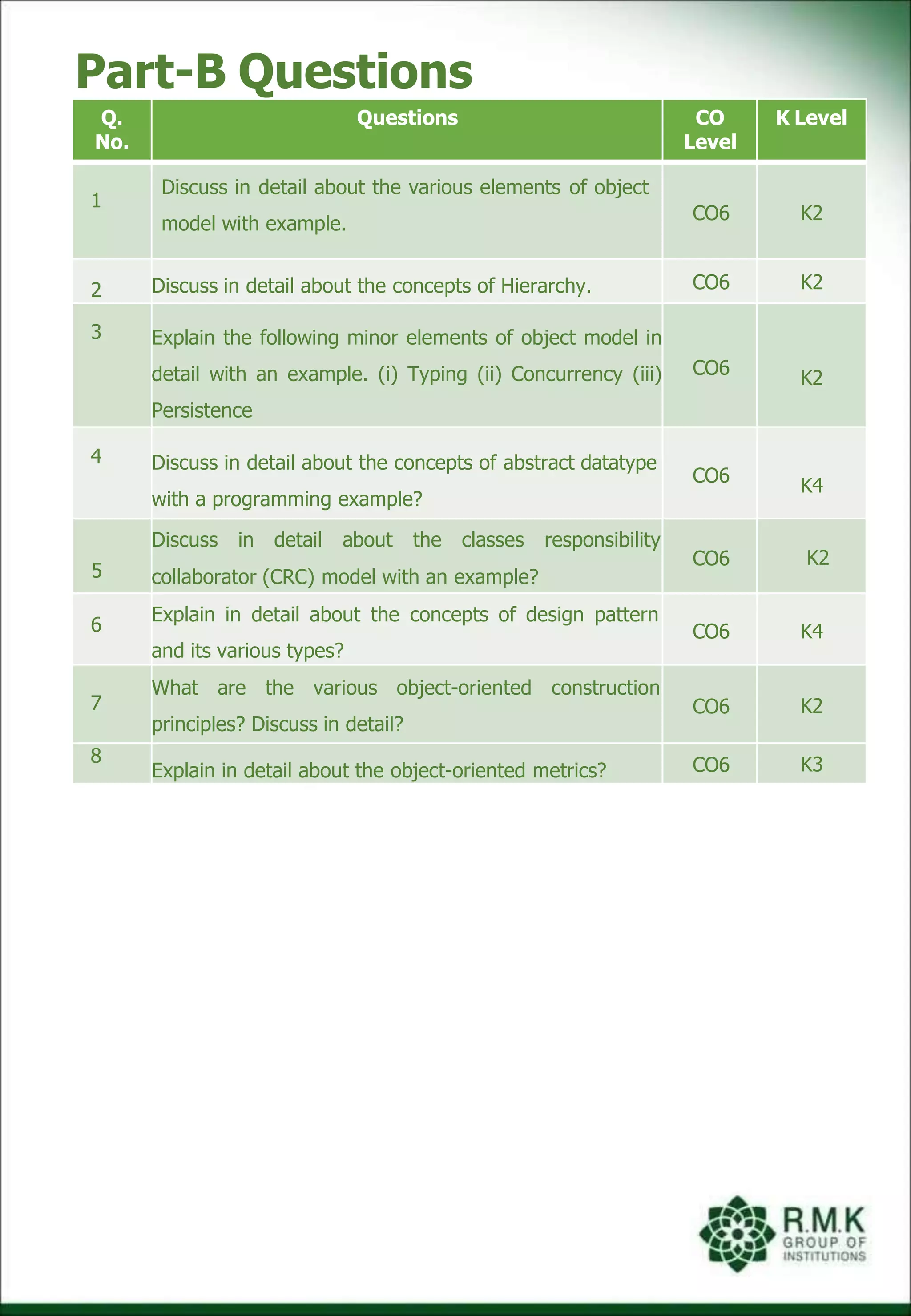
This document provides an overview of the course 20CB304 Software Engineering. It includes the course objectives, prerequisites, syllabus breakdown, and course outcomes.
The syllabus is divided into 5 units that cover topics like software project management, requirements analysis and design, software testing, and object-oriented analysis, design and construction.
