Block을 생성 : Level 2
-> 이런 식으로 Depth (Level)이 깊어질 수록 성능이 안좋아진다.
11.
INDEX Balancing 분석
ANALYZEINDEX [index_name] VALIDATE STRUCTURE;
SELECT (DEL_LF_ROWS_LEN / LF_ROWS_LEN) * 100 AS BALANCING
FROM INDEX_STATS;
* INDEX_STATS
• INDEX 현재 구조 분석
• Block 수
• 삭제된 행의 길이
• INDEX DEPTH (HEIGHT)
12.
INDEX 재구성
ALTER INDEX[index_name] REBUILD [NOLOGGING]
TABLESPACE [tablespace_name];
• Balancing이 20% 초과하면 성능 저하가 심하므로 재구성 하는게 좋음 (사후조치)
(그럼 사전조치는 ? 물리적 설계 : 빈번한 DML 고려)
• INDEX 삭제 후 재 생성
• On-Line rebuild 가능 (DBMS_REDEFINITION Package)
• Tablespace 위치 변경도 가능
13.
INDEX 합병 (B*Tree)
ANALYZEINDEX [index_name] COALESCE;
SELECT INDEX_NAME, LEAF_BLOCKS
FROM USER_INDEXES;
SELECT NAME, BLOCKS, LF_BLKS, BR_BLKS
FROM INDEX_STATS;
• INDEX Key 값을 재 배치
• 불필요한 Block 검색 및 공간 낭비를 방지
• 하지만 빈 Node를 반환해주지는 않음
14.
INDEX 압축 (B*Tree,IOT)
SELECT INDEX_NAME, COMPRESSION
FROM USER_INDEXES;
• 디스크 공간 절약I/O를 줄일 수 있으므로 검색속도 향상
(하지만 Transaction이 조금만 증가해도 느려질 수 있다)
• 대용량 Data에 적용하면 효율적
• Non-Partitioned Index에만 적용 가능
CREATE INDEX [index_name] ON [table_name]([column_name,...]) [ COMPRESS | NOCOMPRESS ];
15.
INDEX Monitoring
• INDEX는SELECT의 성능을 올려주지만,
DML 들의 성능을 떨어트린다.
• Optimizer가 안 쓰는 INDEX는 과감히 삭제하자.
• 9i부터 가능
• 사용되지 않은 Index를 검색하여 삭제 가능
• Table 당 Index를 32개까지 생성은 가능하나,
Index가 많을 수록 DML문의 성능이 저하됨
ALTER INDEX [index_name] [ MONITORING | NOMONITORING ] USAGE;
SELECT INDEX_NAME, USED
FROM V$OBJECT_USAGE;
16.
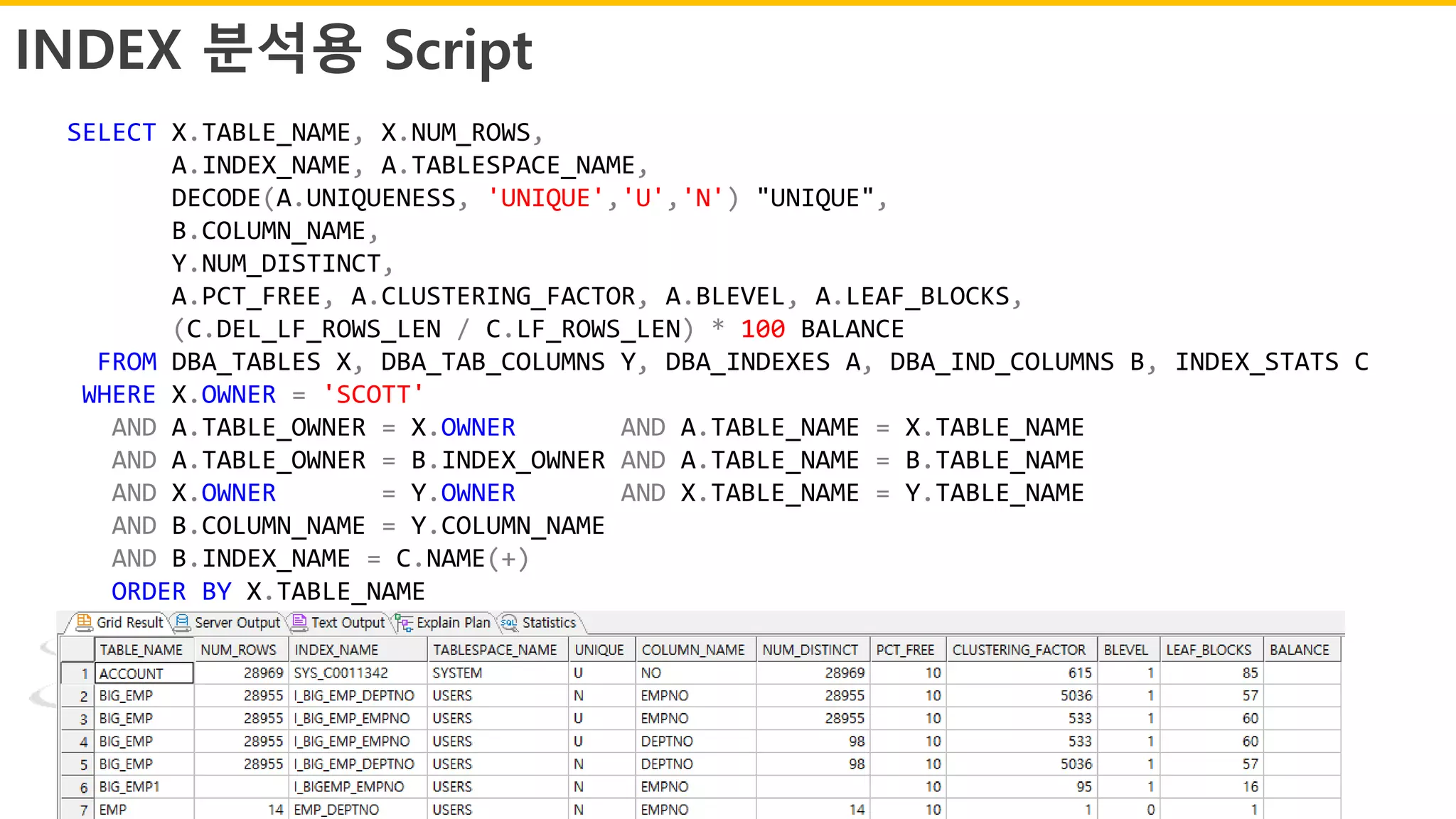
INDEX 분석용 Script
SELECTX.TABLE_NAME, X.NUM_ROWS,
A.INDEX_NAME, A.TABLESPACE_NAME,
DECODE(A.UNIQUENESS, 'UNIQUE','U','N') "UNIQUE",
B.COLUMN_NAME,
Y.NUM_DISTINCT,
A.PCT_FREE, A.CLUSTERING_FACTOR, A.BLEVEL, A.LEAF_BLOCKS,
(C.DEL_LF_ROWS_LEN / C.LF_ROWS_LEN) * 100 BALANCE
FROM DBA_TABLES X, DBA_TAB_COLUMNS Y, DBA_INDEXES A, DBA_IND_COLUMNS B, INDEX_STATS C
WHERE X.OWNER = 'SCOTT'
AND A.TABLE_OWNER = X.OWNER AND A.TABLE_NAME = X.TABLE_NAME
AND A.TABLE_OWNER = B.INDEX_OWNER AND A.TABLE_NAME = B.TABLE_NAME
AND X.OWNER = Y.OWNER AND X.TABLE_NAME = Y.TABLE_NAME
AND B.COLUMN_NAME = Y.COLUMN_NAME
AND B.INDEX_NAME = C.NAME(+)
ORDER BY X.TABLE_NAME
17.
Join 종류
Join description
NaturalJoin 결합조건이 = 인 일반적인 Join
조건에 맞는 것만 출력
( = Equal Join , Inner Join )
Cross Join 결합조건이 없는 Join
전체와 전체를 다 묶음 (묻지마 Join)
( = Catesian Product )
Self-reference Join 하나의 Table을 다른 Alias를 붙여서 Join
(마치 다른 Table인 듯 취급)
Outer Join 기준이 되는 Table은 결합조건에 맞지 않아도 출력
1. 문법적 측면
18.
Join 종류
Join description
Sort-MergeJoin
/*+USE_MERGE(a b)*/
Join에 참여하는 Column에 Index가 없을 경우
Full Table Scan -> 그 결과를 Sort한 후 Merge
(즉 3번의 Load가 필요함)
가장 느린 방법
Nested-Loops Join
/*+USE_NL(a b)*/
Index를 이용하여 Join
Cluster Join Index보다 성능이 좋은 Cluster를 이용하여 Join
Hash Join
/*+HASH(a b)*/
v7.3.3부터 가능 : SMJ가 넘 느려서 성능 개선을 위해 개발
왠만해서는 SMJ보다 빠름
Optimizer가 SMJ를 선택하는 경우는 거의 없다.
결합조건 별로 Buffer에 파티션을 나누어 Record를 Load
2. 실행적 측면
19.
Join 성능에 영향을주는 요소
1. Driving Table
2. Join 순서
3. Data 량
4. Index 사용여부
WHERE 절의 Check 조건으로 걸러지는 것 기준으로
Data량이 가장 작은 것을 Driving Table로
Driving Table과 결합조건이 있는 Table중
Data량이 가장 작은 것을 Join
만약 결합 조건 중 한쪽만 Index가 있다면,
Join 할 Table을 Index가 있는 Table로 결정
Driving Table 결정 원리 (Rule-based Optimizer)
- Join에 참여하는 Column에 모두 INDEX가 있거나 없는 경우 (동등조건) : FROM에서 먼 쪽부터
-> 단, Single Index와 Composite Index 중에서는 Composite Index부터,
-> Unique Index와 Non-unique Index 중에서는 Unique Index 부터,
- Outer Join은 Data가 있는 쪽부터
- /*+ORDERED*/ 하면 FROM에서 가까운 쪽부터
- /*+LEADING(A)*/ 하면 해당 Table 부터






