SQL초보에서 Schema Objects까지
4.2집합 함수(Aggreation Function), GROUP BY, HAVING
행(ROW)들의 집합에 대해 연산을 하는 것이므로 행들의 집합 수 만큼 결과가 반환된다. 테이블
은 GROUP BY절에 의해 그룹으로 나누어 질 수 있으며 그룹함수(Aggregation Function)는 SELECT
문과 HAVING절에 사용 되어 질 수 있다. HAVING절은 GROUP BY 되는 함수에 조건을 주기 위해
서 사용 되며 WHERE 절을 이용해서는 안 된다.(그룹핑 칼럼에 조건을 주는 경우는 WHERE절,
HAVING절 모두에서 사용가능 하다.)
GROUP BY절을 이용하여 한 테이블에서 행들을 원하는 그룹으로 나누는 것이 가능하며 칼럼 명
을 집합 함수와 SELECT절에 이용하고자 한다면 GROUP BY 뒤에 칼럼을 추가 해야 한다. 즉
SELECT절에 그룹함수가 오면 SELECT절의 나머지 칼럼은 GROUP BY절에 나타나야 한다. 또한
GROUP BY절에는 칼럼의 위치 순서 표기(1, 2, 3,,,)나 칼럼 Alias는 사용 할 수 없다.
[형식]
SELECT column, group function
FROM TABLE
[WHERE condition]
[GROUP BY [ROLLUP | CUBE] group by expression]
[HAVAING group condition]
[ORDER BY columns]
AVG([DISTINCT|ALL n] : n의 평균값을 반환한다.
SQL> create table sawon (
2 name varchar2(10) not null,
3 sal number(8,0),
4 buseo varchar2(10)
5 );
테이블이 생성되었습니다.
SQL> insert into sawon values ('가길동',2000000,'영업부');
SQL> insert into sawon values ('나길동',3000000, '영업부');
SQL> insert into sawon (name, buseo) values ('다길동','영업부');
2.
SQL> insert intosawon values ('라길동',1000000,'관리부');
SQL> insert into sawon values ('마길동',2000000, '관리부');
--5명의 사원을 이름, 급여, 부서를 입력했다. “다길동” 사원은 급여를 입력하지 않았음에 유의하
자. 입력하지 않았으므로 sal 칼럼은 NULL 값으로 채워져 있을 것이다. NULL값은 아무것도 없다
는 뜻이며 어떠한 연산(+,-,*,/)을 하여도 NULL이 된다. NULL 칼럼 인지를 알기 위해서도 마찬가지
로 IS NULL을 사용해서 확인 해야 한다.
SQL>commit;
커밋이 완료되었습니다.
SQL> select name, sal, buseo from sawon;
NAME SAL BUSEO
---------- ---------- ----------
가길동 2000000 영업부
나길동 3000000 영업부
다길동 영업부
라길동 1000000 관리부
마길동 2000000 관리부
-금 입력한 5명의 사원들의 급여 평균은 얼마일까? 총합은 8000000원 이며 5명이므로… 1600000
정도가 되리라고 생각이 들것이다. 아래를 보자.
SQL> select avg(sal) from sawon;
AVG(SAL)
----------
2000000
--sal 칼럼이 NULL인 “다길동”은 계산에서 제외 된 것이다. 즉 NULL인 칼럼은 계산을 위한 대상
에서 제외된 것 이다. 다음 예문은 이를 해결 한 것이다.
SQL> select avg(nvl(sal, 0)) from sawon;
AVG(NVL(SAL,0))
---------------
1600000
--아래는 부서별로 GROUP BY하여 부서별 평균을 출력 하는 예문이다.
3.
SQL> select buseo,avg(sal) from sawon
2 group by buseo;
BUSEO AVG(SAL)
---------- ----------
관리부 1500000
영업부 2500000
--SELECT절의 어떤 칼럼 이나 표현식도 집합 함수가 아니라면 GROUP BY절에 나타나야 한다.
SQL> select buseo, avg(sal) from sawon;
select buseo, avg(sal) from sawon
*
1행에 오류:
ORA-00937: 단일 그룹의 그룹 함수가 아닙니다
--아래는 부서별로 GROUP BY하여 부서별 평균을 출력 하는데 그 평균이 2000000 보다 큰 부서
와 그 평균을 출력하는 예문 이다. 그룹함수에 조건을 줄때는 반드시 HAVING절을 써야한다.