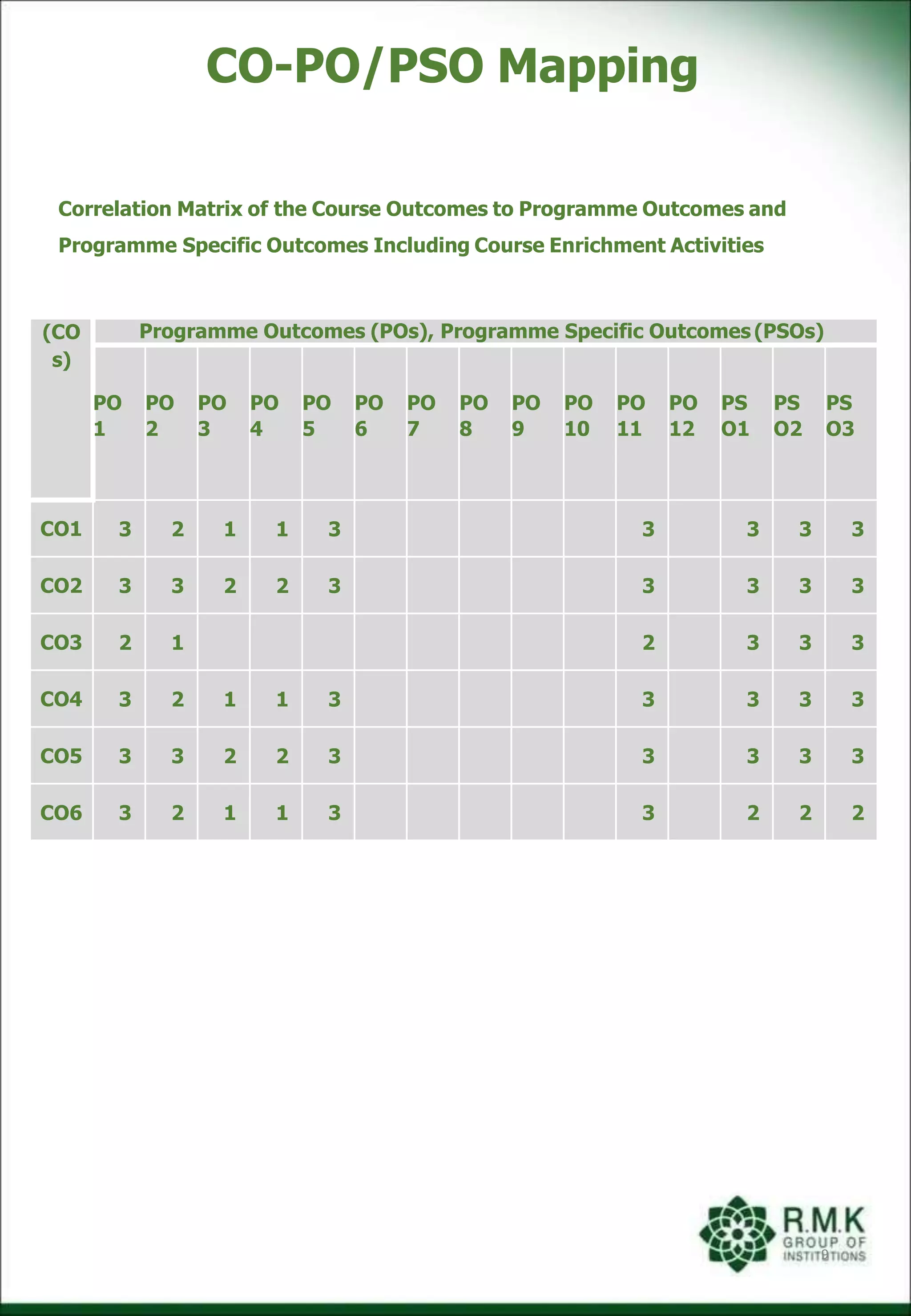
The document also lists the course outcomes and maps them to programme outcomes to show how the course helps achieve the learning objectives. It provides examples of key concepts taught like the principles of object-oriented programming, analysis, design and different types of abstractions.







![UNIT V
Object Oriented Analysis, Design and Construction
10
Object-Oriented Programming
Object-oriented programming is a method of implementation in which programs are
organized as cooperative collections of objects, each of which represents an instance of
some class, and whose classes are all members of a hierarchy of classes united via
inheritance relationships.
