Download as PDF, PPTX





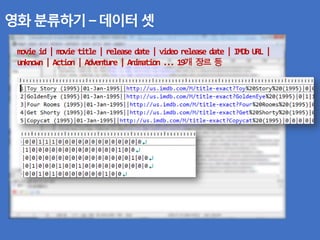



![영화 분류하기 – 클러스터링
K-Means 과정
- 데이터 셋 만들다(Vector)
[0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, Toy Story (1995)]
[0.0, 0.0, 1.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, GoldenEye (1995)]
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, Four Rooms (1995)]
[0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, Get Shorty (1995)]
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, Copycat (1995)]
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, Shanghai Triad (Yao a yao yao
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, Twelve Monkeys (1995)]
[0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, Babe (1995)]
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, Dead Man Walking (1995)]
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, Richard III (1995)]
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, Seven (Se7en) (1995)]
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, Usual Suspects, The (1995)]
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, Mighty Aphrodite (1995)]
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, Postino, Il (1994)]
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, Mr. Holland's Opus (1995)]
.
.
.
[0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, From Dusk Till Dawn (1996)]
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, White Balloon, The (1995)]
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, Antonia's Line (1995)]
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, Angels and Insects (1995)]
[0.0, 0.0, 1.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, Muppet Treasure Island (1996)
[0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, Braveheart (1995)]](https://image.slidesharecdn.com/4-140527061618-phpapp01/85/4-10-320.jpg)

![영화 분류하기 – 클러스터링
K-Means 과정
- 초기 Centro-id 결정 : 무작위 결정
[0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, Toy Story (1995)]
[0.0, 0.0, 1.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, GoldenEye (1995)]
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, Four Rooms (1995)]
[0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, Get Shorty (1995)]
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, Copycat (1995)]
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, Twelve Monkeys (1995)]
[0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, Babe (1995)]
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, Dead Man Walking (1995)]
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, Richard III (1995)]
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, Seven (Se7en) (1995)]
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, Usual Suspects, The (1995)]
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, Mighty Aphrodite (1995)]
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, Postino, Il (1994)
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, Mr. Holland's Opus (1995)]
.
.
.
[0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, From Dusk Till Dawn (1996)]
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, White Balloon, The (1995)]
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, Antonia's Line (1995)]
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, Angels
[0.0, 0.0, 1.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, Muppet Treasure Island (1996)
[0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, Braveheart (1995)]
1번클러스터Centro-id
2번클러스터Centro-id
3번클러스터Centro-id](https://image.slidesharecdn.com/4-140527061618-phpapp01/85/4-12-320.jpg)
![영화 분류하기 – 클러스터링
K-Means 과정
- Centro-id1,2,3과데이터 셋의 유사도 측정
0.0, 0.0, 0.0, 0.0, 1.0, 0.0,
Toy Story (1995)]
1번클러스터Centro-id1
2번클러스터Centro-id2
3번클러스터Centro-id3
유사도계산0.95
0.85
0.98](https://image.slidesharecdn.com/4-140527061618-phpapp01/85/4-13-320.jpg)
![영화 분류하기 – 클러스터링
K-Means 과정
- 가까운 Centro-id의 클러스터링 묶음
0.0, 0.0, 0.0, 0.0, 0.0, Toy Story (1995)]
0.0, 0.0, 1.0, 0.0, 0.0, GoldenEye (1995)]
0.0, 0.0, 1.0, 0.0, 0.0, Four Rooms (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Get Shorty (1995)]
0.0, 0.0, 1.0, 0.0, 0.0, Copycat (1995)]
0.0, 1.0, 0.0, 0.0, 0.0, Twelve Monkeys (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Babe (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Dead Man Walking (1995)]
0.0, 0.0, 0.0, 1.0, 0.0, Richard III (1995)]
0.0, 0.0, 1.0, 0.0, 0.0, Seven (Se7en) (1995)]
0.0, 0.0, 1.0, 0.0, 0.0, Usual Suspects, The (1995)
0.0, 0.0, 0.0, 0.0, 0.0, Mighty Aphrodite (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Mr. Holland's Opus (1995)]
1번클러스터Centro-id1
0.0, 0.0, 1.0, 0.0, 0.0, Usual Suspects, The (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Mighty Aphrodite (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Mr. Holland's Opus (1995)]
2번클러스터Centro-id2
0.0, 1.0, 0.0, 0.0, 0.0, Twelve Monkeys (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Babe (1995)]
3번클러스터Centro-id3
0.0, 0.0, 0.0, 0.0, 0.0, Toy Story (1995)]
0.0, 0.0, 1.0, 0.0, 0.0, GoldenEye (1995)]
0.0, 0.0, 1.0, 0.0, 0.0, Four Rooms (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Get Shorty (1995)]](https://image.slidesharecdn.com/4-140527061618-phpapp01/85/4-14-320.jpg)
![영화 분류하기 – 클러스터링
K-Means 과정
- 클러스터링된 데이터셋의 중심값 구하기
1번클러스터Centro-id1
0.0, 0.0, 1.0, 0.0, 0.0, Usual Suspects, The (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Mighty Aphrodite (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Mr. Holland's Opus (1995)]
0.0, 0.0, 1.0, 0.0, 0.0, Usual Suspects, The (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Mighty Aphrodite (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Mr. Holland's Opus (1995)]
2번클러스터Centro-id2
0.0, 1.0, 0.0, 0.0, 0.0, Twelve Monkeys (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Babe (1995)]
3번클러스터Centro-id3
0.0, 0.0, 0.0, 0.0, 0.0, Toy Story (1995)]
0.0, 0.0, 1.0, 0.0, 0.0, GoldenEye (1995)]
0.0, 0.0, 1.0, 0.0, 0.0, Four Rooms (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Get Shorty (1995)]
0.0, 0.3, 1.0, 0.0, 0.1,
0.0, 1.0, 1.0, 0.8, 0.0,
0.9, 0.0, 1.0, 0.0, 0.3,](https://image.slidesharecdn.com/4-140527061618-phpapp01/85/4-15-320.jpg)