SQL> select buseo, avg(sal) from sawon
2 group by buseo
3 having avg(sal) > 2000000;
BUSEO AVG(SAL)
---------- ----------
영업부 2500000
--아래는 EMP 테이블에서 부서별로 급여의 최대를 출력하는데, 부서코드에 따라 오름차순으로 표
시 하는 예문 이다.
SQL> select deptno, max(sal) "급여 최대(부서)"
2 from emp
3 group by deptno
4 order by deptno;
DEPTNO 급여 최대(부서)
---------- ---------------
10 5000
20 3000
30 2850
4.
COUNT({* | [DISTINCT|ALL]expr}) : 추출된 행(ROW)수를 반환한다. DISTINCT를 사용 했다면 중복된
행을 제거한 행수를 반환하고 ,expr을 사용 했다면 expr이 NOT NULL인 행의 수를 반환한다.
ASTERISK(*)는 중복 과 NULL을 포함한 모든 행의 수를 반환 할 때 사용한다.
SQL> select name, sal, buseo from sawon;
NAME SAL BUSEO
---------- ---------- ----------
가길동 2000000 영업부
나길동 3000000 영업부
다길동 영업부
라길동 1000000 관리부
마길동 2000000 관리부
--“다길동” 사원은 sal를 등록하지 않았으니 NULL 임을 기억하자.
SQL> select count(sal) from sawon;
COUNT(SAL)
----------
4
SQL> select count(distinct sal) from sawon;
COUNT(DISTINCTSAL)
------------------
3
--아래의 ASTERISK(*)는 결국 테이블등의 전체 건수를 파악 할 때 자주 사용 된다.
SQL> select count(*) from sawon;
COUNT(*)
----------
5
--다음 예문은 부서별로 인원 수를 출력 하는 예문이다.
SQL> select buseo, count(buseo)||'명' from sawon
2 group by buseo;
5.
BUSEO COUNT(BUSEO)||'명'
---------- -----------------------------------------
관리부2명
영업부 3명
--각 직무별로 최대급여와 인원수를 구하되 직무별 인원수가 2명 이상인 직무
만 나타내는 예문이다. (평균급여의 소수점 이하는 반올림)
SQL> select job "직무", round(max(sal)) "최대 급여", count(*) "인원수"
2 from emp
3 group by job
4 having count(*)>2;
직무 최대 급여 인원수
--------- ---------- ----------
CLERK 1300 4
MANAGER 2975 3
SALESMAN 1600 4
-- 사원이 3명이상인 JOB에 대해 JOB별 평균급여를 계산하시오.
SQL> select job, avg(sal) from emp
2 group by job
3 having count(*) > 3;
JOB AVG(SAL)
--------- ----------
CLERK 1037.5
SALESMAN 1400
MAX, MIN함수는 숫자, 문자, 날짜 등 어떠한 자료형 이라도 사용이 가능하다.
MAX([DISTINCT|ALL] expr) : 최대값을 반환한다.
MIN([DISTINCT|ALL] expr) : 최소값을 반환한다.
아래는 sawon 테이블에서 부서별로 급여의 최대, 최소값을 구하는 예문이다.
SQL> select buseo, max(sal) from sawon
6.
2 group bybuseo;
BUSEO MAX(SAL)
---------- ----------
관리부 2000000
영업부 3000000
SQL> select buseo, min(sal) from sawon
2 group by buseo;
BUSEO MIN(SAL)
---------- ----------
관리부 1000000
영업부 2000000
SUM([DISTINCT|ALL] n) : 합계를 반환한다. 인수 n은 테이블의 숫자형 칼럼 이어야 하며 값에
NULL이 포함되어 있을 때는 합계에 포함되지 않는다.
아래는 sawon 테이블에서 급여의 총합, 부서별로 급여의 합을 구하는 예문이다.
SQL> select sum(sal) from sawon;
SUM(SAL)
----------
8000000
SQL> select buseo, sum(sal) from sawon
2 group by buseo;
BUSEO SUM(SAL)
---------- ----------
관리부 3000000
영업부 5000000
--아래 예문은 부서별로 급여의 총합을 출력 하는데 부서의 급여 평균이 1,500,000원 보다 큰 경
우만 출력하는 예문이다.
