More Related Content

PDF
Implementing AI: High Performance Architectures: Arm SVE and Supercomputer Fu... 
PDF
Arm tools and roadmap for SVE compiler support 
PDF

PDF
Vector Codegen in the RISC-V Backend 
PDF
MOVED: The challenge of SVE in QEMU - SFO17-103 
PDF
An evaluation of LLVM compiler for SVE with fairly complicated loops 
PDF

PDF
Q4.11: Using GCC Auto-Vectorizer Similar to 3 - Intro to SVE.pdf for intro ARM SVE part

PDF
Vectorization on x86: all you need to know 
PDF
Pragmatic Optimization in Modern Programming - Mastering Compiler Optimizations 
PDF
Дмитрий Вовк: Векторизация кода под мобильные платформы 
PPTX
Fedor Polyakov - Optimizing computer vision problems on mobile platforms 
PDF
Andes RISC-V vector extension demystified-tutorial 
PPTX
Evgeniy Muralev, Mark Vince, Working with the compiler, not against it 
PPTX

PPTX
Introduction to armv8 aarch64 
PPTX
Code vectorization for mobile devices 
PPTX
GDC2014: Boosting your ARM mobile 3D rendering performance with Umbra 
PDF

PDF
Running Java on Arm - Is it worth it in 2025? 
PDF
Lecture Presentation 9.pdf fpga soc using c 
PDF
Cloud, Distributed, Embedded: Erlang in the Heterogeneous Computing World 
PDF

PPTX
Embedded C programming session10 
PPTX
PVS-Studio. Static code analyzer. Windows/Linux, C/C++/C#. 2017 
PDF

PDF

PDF
More from JunZhao68

PDF
语法专题3-状语从句.pdf 英语语法基础部分,涉及到状语从句部分的内容来米爱上 
PDF
愛小孩的歐拉一 兼論 108 數學課綱.pdf for 欧拉&数论相关课程描述啊 
PDF
svd15_86.pdf for SVD study and revosited 
PDF
Quadra-T1-T2-T4_TechSpec.pdf for netint VPA 
PDF
Python Advanced Course - part III.pdf for Python 
PDF
Python Advanced Course - part I.pdf for Python 
PDF
pytorch-cheatsheet.pdf for ML study with pythroch 
PDF
Vocabulary Cards for AI and KIDs MIT.pdf 
PDF
how CNN works for tech Every parts introductions.pdf 
PDF
eics22-slides for researchers need when implementing novel imteraction tech 
PDF
Netflix-talk for live video streaming tech 
PPTX
Linear system 1_linear in linear algebra.pptx 
PDF
GDC2012 JMV Rotations with jim van verth 
PDF
1-MIV-tutorial-part-1.pdf 
PDF
GOP-Size_report_11_16.pdf 
PDF
02-VariableLengthCodes_pres.pdf 
PDF
MHV-Presentation-Forman (1).pdf 
PDF

PDF
http3-quic-streaming-2020-200121234036.pdf 
PDF
Recently uploaded

PPTX
Detailed_Acute_Severe_Asthma_Paediatrics_PPT.pptx 
PPTX
Jim-Nitterauer-Decrypting-the-Mess-that-is-SSL-TLS-Negotiation-Preparing-for-... 
PDF
Ford_3415_Operational and Maintenance Manual 
PDF
Agent-Based Automation of Collaborative Software Development: Current Status ... 
PDF
John Deere CT322 Compact Track Loader Service Repair Manual (TM2152).pdf 
PPTX
OMNICARE PITCH DECK FINAL a robot designed 
PDF
G11-IT(2).PDF Information Technology grade 11th new curriculum book 
PPTX
generate electricty by wa91502_0000.pptx 
PPTX
Untitled design_20251202_192002_00000000 
PDF
624J John Deere Loader Operation and Test Technical Manual.pdf 
DOCX
24/7 QuickBooks Support near me in San Jose.docx 
PPTX
Data-Communication-Connecting-the-Digital-World.pptx 
PDF
GreenRoute_Presentation_CE-UY4833_FV.pdf 
PDF
Assessment of One's Teaching Practice.pdf 
PDF
AI and the llllladaoinadgagasdgoiannnnnnn 
PPTX
Omron offers comprehensive Radio Frequency Identification (RFID) systems, inc... 
