Driving의 중요성
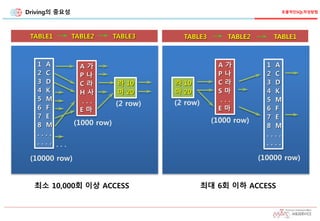
TABLE1 TABLE2TABLE3
(10000 row)
(1000 row)
(2 row)
. . .
1 A
2 C
3 D
4 K
5 M
6 F
7 E
8 M
. . . .
. . . .
A 가
P 나
C 라
H 사
. . .
E 마
라 10
마 20
최소 10,000회 이상 ACCESS
TABLE3 TABLE2 TABLE1
(10000 row)
(2 row)
라 10
마 20
(1000 row)
A 가
P 나
C 라
S 마
. . .
E 마
1 A
2 C
3 D
4 K
5 M
6 F
7 E
8 M
. . . .
. . . .
최대 6회 이하 ACCESS
효율적인SQL작성방법
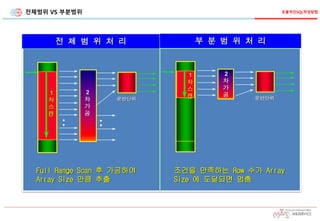
전체범위 VS 부분범위
전체 범 위 처 리
2
차
가
공
운반단위
•
•
•
•
1
차
스
캔
Full Range Scan 후 가공하여
Array Size 만큼 추출
부 분 범 위 처 리
2
차
가
공
운반단위
1
차
스
캔
조건을 만족하는 Row 수가 Array
Size 에 도달되면 멈춤
효율적인SQL작성방법
INDEX를 사용 못하게되는 경우와 사례
INDEX COLUMN의 변형
SELECT *
FROM DEPT
WHERE SUBSTR(DNAME,1,3) = 'ABC'
NOT Operator
NULL, NOT NULL
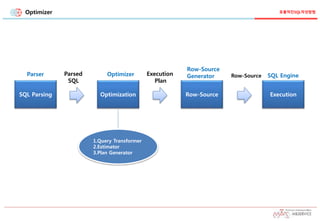
Optimizer 의 취사선택
SELECT *
FROM EMP
WHERE JOB <> 'SALES'
SELECT *
FROM EMP
WHERE ENAME IS NOT NULL
SELECT *
FROM EMP
WHERE JOB LIKE 'AB%'
AND EMPNO = '7890'
Function Based Index 사용시는 예외
효율적인SQL작성방법
9.
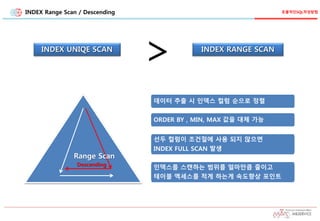
INDEX Range Scan/ Descending
INDEX UNIQE SCAN INDEX RANGE SCAN
>
데이터 추출 시 인덱스 컬럼 순으로 정렬
ORDER BY , MIN, MAX 값을 대체 가능
선두 컬럼이 조건절에 사용 되지 않으면
INDEX FULL SCAN 발생
인덱스를 스캔하는 범위를 얼마만큼 줄이고
테이블 엑세스를 적게 하는게 속도향상 포인트
Range Scan
Descending
효율적인SQL작성방법
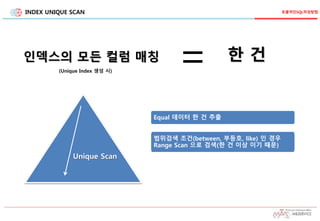
10.
INDEX UNIQUE SCAN
UniqueScan
=인덱스의 모든 컬럼 매칭 한 건
Equal 데이터 한 건 추출
범위검색 조건(between, 부등호, like) 인 경우
Range Scan 으로 검색(한 건 이상 이기 때문)
(Unique Index 생성 시)
효율적인SQL작성방법
11.
