Download as PDF, PPTX







![SCHEMAGroup2015–Allrightsreserved
Our context is not the Lone
Technical Content Ranger
All arguments in this talk assume that we are talking
about the processes and needs of large technical content
department operating at a high level of maturity.
We are not talking about the perspective of the Lone
Technical Content Ranger.
Russell Ward presented this perspective in his great
talk last year here at tekom 2014:
Five reasons not to use DITA
[http://conferences.tekom.de/fileadmin/tx_doccon/slides/742_5_Reasons_Not_to_Use_DITA.pdf]](https://image.slidesharecdn.com/2015-11-105reasonsnottousedita-151117094013-lva1-app6891/75/5-Reasons-not-to-use-Dita-from-a-CCMS-Perspective-8-2048.jpg)




![SCHEMAGroup2015–Allrightsreserved
Requirements Coverage of
XML, DITA and CCMS
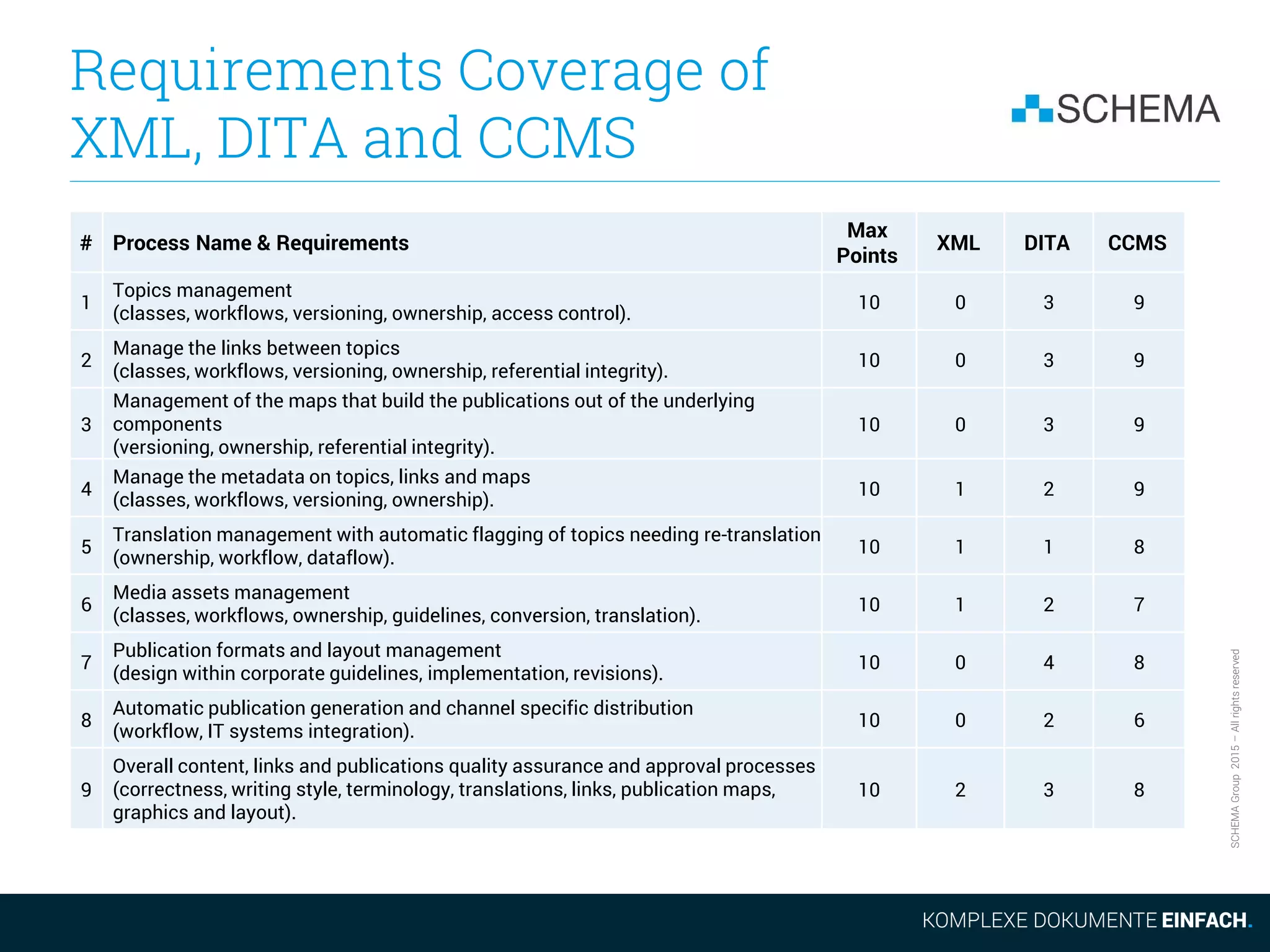
# Process Name & Requirements
Max
Points
XML DITA CCMS
10
Information model management
(conceptual design, classes, roles, rights, workflows, evolution).