PDF
240222 LG Multi V Catalogue_low.pdffdffdffdwfdfdsfdfewffgegg 
PDF
Protection against banking and financial frauds-1.pdf 
PDF
Sensor LSI Cat.pdf INSTALALACION Y CALIBRACION 
PPTX
State University of New York at Buffalo Diploma 3 - Intro to SVE.pdf for intro ARM SVE part
- 1.
- 2.
2 © 2019Arm Limited
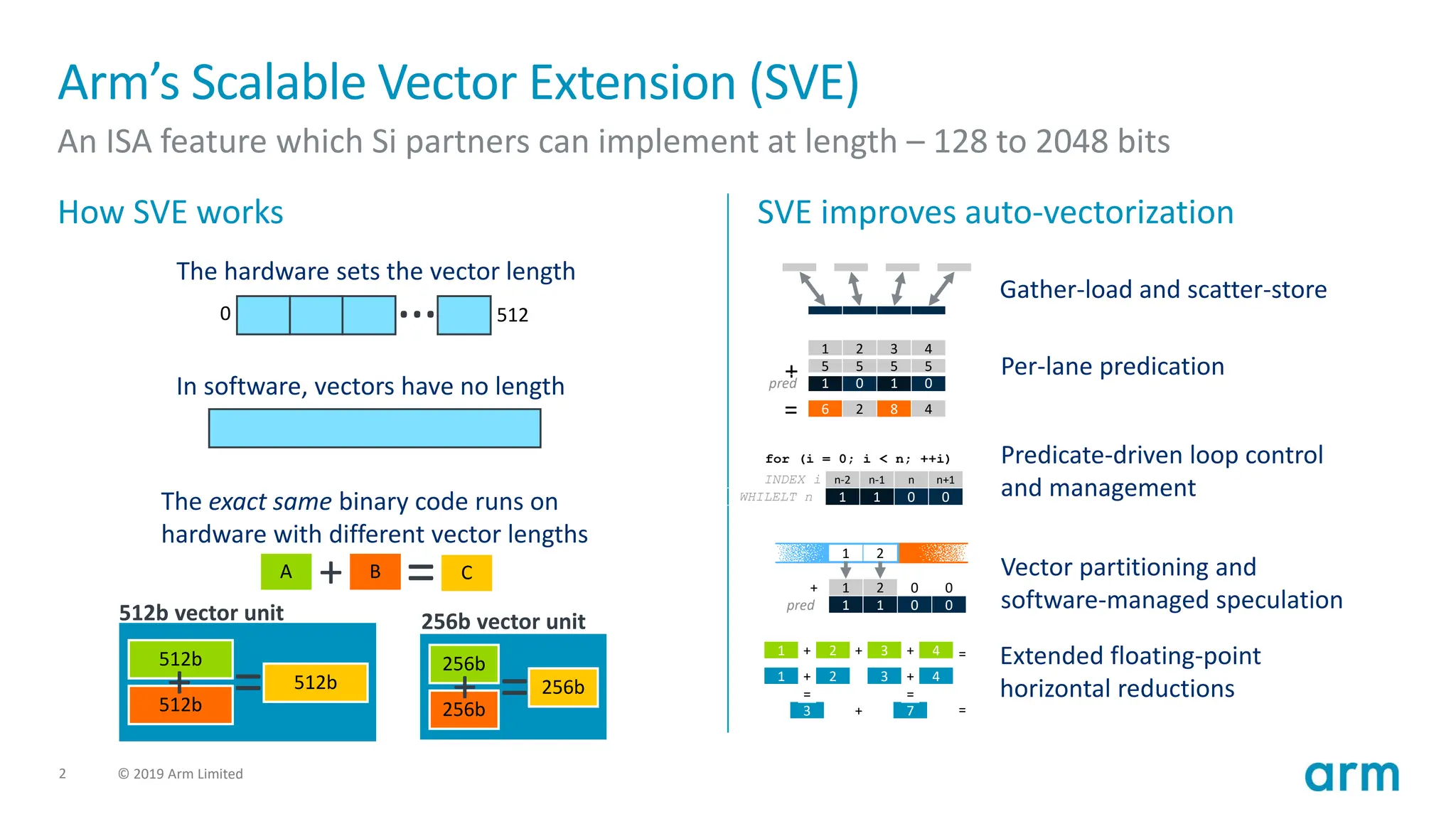
Arm’s Scalable Vector Extension (SVE)
An ISA feature which Si partners can implement at length – 128 to 2048 bits
How SVE works SVE improves auto-vectorization
1 + 2 + 3 + 4
1 + 2
+
3 + 4
3 7
= =
=
=
1 2 3 4
5 5 5 5
1 0 1 0
6 2 8 4
+
=
pred
1 2 0 0
1 1 0 0
+
pred
1 2
WHILELT n
n-2
1 0
1 0
n-1 n n+1
INDEX i
for (i = 0; i < n; ++i)
Gather-load and scatter-store
Per-lane predication
Predicate-driven loop control
and management
Vector partitioning and
software-managed speculation
Extended floating-point
horizontal reductions
The hardware sets the vector length
…
0 512
In software, vectors have no length
The exact same binary code runs on