There are three important parts to this definition: (1) Object-oriented programming
uses objects, not algorithms, as its fundamental logical building; (2) each object is an
instance of some class; and (3) classes may be related to one another via inheritance
relationships. A program may appear to be object-oriented, but if any of these
elements is missing, it is not an object-oriented program. Specifically, programming
without inheritance is distinctly not object oriented; that would merely be programming
with abstract data types.
A language is object-oriented if and only if it satisfies the following
requirements:
It supports objects that are data abstractions with an interface of named operations
and a hidden local state.
Objects have an associated type [class].
Types [classes] may inherit attributes from supertypes [super classes].
Object-Oriented Design
Object-oriented design is a method of design encompassing the process of object-
oriented decomposition and a notation for depicting both logical and physical as well as
static and dynamic models of the system under design.
There are two important parts to this definition: object-oriented design (1) leads to an
object-oriented decomposition and (2) uses different notations to express different
models of the logical (class and object structure) and physical (module and process
architecture) design of a system, in addition to the static and dynamic aspects of the
system.](https://image.slidesharecdn.com/20cb304-se-unitv-digitalnotes-221130052203-9a200c9a/75/20CB304-SE-UNIT-V-Digital-Notes-pptx-10-2048.jpg)





![The overall goal of the decomposition into modules is the reduction of software cost
by allowing modules to be designed and revised independently. . . . Each module’s
structure should be simple enough that it can be understood fully; it should be
possible to change the implementation of other modules without knowledge of the
implementation of other modules and without affecting the behavior of other
modules; [and] the ease of making a change in the design should bear a reasonable
relationship to the likelihood of the change being needed”.
We strive to build modules that are cohesive (by grouping logically related
abstractions) and loosely coupled (by minimizing the dependencies among
modules). From this perspective, we may define modularity as follows:
Modularity is the property of a system that has been decomposed into a set of
cohesive and loosely coupled modules.
5.1.4 The Meaning of Hierarchy
A set of abstractions often forms a hierarchy, and by identifying these hierarchies in
our design, simplify understanding of the problem.
We define hierarchy as follows:
Hierarchy is a ranking or ordering of abstractions.
The two most important hierarchies in a complex system are its class structure (the
“is a” hierarchy) and its object structure (the “part of” hierarchy).
Examples of Hierarchy: Single Inheritance
inheritance defines a relationship among classes, wherein one class shares the
structure or behavior defined in one or more classes (denoting single inheritance
and multiple inheritance, respectively). Inheritance thus represents a hierarchy of
abstractions, in which a subclass inherits from one or more super classes. Typically,
a subclass augments or redefines the existing structure and behavior of its super
classes.
16](https://image.slidesharecdn.com/20cb304-se-unitv-digitalnotes-221130052203-9a200c9a/75/20CB304-SE-UNIT-V-Digital-Notes-pptx-16-2048.jpg)



![5.1.5 The Meaning of Typing
“A type is a precise characterization of structural or behavioral properties which a
collection of entities all share”.
Typing is the enforcement of the class of an object, such that objects of different
types may not be interchanged, or at the most, they may be interchanged only in
very restricted ways.
A given programming language may be strongly typed, weakly typed, or even
untyped, yet still be called object-oriented. For example, Eiffel is strongly typed,
meaning that type conformance is strictly enforced: Operations cannot be called on
an object unless the exact signature of that operation is defined in the object’s class
or superclasses.
Examples of Typing: Static and Dynamic Typing
The concepts of strong and weak typing and static and dynamic typing are entirely
different. Strong and weak typing refers to type consistency, whereas static and
dynamic typing refers to the time when names are bound to types. Static typing
(also known as static binding or early binding) means that the types of all variables
and expressions are fixed at the time of compilation; dynamic typing (also known as
late binding) means that the types of all variables and expressions are not known
until runtime. A language may be both strongly and statically typed (Ada), strongly
typed yet supportive of dynamic typing (C++, Java), or untyped yet supportive of
dynamic typing (Smalltalk).
Polymorphism is a condition that exists when the features of dynamic typing and
inheritance interact. Polymorphism represents a concept in type theory in which a
single name (such as a variable declaration) may denote objects of many different
classes that are related by some common superclass. Any object denoted by this
name is therefore able to respond to some common set of operations [74]. The
opposite of polymorphism is monomorphism, which is found in all languages that are
both strongly and statically typed.
Polymorphism is perhaps the most powerful feature of object-oriented programming
languages next to their support for abstraction, and it is what distinguishes object-
oriented programming from more traditional programming with abstract data types.