![INDEX Balancing 분석
ANALYZE INDEX [index_name] VALIDATE STRUCTURE;
SELECT (DEL_LF_ROWS_LEN / LF_ROWS_LEN) * 100 AS BALANCING
FROM INDEX_STATS;
* INDEX_STATS
• INDEX 현재 구조 분석
• Block 수
• 삭제된 행의 길이
• INDEX DEPTH (HEIGHT)](https://image.slidesharecdn.com/2015-06-26oracle3-150623063728-lva1-app6891/75/2015-06-26-Oracle-3-11-2048.jpg)
![INDEX 재구성
ALTER INDEX [index_name] REBUILD [NOLOGGING]
TABLESPACE [tablespace_name];
• Balancing이 20% 초과하면 성능 저하가 심하므로 재구성 하는게 좋음 (사후조치)
(그럼 사전조치는 ? 물리적 설계 : 빈번한 DML 고려)
• INDEX 삭제 후 재 생성
• On-Line rebuild 가능 (DBMS_REDEFINITION Package)
• Tablespace 위치 변경도 가능](https://image.slidesharecdn.com/2015-06-26oracle3-150623063728-lva1-app6891/75/2015-06-26-Oracle-3-12-2048.jpg)
![INDEX 합병 (B*Tree)
ANALYZE INDEX [index_name] COALESCE;
SELECT INDEX_NAME, LEAF_BLOCKS
FROM USER_INDEXES;
SELECT NAME, BLOCKS, LF_BLKS, BR_BLKS
FROM INDEX_STATS;
• INDEX Key 값을 재 배치
• 불필요한 Block 검색 및 공간 낭비를 방지
• 하지만 빈 Node를 반환해주지는 않음](https://image.slidesharecdn.com/2015-06-26oracle3-150623063728-lva1-app6891/75/2015-06-26-Oracle-3-13-2048.jpg)
![INDEX 압축 (B*Tree, IOT)
SELECT INDEX_NAME, COMPRESSION
FROM USER_INDEXES;
• 디스크 공간 절약I/O를 줄일 수 있으므로 검색속도 향상
(하지만 Transaction이 조금만 증가해도 느려질 수 있다)
• 대용량 Data에 적용하면 효율적
• Non-Partitioned Index에만 적용 가능
CREATE INDEX [index_name] ON [table_name]([column_name,...]) [ COMPRESS | NOCOMPRESS ];](https://image.slidesharecdn.com/2015-06-26oracle3-150623063728-lva1-app6891/75/2015-06-26-Oracle-3-14-2048.jpg)
![INDEX Monitoring
• INDEX는 SELECT의 성능을 올려주지만,
DML 들의 성능을 떨어트린다.
• Optimizer가 안 쓰는 INDEX는 과감히 삭제하자.
• 9i부터 가능
• 사용되지 않은 Index를 검색하여 삭제 가능
• Table 당 Index를 32개까지 생성은 가능하나,
Index가 많을 수록 DML문의 성능이 저하됨
ALTER INDEX [index_name] [ MONITORING | NOMONITORING ] USAGE;
SELECT INDEX_NAME, USED
FROM V$OBJECT_USAGE;](https://image.slidesharecdn.com/2015-06-26oracle3-150623063728-lva1-app6891/75/2015-06-26-Oracle-3-15-2048.jpg)