hardware with different vector lengths
=
A C
B
+
512b
512b
512b
+ =
512b vector unit
256b
256b
256b
+ =
256b vector unit
- 3.
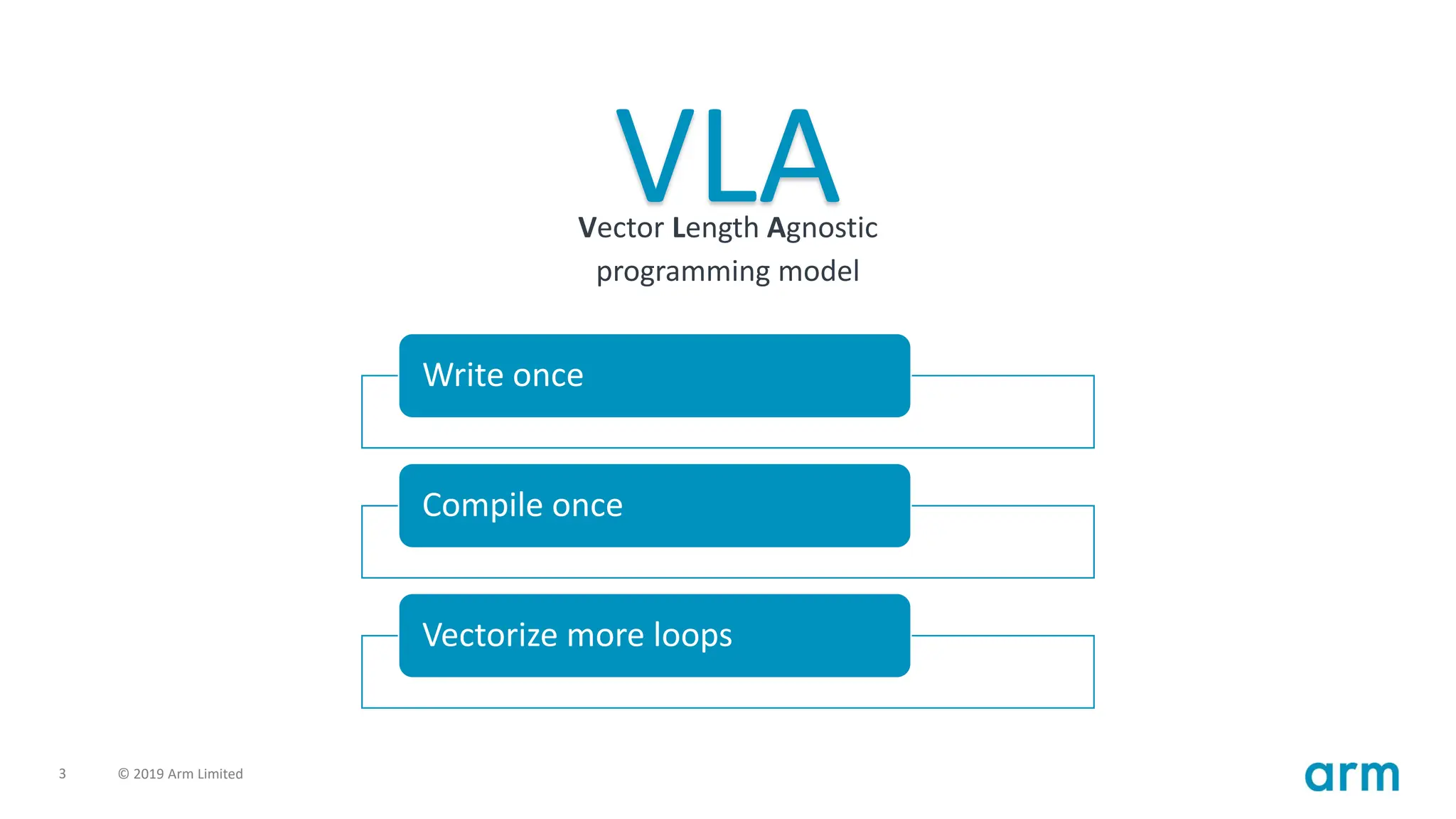
3 © 2019Arm Limited
Vector Length Agnostic
programming model
VLA
Write once
Compile once
Vectorize more loops
- 4.
4 © 2019Arm Limited
SVE vs Traditional ISA
How do we compute data which has ten chunks of 4-bytes?
SVE (128-bit VLA vector engine)
❑ Three iterations over a 16-byte VLA register
with an adjustable predicate
Aarch64 (scalar)
❑ Ten iterations over a 4-byte register
NEON (128-bit vector engine)
❑ Two iterations over a 16-byte register + two
iterations of a drain loop over a 4-byte register
- 5.
5 © 2019Arm Limited
How big can an SVE vector be?
Any multiple of 128 bits up to 2048 bits, and it can be dynamically reduced.
(A) VL = LEN x 128
(B) VL <= 2048
VL is implementation dependent,
can be reduced by the OS/Hypervisor.
?
- 6.
6 © 2019Arm Limited
How can you program when the vector length is unknown?
SVE provides features to enable VLA programming from the assembly level and up
1 2 3 4
5 5 5 5
1 0 1 0
6 2 8 4
+
=
pred
Per-lane predication
Operations work on individual lanes under control of a
predicate register.
n-2
1 0
1 0
WHILELT n
n-1 n n+1
INDEX i
for (i = 0; i < n; ++i) Predicate-driven loop control and management
Eliminate scalar loop heads and tails by processing partial
vectors.
Vector partitioning & software-managed speculation
First Faulting Load instructions allow memory accesses to cross into
invalid pages.
1 2 0 0
1 1 0 0
+
pred
1 2
- 7.
7 © 2019Arm Limited
SVE Registers
• Scalable vector registers
• Z0-Z31 extending NEON’s 128-bit V0-V31.
• Packed DP, SP & HP floating-point elements.
• Packed 64, 32, 16 & 8-bit integer elements.
• Scalable predicate registers
• P0-P7 governing predicates for load/store/arithmetic.
• P8-P15 additional predicates for loop management.
• FFR first fault register for software speculation.
- 8.