SQL> select buseo, sum(sal) from sawon
2 group by buseo
7.
3 having avg(sal)> 1500000;
BUSEO SUM(SAL)
---------- ----------
영업부 5000000
-- EMP 테이블에서 JOB별 최고급여를 출력하는데, 최고급여가 높은 것부터 출력하시오.
SQL> select job, max(sal) from emp
2 group by job
3 order by max(sal);
JOB MAX(SAL)
--------- ----------
CLERK 1300
SALESMAN 1600
MANAGER 2975
ANALYST 3000
PRESIDENT 5000
Oracle10g R2부터 Group By절에 의한 자동정렬이 안되는 이유
Oracle 10g R2의 Group By 정렬이 안되는 "New in-Memory Sort Algorithm"에 따른 문제 해결
방법
기존에는 일반 소트 알고리즘 으로 정렬했지만 해시기반 방식으로 소트함으로써 Group By에 정
렬이 안되는 문제가 발생하였음, 대체적으로 group By로 추출되는 데이터는 많지 않으므로
ORDER BY를 사용하면 된다. 소트 알고리즘을 변경함으로써 성능은 10% 전후 향상됨.
기존에 작성된 응용프로그램들에 문제가 발생할 수 있으며 이를 해경하기 위한 방법은 아래 3가
지 정도이다.
-. 오라클 옵티마이저 모드를 RBO 기반으로
-. OPTIMIZER_FEATURES_ENABLE를 10.1 으로
-. 전체 데이터베이스에 적용하기 위해서는 오라클 초기 파라미터 파일(init.ora)
"_gby_hash_aggregation_enabled"=FALSE로 하면 된다.
SQL> alter session set optimizer_mode=RULE;
Session altered.
8.
SQL> select deptno,count(*)from emp group by deptno;
DEPTNO COUNT(*)
---------- ----------
10 3
20 5
30 6
Execution Plan
SQL> alter session set optimizer_mode=all_rows;
Session altered.
SQL> select deptno,count(*) from emp group by deptno;
DEPTNO COUNT(*)
---------- ----------
30 6
20 5
10 3
SQL> alter session set "_gby_hash_aggregation_enabled"=FALSE;
Session altered.
SQL> select deptno,count(*) from emp group by deptno;
DEPTNO COUNT(*)
---------- ----------
10 3
20 5
30 6
ROLLUP 연산자 : GROUP BY구에서 사용되는 연산자로써 그룹조건에 따라 전체를 그룹핑하고 부
분합을 구하는 연산자이다. GROUP BY에 사용된 칼럼수가 N이면 ROLLUP에 의해 생성되는 그룹조
합은 N+1개.
--부서별로 급여의 평균과 모든 부서의 급여 평균을 구하시오.
9.
SQL> select deptno,avg(sal) from emp
2 group by rollup(deptno);
DEPTNO AVG(SAL)
---------- ----------
10 2916.66667
20 2175
30 1566.66667
2073.21429
--job별, deptno별 급여평균, job별 급여평균, 전체급여 평균을 구하시오.
SQL> set pagesize 20
SQL> select job, deptno, avg(sal) from emp
2 group by rollup(job, deptno);
JOB DEPTNO AVG(SAL)
--------- ---------- ----------
CLERK 10 1300
CLERK 20 950
CLERK 30 950
CLERK 1037.5
ANALYST 20 3000
ANALYST 3000
MANAGER 10 2450
MANAGER 20 2975
MANAGER 30 2850
MANAGER 2758.33333
SALESMAN 30 1400
SALESMAN 1400
PRESIDENT 10 5000
PRESIDENT 5000
2073.21429
CUBE 연산자 : GROUP BY구에서 사용되는 연산자로써 그룹조건에 따라 전체를 그룹핑하고 모든
가능한 부분합을 구하는 연산자이다. GROUP BY에 사용된 칼럼수가 N이면 ROLLUP에 의해 생성되
는 그룹조합은 2N개.
10.
--job별, deptno별 급여평균,job별 급여평균, deptnt별 급여평균, 전체급여 평균을 구하시오.