![영화 분류하기 – 클러스터링
K-Means 과정
- new Centro-id로 다시 클러스터링 실행
0.0, 0.0, 0.0, 0.0, 0.0, Toy Story (1995)]
0.0, 0.0, 1.0, 0.0, 0.0, GoldenEye (1995)]
0.0, 0.0, 1.0, 0.0, 0.0, Four Rooms (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Get Shorty (1995)]
0.0, 0.0, 1.0, 0.0, 0.0, Copycat (1995)]
0.0, 1.0, 0.0, 0.0, 0.0, Twelve Monkeys (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Babe (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Dead Man Walking (1995)]
0.0, 0.0, 0.0, 1.0, 0.0, Richard III (1995)]
0.0, 0.0, 1.0, 0.0, 0.0, Seven (Se7en) (1995)]
0.0, 0.0, 1.0, 0.0, 0.0, Usual Suspects, The (1995)
0.0, 0.0, 0.0, 0.0, 0.0, Mighty Aphrodite (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Mr. Holland's Opus (1995)]
1번클러스터Centro-id1
0.0, 0.0, 1.0, 0.0, 0.0, Usual Suspects, The (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Mighty Aphrodite (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Mr. Holland's Opus (1995)]
2번클러스터Centro-id2
0.0, 1.0, 0.0, 0.0, 0.0, Twelve Monkeys (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Babe (1995)]
3번클러스터Centro-id3
0.0, 0.0, 0.0, 0.0, 0.0, Toy Story (1995)]
0.0, 0.0, 1.0, 0.0, 0.0, GoldenEye (1995)]
0.0, 0.0, 1.0, 0.0, 0.0, Four Rooms (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Get Shorty (1995)]](https://image.slidesharecdn.com/4-140527061618-phpapp01/85/4-17-320.jpg)
![영화 분류하기 – 클러스터링
K-Means 과정
- 클러스터링된 데이터셋의 다시 중심값 구하기
1번클러스터Centro-id1
0.0, 0.0, 1.0, 0.0, 0.0, Usual Suspects, The (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Mighty Aphrodite (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Mr. Holland's Opus (1995)]
0.0, 0.0, 1.0, 0.0, 0.0, Usual Suspects, The (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Mighty Aphrodite (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Mr. Holland's Opus (1995)]
2번클러스터Centro-id2
0.0, 1.0, 0.0, 0.0, 0.0, Twelve Monkeys (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Babe (1995)]
3번클러스터Centro-id3
0.0, 0.0, 0.0, 0.0, 0.0, Toy Story (1995)]
0.0, 0.0, 1.0, 0.0, 0.0, GoldenEye (1995)]
0.0, 0.0, 1.0, 0.0, 0.0, Four Rooms (1995)]
0.0, 0.0, 0.0, 0.0, 0.0, Get Shorty (1995)]
0.0, 0.3, 1.0, 0.0, 0.1,
0.0, 1.0, 1.0, 0.8, 0.0,
0.9, 0.0, 1.0, 0.0, 0.3,](https://image.slidesharecdn.com/4-140527061618-phpapp01/85/4-18-320.jpg)