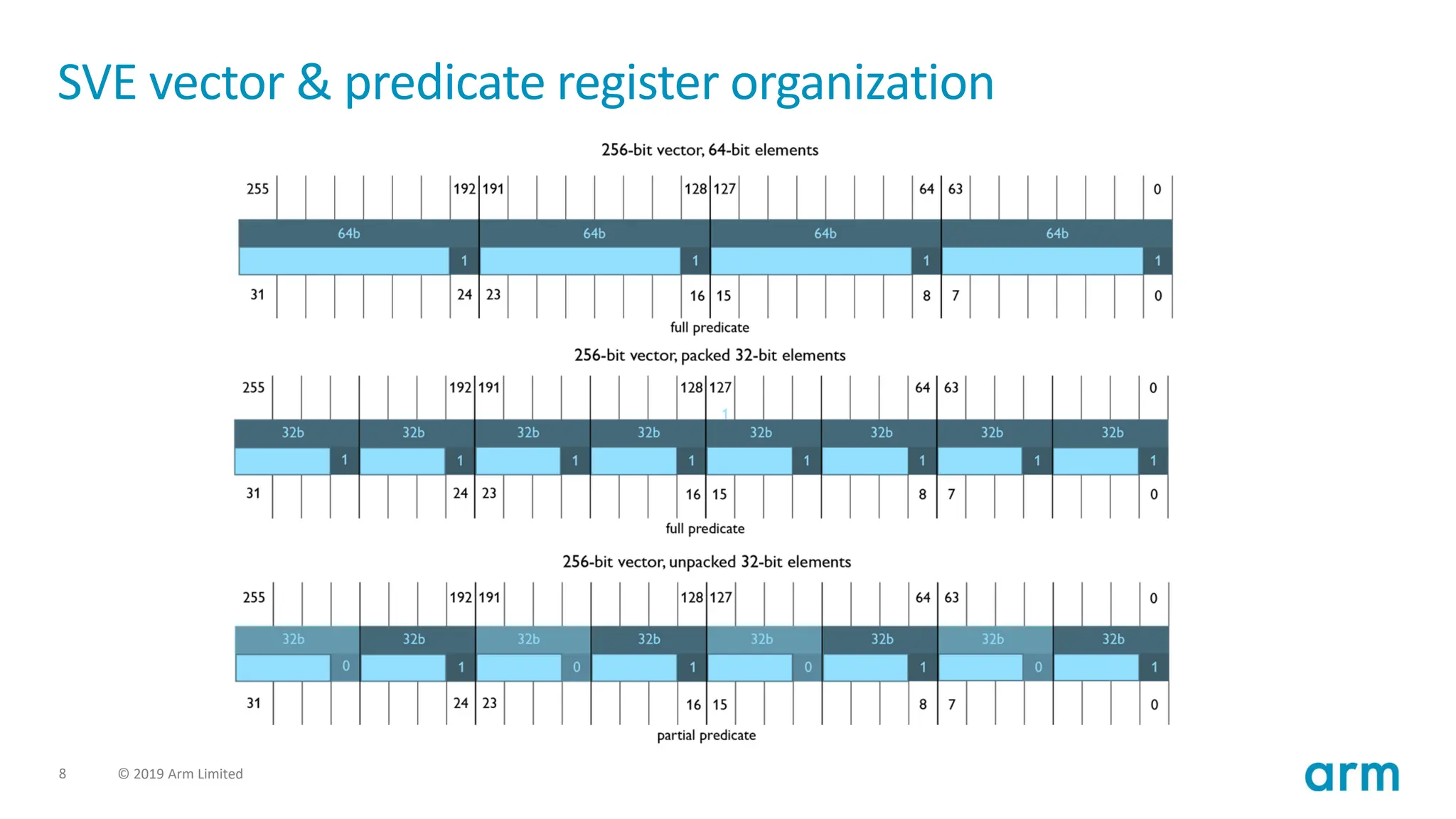
8 © 2019Arm Limited
SVE vector & predicate register organization
- 9.
9 © 2019Arm Limited
VLA Programming Approaches
Don’t panic!