SQL> set pagesize 25
SQL> select job, deptno, avg(sal) from emp
2 group by cube(job, deptno);
JOB DEPTNO AVG(SAL)
--------- ---------- ----------
2073.21429
10 2916.66667
20 2175
30 1566.66667
CLERK 1037.5
CLERK 10 1300
CLERK 20 950
CLERK 30 950
……
SALESMAN 1400
SALESMAN 30 1400
PRESIDENT 5000
PRESIDENT 10 5000
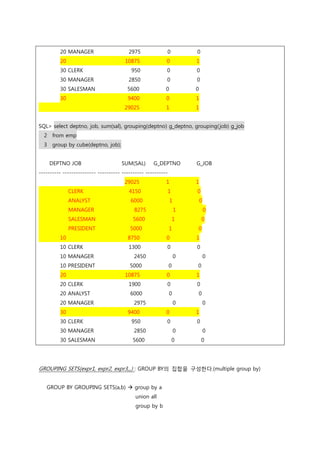
GROUPING(expr) : expr로 지정된 칼럼이 ROLLUP 또는 CUBE 연산자로 생성된 그룹에서 사용되었
는지의 여부를 사용 되었으면 0, 사용되지 않았으면 1로 표시한다.
SQL> column job format a15
SQL> select deptno, job, sum(sal), grouping(deptno) g_deptno, grouping(job) g_job
2 from emp
3 group by rollup(deptno, job);
DEPTNO JOB SUM(SAL) G_DEPTNO G_JOB
---------- --------------- ---------- ---------- ----------
10 CLERK 1300 0 0
10 MANAGER 2450 0 0
10 PRESIDENT 5000 0 0
10 8750 0 1
20 CLERK 1900 0 0
20 ANALYST 6000 0 0
11.
20 MANAGER 29750 0
20 10875 0 1
30 CLERK 950 0 0
30 MANAGER 2850 0 0
30 SALESMAN 5600 0 0
30 9400 0 1
29025 1 1
SQL> select deptno, job, sum(sal), grouping(deptno) g_deptno, grouping(job) g_job
2 from emp
3 group by cube(deptno, job);
DEPTNO JOB SUM(SAL) G_DEPTNO G_JOB
---------- --------------- ---------- ---------- ----------
29025 1 1
CLERK 4150 1 0
ANALYST 6000 1 0
MANAGER 8275 1 0
SALESMAN 5600 1 0
PRESIDENT 5000 1 0
10 8750 0 1
10 CLERK 1300 0 0
10 MANAGER 2450 0 0
10 PRESIDENT 5000 0 0
20 10875 0 1
20 CLERK 1900 0 0
20 ANALYST 6000 0 0
20 MANAGER 2975 0 0
30 9400 0 1
30 CLERK 950 0 0
30 MANAGER 2850 0 0
30 SALESMAN 5600 0 0
GROUPING SETS(expr1, expr2, expr3,,,) : GROUP BY의 집합을 구성한다.(multiple group by)
GROUP BY GROUPING SETS(a,b) group by a
union all
group by b
12.
GROUP BY GROUPINGSETS(a, rollup(b)) group by a
Union all
Group by rollup(b)
SQL> select deptno, job, sum(sal)
2 from emp
3 group by grouping sets ((deptno, job), (job), ())
4 order by 1,2;
DEPTNO JOB SUM(SAL)
------ --------------- ----------
10 CLERK 1300
10 MANAGER 2450
10 PRESIDENT 5000
20 ANALYST 6000
20 CLERK 1900
20 MANAGER 2975
30 CLERK 950
30 MANAGER 2850
30 SALESMAN 5600
ANALYST 6000
CLERK 4150
MANAGER 8275
PRESIDENT 5000
SALESMAN 5600
29025
15 개의 행이 선택되었습니다.
SQL> select deptno, job, sum(sal)
2 from emp
3 group by deptno, job
4 union all
5 select null, job, sum(sal)
6 from emp
7 group by job
8 union all
![SQL초보에서 Schema Objects까지
4.2 집합 함수(Aggreation Function), GROUP BY, HAVING
행(ROW)들의 집합에 대해 연산을 하는 것이므로 행들의 집합 수 만큼 결과가 반환된다. 테이블
은 GROUP BY절에 의해 그룹으로 나누어 질 수 있으며 그룹함수(Aggregation Function)는 SELECT
문과 HAVING절에 사용 되어 질 수 있다. HAVING절은 GROUP BY 되는 함수에 조건을 주기 위해
서 사용 되며 WHERE 절을 이용해서는 안 된다.(그룹핑 칼럼에 조건을 주는 경우는 WHERE절,
HAVING절 모두에서 사용가능 하다.)