10 0 2 9
11
Performance & costs management
(financial controlling, key performance indicators monitoring, tracking, corrective
actions)
10 0 2 4
12
Security
(user management, user roles, access control, change tracking).
10 0 0 8
13
IT and software infrastructure management
(change, updates and upgrades).
10 0 0 4
14
Manage the communication with adjacent departments, like product
management, engineering and marketing
(responsibilities, workflows).
10 0 0 3
15
Team management
(skills, training, structure, responsibilities, motivation).
10 0 0 0
Coverage [Points] 150 5 27 101
Coverage [Percent] 3% 18% 67%
Coverage with CCMS baseline [Percent] 27% 100%](https://image.slidesharecdn.com/2015-11-105reasonsnottousedita-151117094013-lva1-app6891/75/5-Reasons-not-to-use-Dita-from-a-CCMS-Perspective-14-2048.jpg)
![SCHEMAGroup2015–Allrightsreserved
Requirements Coverage of
XML, DITA and CCMS
XML DITA CCMS
[DITA]
CCMS
[DERCOM]
Business
Logic in
DITA
Open
Toolkit
Business
Logic in
Database,
Workflow
System,
TMS
Interfaces,
Media
Assets
Management,
etc
Non-DITA CCMSs bonus for
being on the market for at
least 10 years longer
?](https://image.slidesharecdn.com/2015-11-105reasonsnottousedita-151117094013-lva1-app6891/75/5-Reasons-not-to-use-Dita-from-a-CCMS-Perspective-15-2048.jpg)





![SCHEMAGroup2015–Allrightsreserved
How is a DITA Topic
Represented in a File System?
TOP
[XML]
DITA
Topic
File
File Metadata
(Name, Owner,
LastWriteDate, …)
Metadata within
XML DITA Topic
(class, author,
target audience, …)
XML
Content](https://image.slidesharecdn.com/2015-11-105reasonsnottousedita-151117094013-lva1-app6891/75/5-Reasons-not-to-use-Dita-from-a-CCMS-Perspective-21-2048.jpg)
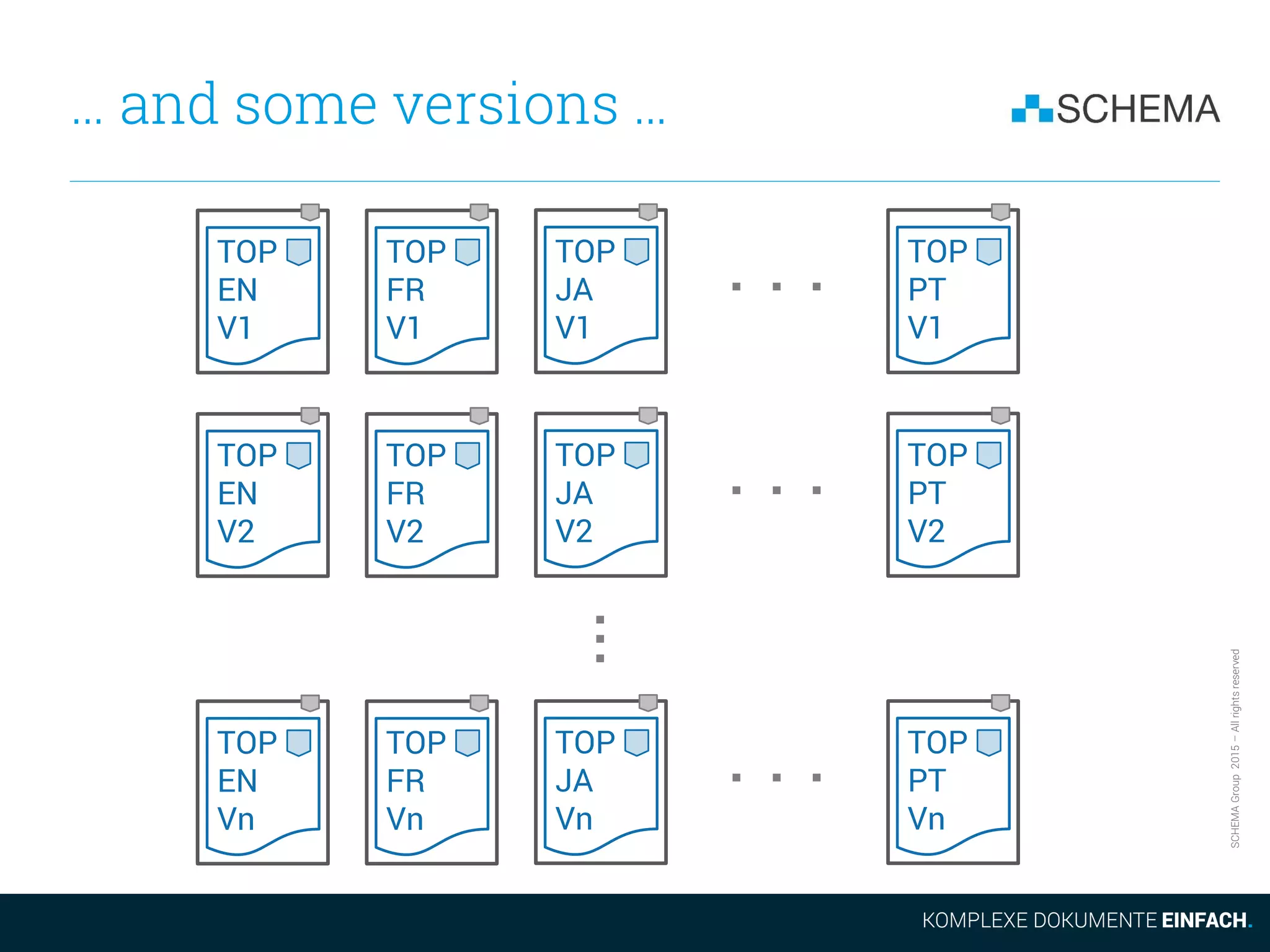
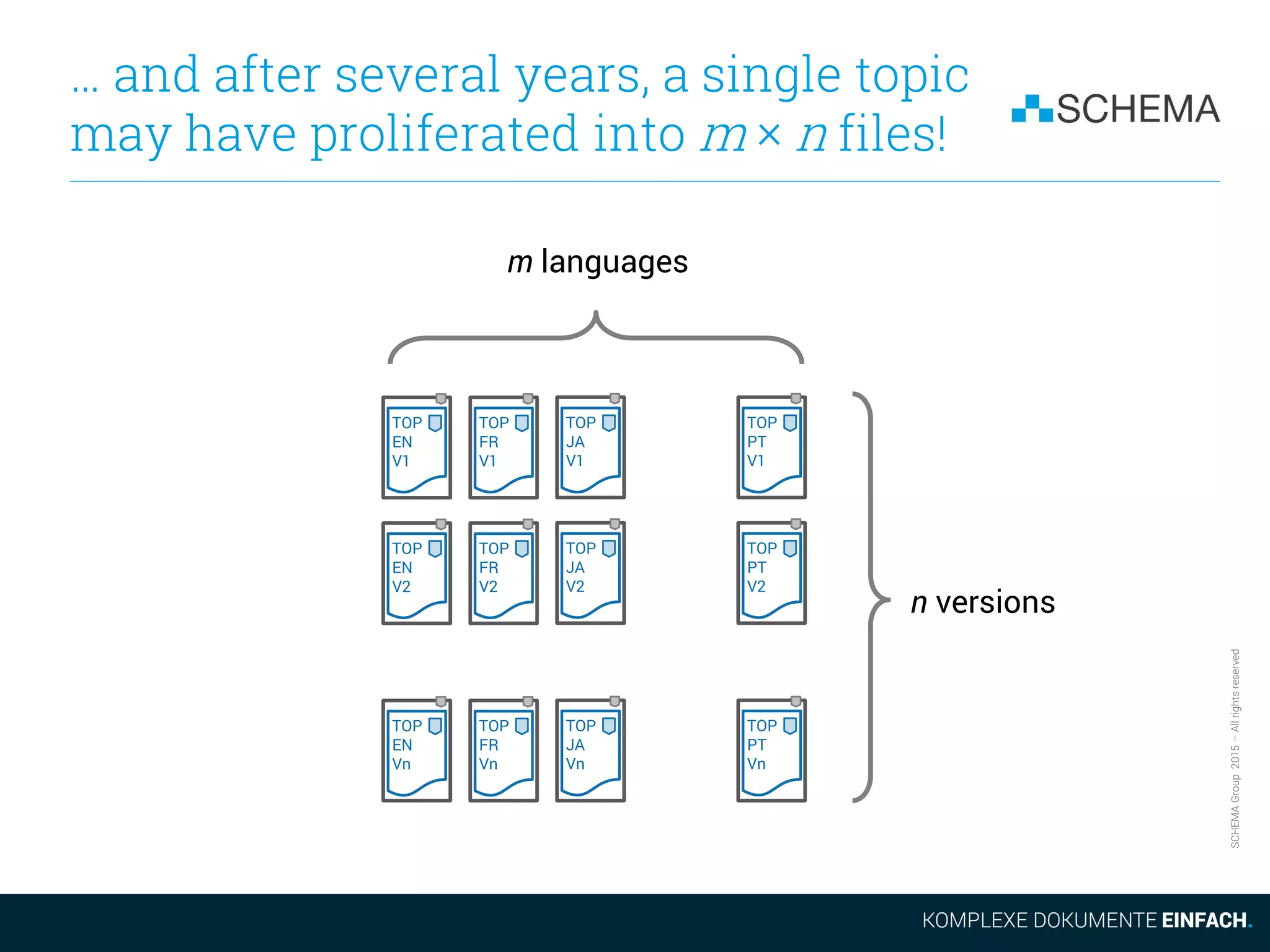

![SCHEMAGroup2015–Allrightsreserved
How m × n Topics are
Accessed in a CCMS
In a CCMS implemented on top of a database, all these m × n
topics can be addressed with a single key:
[ID_Intro, Language, LatestReleasedVersion]
where Language and LatestReleasedVersion are variables,
that the system will automatically populate as needed.
In Computer Science this is called a composite key, and was
invented over 45 years ago at IBM.
Composite keys capture and optimally encode the regularities in
the target domain and let the computer do the tedious book-
keeping. This is what computers are good at!](https://image.slidesharecdn.com/2015-11-105reasonsnottousedita-151117094013-lva1-app6891/75/5-Reasons-not-to-use-Dita-from-a-CCMS-Perspective-26-2048.jpg)
![SCHEMAGroup2015–Allrightsreserved
How m × n Topics are Accessed
by the Author in a CCMS
Authors will rarely need to see, insert or handle
full CCMS composite topic keys:
[ID_Intro, Language, LatestReleasedVersion]
Since the composite key structure is universal within the system,
there is no need to explicitly represent the variable parts. They are
optional and will be implicitly added at document aggregation time.