• Compilers:
• Auto-vectorization: GCC, Arm Compiler for HPC, Cray, Fujitsu
• Compiler directives, e.g. OpenMP
– #pragma omp parallel for simd
– #pragma vector always
• Libraries:
• Arm Performance Library (ArmPL)
• Cray LibSci
• Fujitsu SSL II
• Intrinsics (ACLE):
• Arm C Language Extensions for SVE
• Arm Scalable Vector Extensions and Application to Machine Learning
• Assembly:
• Full ISA Specification: The Scalable Vector Extension for Armv8-A
- 10.
10 © 2019Arm Limited
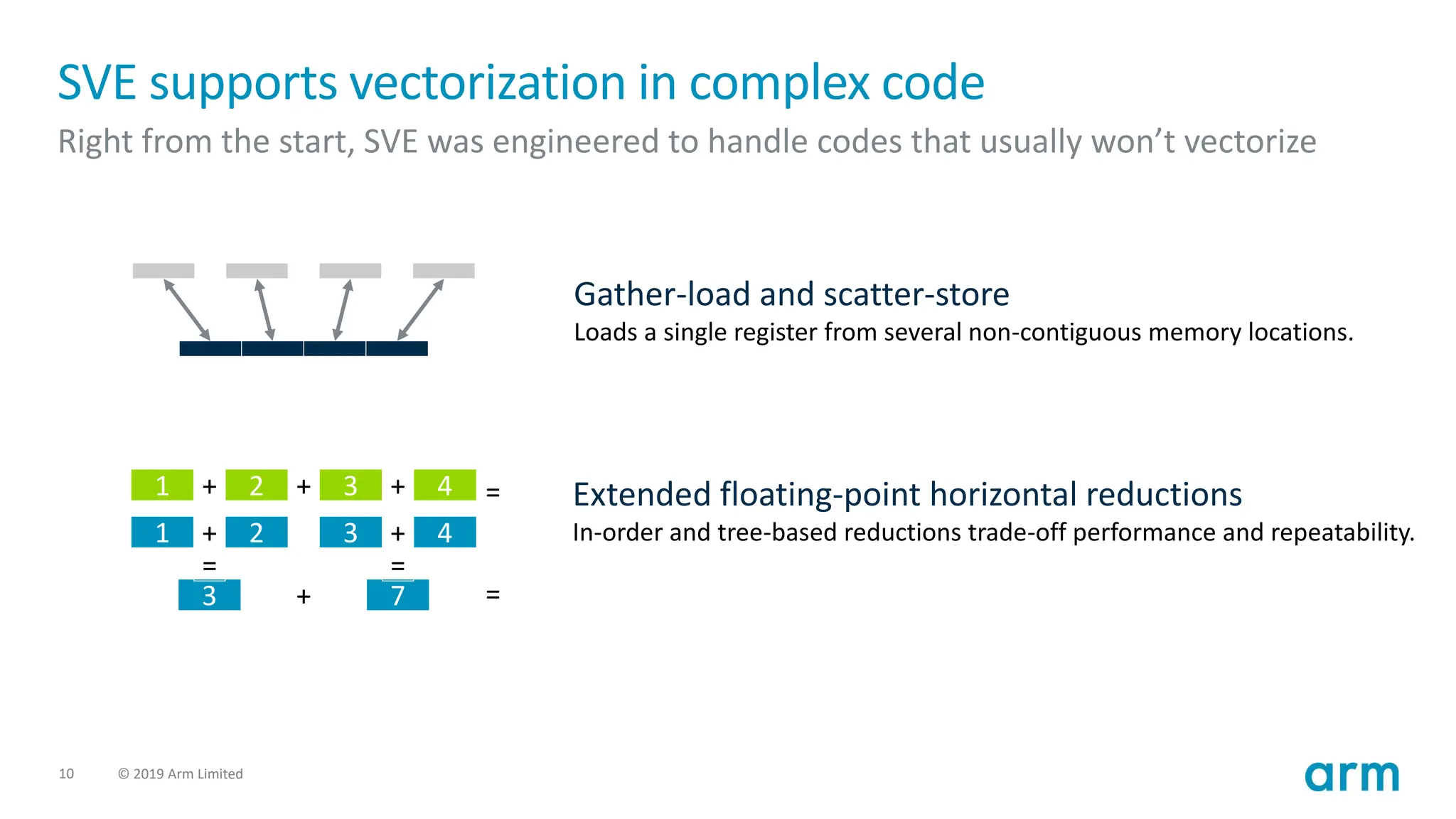
SVE supports vectorization in complex code
Right from the start, SVE was engineered to handle codes that usually won’t vectorize
1 + 2 + 3 + 4
1 + 2
+
3 + 4
3 7
= =
=
= Extended floating-point horizontal reductions
In-order and tree-based reductions trade-off performance and repeatability.