INDEX SKIP SCAN
인덱스: 기준일자 + 업종코드
SELECT /*+(INDEX(A 일별업종별거래_IDX)*/
기준일자, 업종코드, 체결건수, 체결수량, 거래대금
FROM 일별업종별거래 A
WHERE 기준일자 BETWEEN ‘20130701’ AND ‘20130709’
INDEX RANGE SCAN
SELECT /*+(INDEX(A 일별업종별거래_IDX)*/
기준일자, 업종코드, 체결건수, 체결수량, 거래대금
FROM 일별업종별거래 A
WHERE 업종코드 = ’01’
INDEX SKIP SCAN
효율적인SQL작성방법
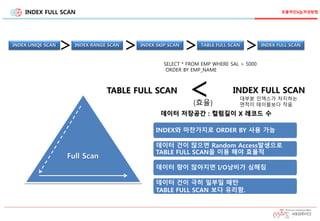
12.
INDEX FULL SCAN
FullScan
INDEX UNIQE SCAN INDEX RANGE SCAN
> >INDEX SKIP SCAN
>TABLE FULL SCAN
>INDEX FULL SCAN
<TABLE FULL SCAN INDEX FULL SCAN
(효율)
SELECT * FROM EMP WHERE SAL > 5000
ORDER BY EMP_NAME
데이터 건이 많으면 Random Access발생으로
TABLE FULL SCAN을 이용 해야 효율적
데이터 량이 많아지면 I/O낭비가 심해짐
데이터 건이 극히 일부일 때만
TABLE FULL SCAN 보다 유리함.
데이터 저장공간 : 컬럼길이 X 레코드 수
INDEX와 마찬가지로 ORDER BY 사용 가능
효율적인SQL작성방법
대부분 인덱스가 차지하는
면적이 테이블보다 작음
13.
INDEX FAST FULLSCAN
INDEX FULL SCAN INDEX FAST FULL SCAN
1.인덱스 구조를 따라 스캔 1.세그먼트 전체를 스캔
2.결과집합 순서 보장 2.결과집합 순서 보장 안 됨
3.Single Block I/O 3.Multiblock I/O(세그먼트 전체스캔)
4.병렬스캔 불가(파티션 돼 있지 않다면) 4.병렬스캔 가능
5.인덱스에 포함되지 않은 컬럼 조회시에도 사용가능 5.인덱스에 포함된 컬럼으로만 조회할 때 사용 가능
SELECT * FROM 공급업체
WHERE 업체명 LIKE ‘%네트웍스%’
SELECT /*+ORDERED USE_NL(B) NO_MERGE(B) ROWID(B)*/
B.*
FROM (
SELECT /*+INDEX_FFS(공급업체 공급업체_IDX)*/
ROWID AS RID
FROM 공급업체
WHERE INSTR(업체명,’네트웍스’) > 0
)A,
공급업체 B
WHERE B.ROWID = A.RID
효율적인SQL작성방법
10g 부터는 index range or full scan 일 때도 Multiblock I/O스캔발생 (인덱스만 읽을 때)
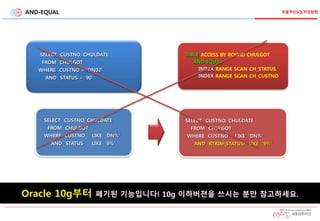
AND-EQUAL
SELECT CUSTNO, CHULDATE
FROMCHULGOT
WHERE CUSTNO = 'DN02'
AND STATUS = '90'
SELECT CUSTNO, CHULDATE
FROM CHULGOT
WHERE CUSTNO LIKE 'DN%'
AND RTRIM(STATUS) LIKE '9%'
TABLE ACCESS BY ROWID CHULGOT
AND-EQUAL
INDEX RANGE SCAN CH_STATUS
INDEX RANGE SCAN CH_CUSTNO
SELECT CUSTNO, CHULDATE
FROM CHULGOT
WHERE CUSTNO LIKE 'DN%'
AND STATUS LIKE '9%'
Oracle 10g부터 폐기된 기능입니다! 10g 이하버젼을 쓰시는 분만 참고하세요.