The document discusses clustering movies by genre using k-means clustering. It extracts genre information from a movie dataset and represents each movie as a vector of its genres. It then applies k-means clustering with k=3 clusters to group similar movies together based on their genre vectors. The document outlines the k-means clustering process, including initializing cluster centroids randomly and repeatedly assigning movies to their closest centroid cluster until the clusters stabilize.









![[1D2]아이비컨과 공유기 해킹을 통한 인도어 IOT 삽질기](https://cdn.slidesharecdn.com/ss_thumbnails/1d2iot-140927230515-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2D4]Python에서의 동시성_병렬성](https://cdn.slidesharecdn.com/ss_thumbnails/2d4pythondeview2014-140929211011-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224] backend 개발자의 neural machine translation 개발기 김상경](https://cdn.slidesharecdn.com/ss_thumbnails/224backendneuralmachinetranslation-161025025107-thumbnail.jpg?width=640&height=640&fit=bounds)


![[1D4]오타 수정과 편집 기능을 가진 Android Keyboard Service 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/1d4androidkeyboardservice-140928192141-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


![[2A1]Line은 어떻게 글로벌 메신저 플랫폼이 되었는가](https://cdn.slidesharecdn.com/ss_thumbnails/2a1line-140929191515-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


![[2B4]Live Broadcasting 추천시스템](https://cdn.slidesharecdn.com/ss_thumbnails/2b4livebroadcasting-140929210948-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[1B5]github first-principles](https://cdn.slidesharecdn.com/ss_thumbnails/1b5github-first-principles-140929003833-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[1A1]행복한프로그래머를위한철학](https://cdn.slidesharecdn.com/ss_thumbnails/1a1-140927225723-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2C4]Clustered computing with CoreOS, fleet and etcd](https://cdn.slidesharecdn.com/ss_thumbnails/2c4clusteredcomputingwithcoreosfleetandetcd-140929235711-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[2C5]Map-D: A GPU Database for Interactive Big Data Analytics](https://cdn.slidesharecdn.com/ss_thumbnails/2c5map-dagpudatabaseforinteractivebigdataanalytics-140930010539-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



![[데이터야놀자2107] 강남 출근길에 판교/정자역에 내릴 사람 예측하기](https://cdn.slidesharecdn.com/ss_thumbnails/predict-get-off-station-171012210042-thumbnail.jpg?width=640&height=640&fit=bounds)





