GROUP BY절을 이용하여 한 테이블에서 행들을 원하는 그룹으로 나누는 것이 가능하며 칼럼 명
을 집합 함수와 SELECT절에 이용하고자 한다면 GROUP BY 뒤에 칼럼을 추가 해야 한다. 즉
SELECT절에 그룹함수가 오면 SELECT절의 나머지 칼럼은 GROUP BY절에 나타나야 한다. 또한
GROUP BY절에는 칼럼의 위치 순서 표기(1, 2, 3,,,)나 칼럼 Alias는 사용 할 수 없다.
[형식]
SELECT column, group function
FROM TABLE
[WHERE condition]
[GROUP BY [ROLLUP | CUBE] group by expression]
[HAVAING group condition]
[ORDER BY columns]
AVG([DISTINCT|ALL n] : n의 평균값을 반환한다.
SQL> create table sawon (
2 name varchar2(10) not null,
3 sal number(8,0),
4 buseo varchar2(10)
5 );
테이블이 생성되었습니다.
SQL> insert into sawon values ('가길동',2000000,'영업부');
SQL> insert into sawon values ('나길동',3000000, '영업부');
SQL> insert into sawon (name, buseo) values ('다길동','영업부');](https://image.slidesharecdn.com/sqlschemaobjects10-170126021712/85/IT-IT-SQL-IT-10-SQL-Schema-Objects-1-320.jpg)
![SQL초보에서 Schema Objects까지
4.2 집합 함수(Aggreation Function), GROUP BY, HAVING
행(ROW)들의 집합에 대해 연산을 하는 것이므로 행들의 집합 수 만큼 결과가 반환된다. 테이블
은 GROUP BY절에 의해 그룹으로 나누어 질 수 있으며 그룹함수(Aggregation Function)는 SELECT
문과 HAVING절에 사용 되어 질 수 있다. HAVING절은 GROUP BY 되는 함수에 조건을 주기 위해
서 사용 되며 WHERE 절을 이용해서는 안 된다.(그룹핑 칼럼에 조건을 주는 경우는 WHERE절,
HAVING절 모두에서 사용가능 하다.)
GROUP BY절을 이용하여 한 테이블에서 행들을 원하는 그룹으로 나누는 것이 가능하며 칼럼 명
을 집합 함수와 SELECT절에 이용하고자 한다면 GROUP BY 뒤에 칼럼을 추가 해야 한다. 즉
SELECT절에 그룹함수가 오면 SELECT절의 나머지 칼럼은 GROUP BY절에 나타나야 한다. 또한
GROUP BY절에는 칼럼의 위치 순서 표기(1, 2, 3,,,)나 칼럼 Alias는 사용 할 수 없다.
[형식]
SELECT column, group function
FROM TABLE
[WHERE condition]
[GROUP BY [ROLLUP | CUBE] group by expression]
[HAVAING group condition]
[ORDER BY columns]
AVG([DISTINCT|ALL n] : n의 평균값을 반환한다.
SQL> create table sawon (
2 name varchar2(10) not null,
3 sal number(8,0),
4 buseo varchar2(10)
5 );
테이블이 생성되었습니다.
SQL> insert into sawon values ('가길동',2000000,'영업부');
SQL> insert into sawon values ('나길동',3000000, '영업부');
SQL> insert into sawon (name, buseo) values ('다길동','영업부');](https://image.slidesharecdn.com/sqlschemaobjects10-170126021712/75/IT-IT-SQL-IT-10-SQL-Schema-Objects-1-2048.jpg)


![COUNT({* | [DISTINCT|ALL] expr}) : 추출된 행(ROW)수를 반환한다. DISTINCT를 사용 했다면 중복된
행을 제거한 행수를 반환하고 ,expr을 사용 했다면 expr이 NOT NULL인 행의 수를 반환한다.
ASTERISK(*)는 중복 과 NULL을 포함한 모든 행의 수를 반환 할 때 사용한다.