효율적인SQL작성방법
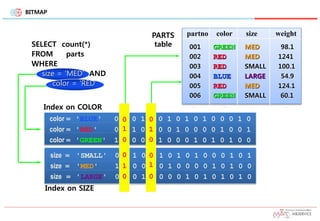
BITMAP
SELECT count(*)
FROM parts
WHERE
size= 'MED' AND
color = 'RED'
Index on COLOR
color = 'BLUE' 0 0 0 1 0 0 1 0 1 0 1 0 0 0 1 0
color = 'RED' 0 1 1 0 1 0 0 1 0 0 0 0 1 0 0 1
color = 'GREEN' 1 0 0 0 0 1 0 0 0 1 0 1 0 1 0 0
Index on SIZE
size = 'SMALL' 0 0 1 0 0 1 0 1 0 1 0 0 0 1 0 1
size = 'MED' 1 1 0 0 1 0 1 0 0 0 0 1 0 1 0 0
size = 'LARGE' 0 0 0 1 0 0 0 0 1 0 1 0 1 0 1 0
0
1
0
0
1
0
PARTS
table 001 GREEN MED 98.1
002 RED MED 1241
003 RED SMALL 100.1
004 BLUE LARGE 54.9
005 RED MED 124.1
006 GREEN SMALL 60.1
... .... ..... ...
partno color size weight
0
1
0
0
1
0
18.
BITMAP
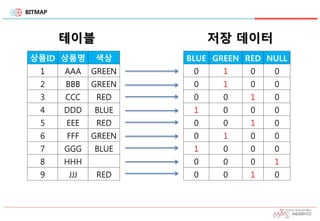
상품ID 상품명 색상
1AAA GREEN
2 BBB GREEN
3 CCC RED
4 DDD BLUE
5 EEE RED
6 FFF GREEN
7 GGG BLUE
8 HHH
9 JJJ RED
BLUE GREEN RED NULL
0 1 0 0
0 1 0 0
0 0 1 0
1 0 0 0
0 0 1 0
0 1 0 0
1 0 0 0
0 0 0 1
0 0 1 0
테이블 저장 데이터
19.
BITMAP
중복되는 값의 수가적으면 BITMAP INDEX??????
저장 시에 속도도 빠르고 용량도 적게 차지하지만
(물론 인덱스 블록을 읽는 범위가 작아서 아주 살짝 빠르긴 함)
조회 속도는 B*Tree 인덱스와 다른게 없음..(Random 액세스)
이런 경우 사용하세요
1. Null에 대한 검색이 필요한 경우
2. 하나의 컬럼 이상 조건을 걸 경우 SELECT * FROM 상품
WHERE (크기=‘SMALL’ OR 크기 IS NULL)
AND 색상 = ‘GREEN’
20.
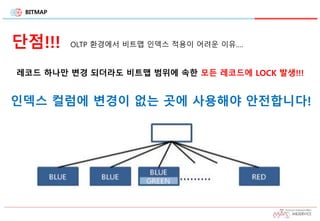
BITMAP
단점!!!
레코드 하나만 변경되더라도 비트맵 범위에 속한 모든 레코드에 LOCK 발생!!!
OLTP 환경에서 비트맵 인덱스 적용이 어려운 이유….
인덱스 컬럼에 변경이 없는 곳에 사용해야 안전합니다!
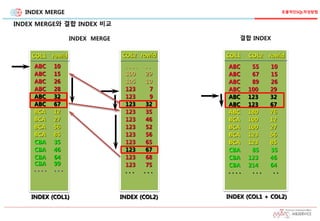
INDEX의 중요성!
테이블 드라이빙우선순위
부서 테이블(100건)
부서번호 (PK)
사원 테이블(10만건)
사원번호 (PK)
부서번호(FK)
①
②
조건
-부서테이블, 사원테이블에는 PK 인덱스만 존재
-전체 데이터 검색
문제
1번 테이블이 먼저 드라이빙 하는게 유리할까요?
2번 테이블이 먼저 드라이빙 하는게 유리할까요?
-1번 테이블이 먼저 드라이빙 될 경우
부서 테이블을 100건을 스캔하고서
사원 테이블을 10만번 스캔
100 X 100,000 = 1,000,000 (천만번 스캔!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!)
-2번 테이블이 먼저 드라이빙 될 경우
사원테이블을 10만번 스캔하고서
부서 테이블을 스캔하는데
부서번호키가 Unique index 이기 때문에 1번만 읽고 스캔
100,000 X 1 = 100,000 (십만번 스캔)
효율적인SQL작성방법
23.