What the author sees and handles is just:
[ID_Intro]
And, of course, usually even this is hidden by the GUI.](https://image.slidesharecdn.com/2015-11-105reasonsnottousedita-151117094013-lva1-app6891/75/5-Reasons-not-to-use-Dita-from-a-CCMS-Perspective-27-2048.jpg)




![SCHEMAGroup2015–Allrightsreserved
Representation of a
Graphic in a CCMS
Neutral
GRAPHIC
Graphic
container
Language
container
Format
container V1
Vector [SVG]
Graphics
file
V2 Vn
V1
Pixel [PNG]
V2 Vn
V1
Source
V2 Vn
EN
V1
Vector [SVG]
V2 Vn
V1
Pixel [PNG]
V2 Vn
V1
Source
V2 Vn
PT
V1
Vector [SVG]
V2 Vn
V1
Pixel [PNG]
V2 Vn
V1
Source
V2 Vn](https://image.slidesharecdn.com/2015-11-105reasonsnottousedita-151117094013-lva1-app6891/75/5-Reasons-not-to-use-Dita-from-a-CCMS-Perspective-32-2048.jpg)
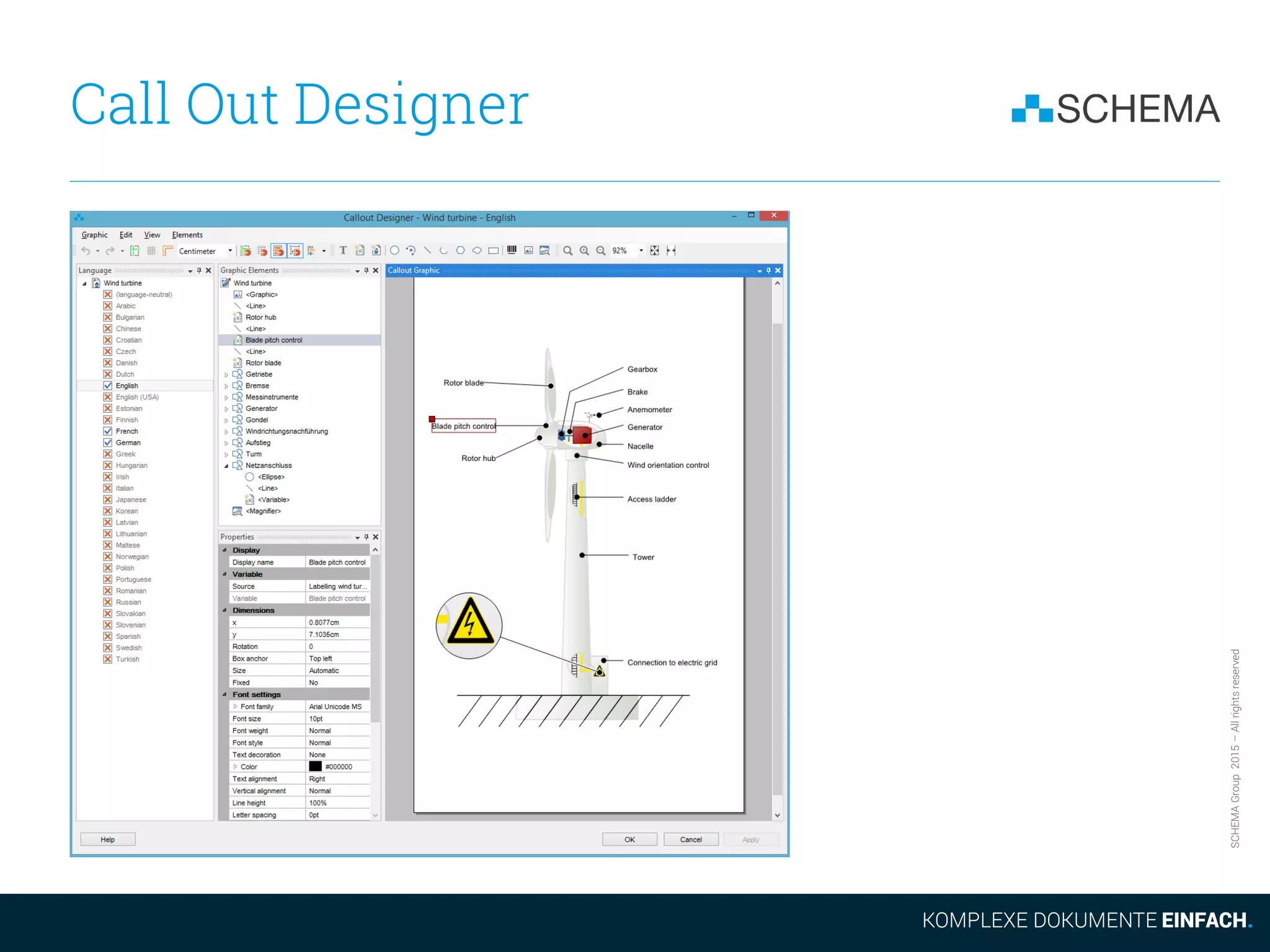
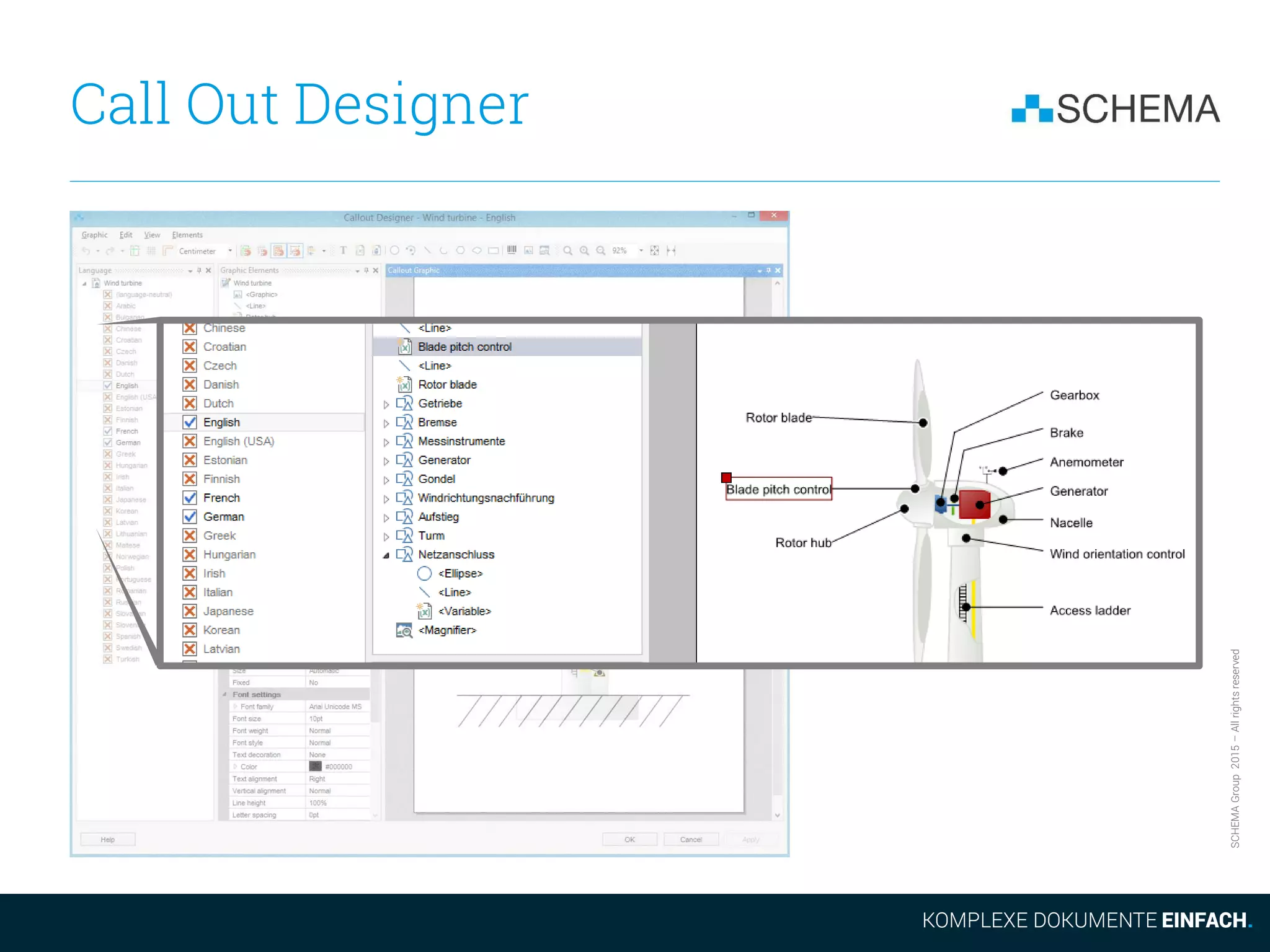















The document discusses some of the drawbacks of using DITA from the perspective of a large content management system (CCMS). It notes that DITA's coverage of core CCMS requirements is surprisingly small, addressing only 18% of requirements compared to 67% for a typical CCMS. It also argues that the evolution of the DITA standard is too slow given market demands. Additionally, it outlines how DITA deals with the proliferation of files as content is translated and new versions are created, noting this can result in many files versus a single topic accessed differently in a CCMS.


































