![[2015-06-12] Oracle 성능 최적화 및 품질 고도화 1](https://cdn.slidesharecdn.com/ss_thumbnails/2015-06-12oracle1-150615000001-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2020] SQL Tuning](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-201117134901-thumbnail.jpg?width=640&height=640&fit=bounds)

![[2015-07-10-윤석준] Oracle 성능 관리 & v$sysstat](https://cdn.slidesharecdn.com/ss_thumbnails/2015-07-10-oraclevsysstat-150709064246-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2015-06-05] Oracle TX Lock](https://cdn.slidesharecdn.com/ss_thumbnails/2015-06-05oracletxlock-150604084153-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[오픈소스컨설팅]Day #1 MySQL 엔진소개, 튜닝, 백업 및 복구, 업그레이드방법](https://cdn.slidesharecdn.com/ss_thumbnails/day1mysqlintroduction-141212003401-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)








![[2015 07-06-윤석준] Oracle 성능 최적화 및 품질 고도화 4](https://cdn.slidesharecdn.com/ss_thumbnails/2015-07-06-oracle4-150702090606-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2015-06-19] Oracle 성능 최적화 및 품질 고도화 2](https://cdn.slidesharecdn.com/ss_thumbnails/2015-06-19oracle2-150618090026-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)




































![[2015-07-20-윤석준] Oracle 성능 관리 2](https://cdn.slidesharecdn.com/ss_thumbnails/2015-07-20-oracle2-150727235547-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)










![[KOSSA] C++ Programming - 18th Study - STL #4](https://cdn.slidesharecdn.com/ss_thumbnails/kossacprogramming-18thstudy-stl4-150531132750-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)