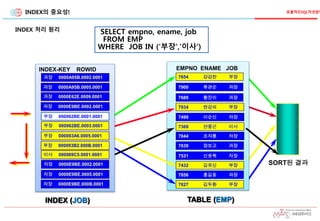
INDEX의 중요성!
INDEX 처리원리
SORT된 결과
TABLE (EMP)
EMPNO ENAME JOB
7654 강감찬 부장
7900 류관순 과장
7689 황진이 과장
7499 이순신 차장
7934 변강쇠 부장
7844 조자룡 차장
7369 안중근 이사
7839 장보고 과장
7531 신윤복 차장
7856 홍길동 과장
7432 김유신 부장
7827 김두환 부장
INDEX (JOB)
INDEX-KEY ROWID
과장 0000A95B.0002.0001
과장 0000A95B.0005.0001
과장 0000E62E.0009.0001
과장 0000E9BE.0002.0001
부장 000062BE.0001.0001
부장 000062BE.0003.0001
부장 000093A6.0005.0001
부장 000093B2.000B.0001
이사 000069C5.0001.0001
차장 0000E9BE.0002.0001
차장 0000E9BE.0005.0001
차장 0000E9BE.000B.0001
SELECT empno, ename, job
FROM EMP
WHERE JOB IN ('부장‘,'이사‘)
효율적인SQL작성방법
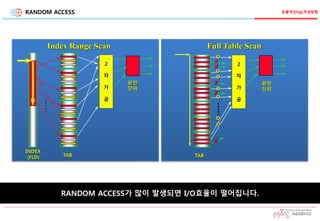
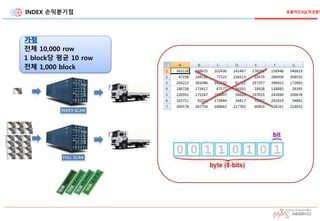
INDEX 손익분기점
가정
전체 10,000row
1 block당 평균 10 row
전체 1,000 block
운반
단위
INDEX
(FLD)
.....
2
차
가
공
TAB TAB
운반
단위
o
x
o
o
o
x
o
x
.....
x
x
2
차
가
공
o
o
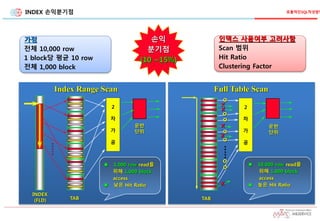
Index Range Scan Full Table Scan
1,000 row read를
위해 1,000 block
access
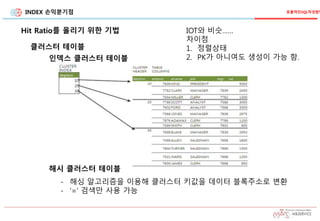
낮은 Hit Ratio
10,000 row read를
위해 1,000 block
access
높은 Hit Ratio
인덱스 사용여부 고려사항
Scan 범위
Hit Ratio
Clustering Factor
손익
분기점
(10 ~15%)
효율적인SQL작성방법
27.
INDEX 손익분기점 효율적인SQL작성방법
HitRatio를 올리기 위한 기법
IOT(Index-Oraganized Table)
Create table 테이블명 (컬럼명 타입 primary key, …….)
organization heap
Create table 테이블명 (컬럼명 타입 primary key, …….)
organization index
파티셔닝
28.
INDEX 손익분기점 효율적인SQL작성방법
HitRatio를 올리기 위한 기법
클러스터 테이블
인덱스 클러스터 테이블
IOT와 비슷……
차이점
1. 정렬상태
2. PK가 아니여도 생성이 가능 함.
해시 클러스터 테이블
- 해싱 알고리즘을 이용해 클러스터 키값을 데이터 블록주소로 변환
- ‘=‘ 검색만 사용 가능
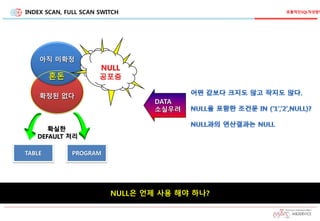
INDEX SCAN, FULLSCAN SWITCH
확정된 없다
아직 미확정
혼돈
NULL
공포증
확실한
DEFAULT 처리
TABLE PROGRAM
DATA
소실우려
NULL은 언제 사용 해야 하나?