20](https://image.slidesharecdn.com/20cb304-se-unitv-digitalnotes-221130052203-9a200c9a/75/20CB304-SE-UNIT-V-Digital-Notes-pptx-20-2048.jpg)




![Formalizing the specification
An abstract data type specification will provide the following information.
• TYPES.
• FUNCTIONS.
• AXIOMS.
• PRECONDITIONS.
Specifying types
what is a type?
A type is a collection of objects characterized by functions, axioms and
preconditions. an abstract data type such as STACK is not an object (one particular
stack) but a collection of objects (the set of all stacks). An object belonging to the
set of objects described by an ADT specification is called an instance of the ADT. For
example, a specific stack which satisfies the properties of the STACK abstract data
type will be an instance of STACK.
Our specification is about a single abstract data type STACK, describing stacks of
objects of an arbitrary type G.
Genericity
In STACK [G], G denotes an arbitrary, unspecified type. G is called a formal generic
parameter of the abstract data type STACK, and STACK itself is said to be a generic
ADT. The mechanism permitting such parameterized specifications is known as
genericity.
Listing the functions
After the TYPES paragraph comes the FUNCTIONS paragraph, which lists the
operations applicable to instances of the ADT. As announced, these operations will
25](https://image.slidesharecdn.com/20cb304-se-unitv-digitalnotes-221130052203-9a200c9a/75/20CB304-SE-UNIT-V-Digital-Notes-pptx-25-2048.jpg)
![be the prime component of the type definition — describing its instances not by
what they are but by what they have to offer. Below is the FUNCTIONS paragraph
for the STACK abstract data type.
Each line introduces a mathematical function modeling one of the operations on
stacks. For example function put represents the operation that pushes an element
onto the top of a stack.
Operation put, for example, is specified as
which means that put will take two arguments, a STACK of instances of G and an
instance of G, and yield as a result a new STACK [G]. (More formally, the source set
of function put is the set STACK [G] X G, known as the cartesian product of STACK
[G] and G; this is the set of pairs <s, x> whose first element s is in STACK [G] and
whose second element x is in G.) Here is an informal illustration:
26](https://image.slidesharecdn.com/20cb304-se-unitv-digitalnotes-221130052203-9a200c9a/75/20CB304-SE-UNIT-V-Digital-Notes-pptx-26-2048.jpg)
![The role of the operations modeled by each of the functions in the
specification of STACK is discussed below.
•Function put yields a new stack with one extra element pushed on top. The figure
on the preceding page illustrates put (s, x) for a stack s and an element x.
•Function remove yields a new stack with the top element, if any, popped; like put,
this function should yield a command at design and implementation time. We will
see below how to take into account the case of an empty stack, which has no top to
be popped.
• Function item yields the top element, if any.
• Function empty indicates whether a stack is empty; its result is a boolean value
(true or false); the ADT BOOLEAN is assumed to have been defined separately.
• Function new yields an empty stack.
The FUNCTIONS paragraph does not fully define these functions; it only introduces
their signatures — the list of their argument and result types. The signature of put is
STACK [G] X G - STACK [G] indicating that put accepts as arguments pairs of the
form <s, x> where s is an instance of STACK [G] and x is an instance of G, and
yields as a result an instance of STACK [G]. The signature of functions remove and
item includes a crossed arrow instead of the standard arrow used by put and
empty. This notation expresses that the functions are not applicable to all members
of the source set.