SQL> select name, sal, buseo from sawon;
NAME SAL BUSEO
---------- ---------- ----------
가길동 2000000 영업부
나길동 3000000 영업부
다길동 영업부
라길동 1000000 관리부
마길동 2000000 관리부
--“다길동” 사원은 sal를 등록하지 않았으니 NULL 임을 기억하자.
SQL> select count(sal) from sawon;
COUNT(SAL)
----------
4
SQL> select count(distinct sal) from sawon;
COUNT(DISTINCTSAL)
------------------
3
--아래의 ASTERISK(*)는 결국 테이블등의 전체 건수를 파악 할 때 자주 사용 된다.
SQL> select count(*) from sawon;
COUNT(*)
----------
5
--다음 예문은 부서별로 인원 수를 출력 하는 예문이다.
SQL> select buseo, count(buseo)||'명' from sawon
2 group by buseo;](https://image.slidesharecdn.com/sqlschemaobjects10-170126021712/85/IT-IT-SQL-IT-10-SQL-Schema-Objects-4-320.jpg)
![BUSEO COUNT(BUSEO)||'명'
---------- -----------------------------------------
관리부 2명
영업부 3명
--각 직무별로 최대급여와 인원수를 구하되 직무별 인원수가 2명 이상인 직무
만 나타내는 예문이다. (평균급여의 소수점 이하는 반올림)
SQL> select job "직무", round(max(sal)) "최대 급여", count(*) "인원수"
2 from emp
3 group by job
4 having count(*)>2;
직무 최대 급여 인원수
--------- ---------- ----------
CLERK 1300 4
MANAGER 2975 3
SALESMAN 1600 4
-- 사원이 3명이상인 JOB에 대해 JOB별 평균급여를 계산하시오.
SQL> select job, avg(sal) from emp
2 group by job
3 having count(*) > 3;
JOB AVG(SAL)
--------- ----------
CLERK 1037.5
SALESMAN 1400
MAX, MIN함수는 숫자, 문자, 날짜 등 어떠한 자료형 이라도 사용이 가능하다.
MAX([DISTINCT|ALL] expr) : 최대값을 반환한다.
MIN([DISTINCT|ALL] expr) : 최소값을 반환한다.
아래는 sawon 테이블에서 부서별로 급여의 최대, 최소값을 구하는 예문이다.
SQL> select buseo, max(sal) from sawon](https://image.slidesharecdn.com/sqlschemaobjects10-170126021712/85/IT-IT-SQL-IT-10-SQL-Schema-Objects-5-320.jpg)
![2 group by buseo;
BUSEO MAX(SAL)
---------- ----------
관리부 2000000
영업부 3000000
SQL> select buseo, min(sal) from sawon
2 group by buseo;
BUSEO MIN(SAL)
---------- ----------
관리부 1000000
영업부 2000000
SUM([DISTINCT|ALL] n) : 합계를 반환한다. 인수 n은 테이블의 숫자형 칼럼 이어야 하며 값에
NULL이 포함되어 있을 때는 합계에 포함되지 않는다.
아래는 sawon 테이블에서 급여의 총합, 부서별로 급여의 합을 구하는 예문이다.
SQL> select sum(sal) from sawon;
SUM(SAL)
----------
8000000
SQL> select buseo, sum(sal) from sawon
2 group by buseo;
BUSEO SUM(SAL)
---------- ----------
관리부 3000000
영업부 5000000
--아래 예문은 부서별로 급여의 총합을 출력 하는데 부서의 급여 평균이 1,500,000원 보다 큰 경
우만 출력하는 예문이다.