효율적인SQL작성방법
32.
INDEX SCAN, FULLSCAN SWITCH
NULL 이럴 때만 사용 합시다!
-미 확정 값을 표현하고자 할 때
-결합인덱스의 구성 컬럼이 된다면 NOT NULL!
-인덱스 조건 값으로 자주 사용 된다면 NOT NULL!
특정 값이 지나치게 많고 나머지 값만 주로 인덱스로 액세스
A사
B사
C사
D사
E사
F사
B
컬럼 값
C
D
E
F
NULL TABLE FULL SCAN
INDEX RANGE SCAN
효율적인SQL작성방법
33.
INDEX SCAN, FULLSCAN SWITCH
(78%)
4% 6% 7%
5%
A
BC D
E
COL1 분포도
KEY COL1 . . . .
TABLE1
(10000 row)
CREATE INDEX index_name ON
table_name (COL1);
COL1 = 'A' 를 그대로
COL1KEY . . . .
A. . . . . . . .
A. . . . . . . .
A. . . . . . . .
B. . . . . . . .
B. . . . . . . .
. . . .. . . . . . . .
COL1 ROWID
A . . . .
A . . . .
A . . . .
B . . . .
B . . . .
. . . . . . . .
TABLE1
(10000 row)
INDEX1
(10000 row)
COL1 = 'A' 를 COL1 NULL로
COL1KEY . . . .
Null. . . . . . . .
Null. . . . . . . .
Null. . . . . . . .
B. . . . . . . .
B. . . . . . . .
. . . .. . . . . . . .
COL1 ROWID
B . . . .
. . . . . . . .
C . . . .
. . . . . . . .
TABLE1
(10000 row)
INDEX1
(2000 row)
효율적인SQL작성방법
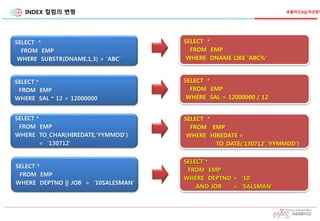
INDEX 컬럼의 변형
SELECT*
FROM EMP
WHERE SUBSTR(DNAME,1,3) = 'ABC'
SELECT *
FROM EMP
WHERE DNAME LIKE 'ABC%'
SELECT *
FROM EMP
WHERE SAL * 12 = 12000000
SELECT *
FROM EMP
WHERE TO_CHAR(HIREDATE,'YYMMDD')
= ‘130712'
SELECT *
FROM EMP
WHERE HIREDATE =
TO_DATE(‘130712','YYMMDD')
SELECT *
FROM EMP
WHERE SAL = 12000000 / 12
SELECT *
FROM EMP
WHERE DEPTNO || JOB = '10SALESMAN'
SELECT *
FROM EMP
WHERE DEPTNO = '10'
AND JOB = 'SALSMAN'
효율적인SQL작성방법
36.
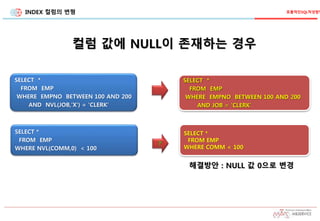
INDEX 컬럼의 변형
SELECT*
FROM EMP
WHERE NVL(COMM,0) < 100
?
SELECT *
FROM EMP
WHERE COMM < 100
SELECT *
FROM EMP
WHERE EMPNO BETWEEN 100 AND 200
AND NVL(JOB,'X') = 'CLERK'
SELECT *
FROM EMP
WHERE EMPNO BETWEEN 100 AND 200
AND JOB = 'CLERK'
컬럼 값에 NULL이 존재하는 경우
해결방안 : NULL 값 0으로 변경
효율적인SQL작성방법
37.