Gather-load and scatter-store
Loads a single register from several non-contiguous memory locations.
- 11.
11 © 2019Arm Limited
Portability
Is it really possible to run a vectorized application anywhere?
Write once: can my code compile for
machines with different VL?
• Code that is auto-vectorized by the compiler
• Hand-written assembly
• Hand-written C intrinsics
Compile once: Can I take my executable
and run it on machines with different VL?
• Self contained programs with no external
dependencies
• But what about programs that depend on
external libraries? ... (spoiler: )
?
- 12.
12 © 2019Arm Limited
Auto-vectorize external calls: libm example.
float sinf(float);
NEON
• Neon has 128-bit and 64-bit register split.
• The library has to provide at least 2 symbols,
because it doesn’t know where the auto-vec
code comes from:
• _ZGVnN2v_sinf
• _ZGVnN4v_sinf
SVE
• Does libm need to provide a symbol for each VL?
• _ZGVsM4v_sinf
• _ZGVsM6v_sinf
• _ZGVsM8v_sinf
• _ZGVsM10v_sinf
• …
• One symbol!
_ZGVsMxv_sinf
- 13.
13 © 2019Arm Limited
Open source support
• Arm actively posting SVE open source patches upstream
• Beginning with first public announcement of SVE at HotChips 2016
• Available upstream
• GNU Binutils-2.28: released Feb 2017, includes SVE assembler & disassembler
• GCC 8: Full assembly, disassembly and basic auto-vectorization
• LLVM 7: Full assembly, disassembly
• QEMU 3: User space SVE emulation
• GDB 8.2 HPC use cases fully included
• Under upstream review
• LLVM: Since Nov 2016, as presented at LLVM conference
• Linux kernel: Since Mar 2017, LWN article on SVE support
- 14.
14 © 2021Arm
SVE: More Powerful Vectorization on V1
SVE vectorizes more codes and makes better use of the vector units
0
0,2
0,4
0,6
0,8
1
haccmk memcpy long_strlen short_strlen pixel_avg milc_opt
Cycles
/
Cycles
SVE / NEON Simulation Projections
Lower is better
- 15.
15 © 2019Arm Limited
Quick Recap
• SVE enables Vector Length Agnostic (VLA) programming
• VLA enables portability, scalability, and optimization
• Predicates control which operations affect which vector lanes
• Predicates are not bitmasks
• You can think of them as dynamically resizing the vector registers
• The actual vector length is set by the CPU architect
• Any multiple of 128 bits up to 2048 bits
• May be dynamically reduced by the OS or hypervisor
• SVE was designed for HPC and can vectorize complex structures
• Many open source and commercial tools currently support SVE
n-2
1 0
1 0
WHILELT n
n-1 n n+1
INDEX i
for (i = 0; i < n; ++i)
1 2 0 0
1 1 0 0
+
pred
1 2
- 16.
- 17.
17 © 2019Arm Limited
05_Apps/01_HACC
See README.md for details
• Computationally intensive part of an N-body cosmology code.
• Application performance is dominated by a long chain of floating point instructions
• Performance scales well with vector length
• FOM: Wall clock time spent in the application loop reported in seconds
NEON128 on A64FX
SVE512 on A64FX
- 18.