SQL> select buseo, sum(sal) from sawon
2 group by buseo](https://image.slidesharecdn.com/sqlschemaobjects10-170126021712/85/IT-IT-SQL-IT-10-SQL-Schema-Objects-6-320.jpg)







![[구로IT학원추천/구로디지털단지IT학원/국비지원IT학원/재직자/구직자환급교육]#9.SQL초보에서 Schema Objects까지](https://cdn.slidesharecdn.com/ss_thumbnails/sqlschemaobjects9-170126020830-thumbnail.jpg?width=640&height=640&fit=bounds)

![[오라클교육/SQL교육/IT교육/실무중심교육학원추천_탑크리에듀]#4.SQL초보에서 Schema Objectes까지](https://cdn.slidesharecdn.com/ss_thumbnails/sqlschemaobjects4-170123085836-thumbnail.jpg?width=640&height=640&fit=bounds)













![[오라클교육/닷넷교육/자바교육/SQL기초/스프링학원/국비지원학원/자마린교육]#16.SQL초보에서 Schema Objects까지](https://cdn.slidesharecdn.com/ss_thumbnails/sqlschemaobjects16-170203081623-thumbnail.jpg?width=640&height=640&fit=bounds)












![[ 너의 꿈에 미쳐라 !! ] _ 오라클 학원/자바 학원/구로 학원/ 탑크리에듀 교육센터](https://cdn.slidesharecdn.com/ss_thumbnails/random-170131052727-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ 당신의 성공을 막는 거짓말 13 ]_ 오라클학원/ 자바학원/ 구로학원/ IT학원/ 탑크리에듀교육센터](https://cdn.slidesharecdn.com/ss_thumbnails/random-170131054236-thumbnail.jpg?width=640&height=640&fit=bounds)

![직장인을 위한 스펙업제도 [재직자 내일배움카드] _오라클학원/ 자바학원/ 구로학원/ IT학원/ 탑크리에듀교육센터](https://cdn.slidesharecdn.com/ss_thumbnails/random-170131055341-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[IT교육/IT학원]Develope를 위한 IT실무교육](https://cdn.slidesharecdn.com/ss_thumbnails/random-180126054238-thumbnail.jpg?width=640&height=640&fit=bounds)
![[아이오닉학원]아이오닉 하이브리드 앱 개발 과정(아이오닉2로 동적 모바일 앱 만들기)](https://cdn.slidesharecdn.com/ss_thumbnails/2-180116062601-thumbnail.jpg?width=640&height=640&fit=bounds)
![[뷰제이에스학원]뷰제이에스(Vue.js) 프로그래밍 입문(프로그레시브 자바스크립트 프레임워크)](https://cdn.slidesharecdn.com/ss_thumbnails/vue-180116043929-thumbnail.jpg?width=640&height=640&fit=bounds)
![[씨샵학원/씨샵교육]C#, 윈폼, 네트워크, ado.net 실무프로젝트 과정](https://cdn.slidesharecdn.com/ss_thumbnails/cado-180116013552-thumbnail.jpg?width=640&height=640&fit=bounds)
![[정보처리기사자격증학원]정보처리기사 취득 양성과정(국비무료 자격증과정)](https://cdn.slidesharecdn.com/ss_thumbnails/random-180116010303-thumbnail.jpg?width=640&height=640&fit=bounds)
![[wpf학원,wpf교육]닷넷, c#기반 wpf 프로그래밍 인터페이스구현 재직자 향상과정](https://cdn.slidesharecdn.com/ss_thumbnails/11-180102064615-thumbnail.jpg?width=640&height=640&fit=bounds)

![[자마린교육/자마린실습]자바,스프링프레임워크(스프링부트) RESTful 웹서비스 구현 실습,자마린에서 스프링 웹서비스를 호출하고 응답 JS...](https://cdn.slidesharecdn.com/ss_thumbnails/restfuljson-171119094451-thumbnail.jpg?width=640&height=640&fit=bounds)
![[구로자마린학원/자마린강좌/자마린교육]3. xamarin.ios 3.3.5 추가적인 사항](https://cdn.slidesharecdn.com/ss_thumbnails/3-171109005415-thumbnail.jpg?width=640&height=640&fit=bounds)




![자바, 웹 기초와 스프링 프레임워크 & 마이바티스 재직자 향상과정(자바학원/자바교육/자바기업출강]](https://cdn.slidesharecdn.com/ss_thumbnails/01-171017011030-thumbnail.jpg?width=640&height=640&fit=bounds)

![3. 안드로이드 애플리케이션 구성요소 3.2인텐트 part01(안드로이드학원/안드로이드교육/안드로이드강좌/안드로이드기업출강]](https://cdn.slidesharecdn.com/ss_thumbnails/3-171010074659-thumbnail.jpg?width=640&height=640&fit=bounds)