INDEX 컬럼의 변형
SELECT*
FROM EMP
WHERE JOB = 'MANAGER'
SELECT *
FROM EMP
WHERE RTRIM(JOB) = 'MANAGER'
SELECT *
FROM EMP
WHERE EMPNO = 8978
SELECT *
FROM EMP
WHERE RTRIM(EMPNO) = 8978
SELECT CUSTNO, CHULDATE
FROM CHULGOT
WHERE CUSTNO LIKE 'DN%'
AND RTRIM(STATUS) LIKE '9%'
SELECT CUSTNO, CHULDATE
FROM CHULGOT
WHERE CUSTNO LIKE 'DN%'
AND STATUS LIKE '9%'
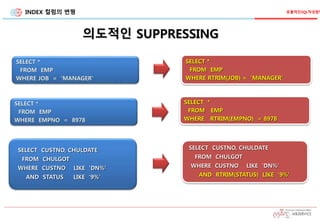
의도적인 SUPPRESSING
효율적인SQL작성방법
38.
INDEX 컬럼의 변형
의도적인SUPPRESSING
SELECT X.CUSTNO, CHULDATE, CUSTNAME
FROM MECHUL1T X, MECHUL2T Y
WHERE X.SALENO = Y.SALENO
AND X.SALEDEPT = '710'
AND Y.SALEDATE LIKE ‘1301%'
10 Sec
SELECT X.CUSTNO, CHULDATE, CUSTNAME
FROM MECHUL1T X, MECHUL2T Y
WHERE X.SALENO = Y.SALENO
AND RTRIM(X.SALEDEPT) = '710'
AND Y.SALEDATE LIKE ‘1301%'
1 Sec
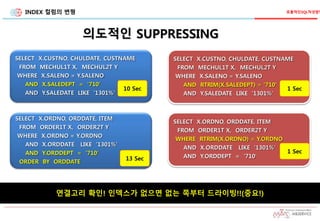
SELECT X.ORDNO, ORDDATE, ITEM
FROM ORDER1T X, ORDER2T Y
WHERE X.ORDNO = Y.ORDNO
AND X.ORDDATE LIKE ‘1301%'
AND Y.ORDDEPT = '710'
ORDER BY ORDDATE
13 Sec
SELECT X.ORDNO, ORDDATE, ITEM
FROM ORDER1T X, ORDER2T Y
WHERE RTRIM(X.ORDNO) = Y.ORDNO
AND X.ORDDATE LIKE ‘1301%'
AND Y.ORDDEPT = '710’
1 Sec
연결고리 확인! 인덱스가 없으면 없는 쪽부터 드라이빙!!(중요!)
효율적인SQL작성방법
39.
INDEX 컬럼의 변형
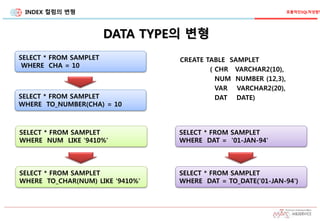
SELECT* FROM SAMPLET
WHERE NUM LIKE '9410%'
CREATE TABLE SAMPLET
( CHR VARCHAR2(10),
NUM NUMBER (12,3),
VAR VARCHAR2(20),
DAT DATE)
SELECT * FROM SAMPLET
WHERE CHA = 10
SELECT * FROM SAMPLET
WHERE TO_NUMBER(CHA) = 10
SELECT * FROM SAMPLET
WHERE TO_CHAR(NUM) LIKE '9410%'
SELECT * FROM SAMPLET
WHERE DAT = '01-JAN-94'
SELECT * FROM SAMPLET
WHERE DAT = TO_DATE('01-JAN-94')
DATA TYPE의 변형
효율적인SQL작성방법
40.
INDEX 컬럼의 변형
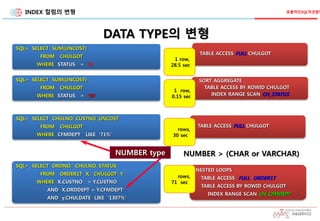
DATATYPE의 변형
TABLE ACCESS FULL CHULGOT
1 row,
28.5 sec
SQL> SELECT SUM(UNCOST)
FROM CHULGOT
WHERE STATUS = 90
SORT AGGREGATE
TABLE ACCESS BY ROWID CHULGOT
INDEX RANGE SCAN CH_STATUS
1 row,
0.15 sec
SQL> SELECT SUM(UNCOST)
FROM CHULGOT
WHERE STATUS = '90'
SQL> SELECT CHULNO, CUSTNO, UNCOST
FROM CHULGOT
WHERE CFMDEPT LIKE '71%'
NESTED LOOPS
TABLE ACCESS FULL ORDER1T
TABLE ACCESS BY ROWID CHULGOT
INDEX RANGE SCAN CH_CFMDEPT
rows,
71 sec
SQL> SELECT ORDNO, CHULNO, STATUS
FROM ORDER1T X, CHULGOT Y
WHERE X.CUSTNO = Y.CUSTNO
AND X.ORDDEPT = Y.CFMDEPT
AND y.CHULDATE LIKE ‘1307%'
NUMBER type
TABLE ACCESS FULL CHULGOT
rows,
30 sec
NUMBER > (CHAR or VARCHAR)
효율적인SQL작성방법
41.
INDEX 활용기준
INDEX 적용기준
6블럭이상의 테이블에 적용(6블럭 이하는 연결고리만)
컬럼의 분포도가 10~15% 이내인 경우 적용
분포도가 범위 이내더라도 절대량이 많은 경우에는 클러스터링 검토
분포도가 범위 이상이더라도 부분범위처리를 목적인 경우 적용
인덱스만 사용하여 해결하고자 하는 경우 분포도가 나쁘더라도 적용 가능
효율적인SQL작성방법
42.
INDEX 활용기준
INDEX 선정기준
효율적인SQL작성방법
분포도가좋은 컬럼은 단독적으로 생성하여 활용도 향상
자주 조합되어 사용되는 경우는 결합인덱스 생성
각종 엑세스 경우의 수를 만족하도록 인덱스 간의 역할 분담
가능한 수정이 빈번하지 않은 컬럼
기본키 및 외부키 (조인의 연결고리가 되는 컬럼)
결합 인덱스의 컬럼 순서 선정에 주의
43.
INDEX 활용기준
INDEX 선정절차
효율적인SQL작성방법
•해당 테이블 사용하는 모든 쿼리의 액세스 유형 조사
1. 해당 테이블의 액세스 유형조사
• 인덱스 후보로 어떤 컬럼이 좋을지 선정하고 각 컬럼에 데이터 분포도 분석
2. 대상 컬럼의 선정 및 분포도 분석
• FOR문 안에서 실행되는 쿼리 일 경우 최적에 액세스 경로를 탈 수 있게 최적화
3. 반복 수행되는 액세스 경로의 해결
• 데이터량이 많은 경우 검토(초기에는 적용하기 쉬우나 운영 중에는 초기에 비해 적용이 어려움)
4. 클러스터링 검토
• 컬럼의 순서를 결정
5. 인덱스 컬럼의 조합 및 순서의 결정
• 잘못된 쿼리로 인해 인덱스 적용이 안 될 수 있음. 이런 쿼리들을 최적화 쿼리로 수정
• 모든 작업이 완료되면 일괄 적용
6. 시험생성 및 테스트 그리고 일괄 수정
44.
INDEX 활용기준
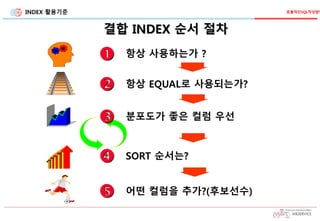
결합 INDEX순서 절차
효율적인SQL작성방법
항상 사용하는가 ?
항상 EQUAL로 사용되는가?
분포도가 좋은 컬럼 우선
SORT 순서는?
어떤 컬럼을 추가?(후보선수)
45.
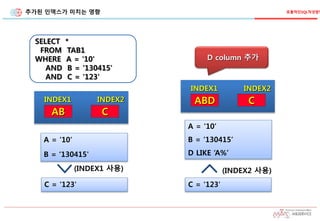
추가된 인덱스가 미치는영향 효율적인SQL작성방법
SELECT *
FROM TAB1
WHERE A = '10'
AND B = ‘130415'
AND C = '123'
AB C
INDEX1 INDEX2
A = '10‘
B = ‘130415'
C = '123'
(INDEX1 사용)
D column 추가
ABD C
INDEX1 INDEX2
C = '123'
(INDEX2 사용)
A = '10‘
B = ‘130415‘
D LIKE ‘A%’
46.
추가된 인덱스가 미치는영향 효율적인SQL작성방법
예제
CHULITEM table Primary Key : CHULNO + ORDNO + ITEM
SQL> SELECT CHULNO, ORDNO, ITEM, CHULQTY
FROM CHULITEM
WHERE CHULNO = '2565'
AND ORDNO = '8584'
AND LOT = 'P0009'
1 rows,
0.01sec
TABLE ACCESS BY ROWID CHULITEM
INDEX RANGE SCAN PK_CHULITEM
SQL> SELECT CHULNO, ORDNO, ITEM, CHULQTY
FROM CHULITEM
WHERE CHULNO = '2565'
AND ORDNO = '8584'
AND LOT = 'P0009'
1 rows,
37.7sec
SQL> CREATE INDEX CI_LOT ON CHULITEM (LOT)
TABLE ACCESS BY ROWID CHULITEM
INDEX RANGE SCAN CI_LOT
SQL> SELECT CHULNO, ORDNO, ITEM, CHULQTY
FROM CHULITEM
WHERE CHULNO = '2565'
AND ORDNO = '8584'
AND LOT = 'P0009'
1 rows,
0.01 sec
SQL> CREATE INDEX CI_LOT_ITEM ON CHUITEM (LOT,ITEM)
TABLE ACCESS BY ROWID CHULITEM
INDEX RANGE SCAN PK_CHULITEM
#5 Statement, prestatement
바인딩 단점을 보완한 바인딩변수 peeking : 하드파싱 시 컬럼분포도를 이용해 통계정보를 만들어낸다
-SQL 파서가 파싱
반복사용하기 위해 라이브러리 캐쉬에 저장( 커서 공유)
-최적화하기 쉬운형태로 변환
후보군이 될만한 실행계획들 생성
오브젝트 통계정보, 시스템 성능 통계정보를 이용하여 필요한 I/O, CPU, 메모리 사용량 등을 예측
-SQL 실행계획 생성


































![[오라클교육/SQL교육/IT교육/실무중심교육학원추천_탑크리에듀]#4.SQL초보에서 Schema Objectes까지](https://cdn.slidesharecdn.com/ss_thumbnails/sqlschemaobjects4-170123085836-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Pgday.Seoul 2021] 1. 예제로 살펴보는 포스트그레스큐엘의 독특한 SQL](https://cdn.slidesharecdn.com/ss_thumbnails/sql-211217063145-thumbnail.jpg?width=640&height=640&fit=bounds)










![[구로IT학원추천/구로디지털단지IT학원/국비지원IT학원/재직자/구직자환급교육]#9.SQL초보에서 Schema Objects까지](https://cdn.slidesharecdn.com/ss_thumbnails/sqlschemaobjects9-170126020830-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Pgday.Seoul 2020] SQL Tuning](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-201117134901-thumbnail.jpg?width=640&height=640&fit=bounds)













![[20140830, Pycon2014] NetworkX를 이용한 네트워크 분석](https://cdn.slidesharecdn.com/ss_thumbnails/20140830pyconnetworkx-140830071831-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


![[White Paper] SDN 기반 공격 탐지차단 강화를 위한 네트워크 관리 정보 구성 방안](https://cdn.slidesharecdn.com/ss_thumbnails/sdn-170124090452-thumbnail.jpg?width=640&height=640&fit=bounds)






![[2015-06-26] Oracle 성능 최적화 및 품질 고도화 3](https://cdn.slidesharecdn.com/ss_thumbnails/2015-06-26oracle3-150623063728-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[2015-06-19] Oracle 성능 최적화 및 품질 고도화 2](https://cdn.slidesharecdn.com/ss_thumbnails/2015-06-19oracle2-150618090026-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)









![[제3회 스포카콘] SQL 쿼리 최적화 맛보기](https://cdn.slidesharecdn.com/ss_thumbnails/spoqacon2021keynotejhuni-210222015014-thumbnail.jpg?width=640&height=640&fit=bounds)