The AXIOMS paragraph
The AXIOMS paragraph states the properties. For STACK it will be:
27](https://image.slidesharecdn.com/20cb304-se-unitv-digitalnotes-221130052203-9a200c9a/75/20CB304-SE-UNIT-V-Digital-Notes-pptx-27-2048.jpg)













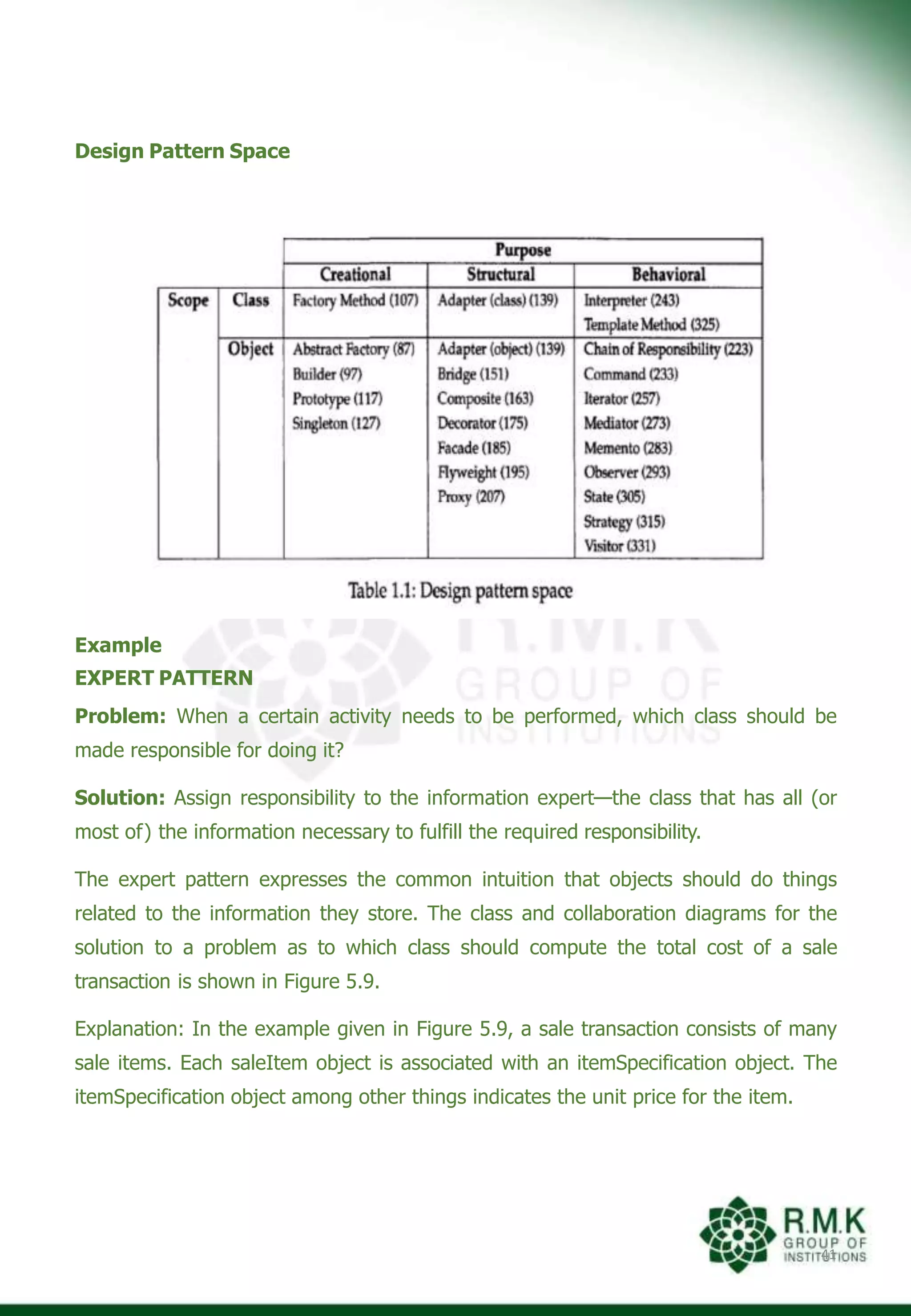

![5.8 Refactoring
43
An important design activity suggested for many agile methods, refactoring is a
reorganization technique that simplifies the design (or code) of a component without
changing its function or behavior.
“Refactoring is the process of changing a software system in such a way that it
does not alter the external behavior of the code [design] yet improves its internal
structure.”
When software is refactored, the existing design is examined for redundancy, un-
used design elements, inefficient or unnecessary algorithms, poorly constructed or
inappropriate data structures or any other design failure that can be corrected to
yield a better design.
For example, a first design iteration might yield a component that exhibits low
cohesion (i.e., it performs three functions that have only limited relationship to one
another). After careful consideration, you may decide that the component should be
refactored into three separate components, each exhibiting high cohesion.
Why Should You Refactor?
Refactoring Improves the Design of Software
Refactoring Makes Software Easier to Understand
Refactoring Helps You Find Bugs
Refactoring Helps You Program Faster
When Should You Refactor?
Refactor when You add new feature/function
Refactor When You Need to Fix a Bug
Refactor As You Do a Code Review
Problems with Refactoring
Databases
One problem area for refactoring is databases. Most business applications are tightly](https://image.slidesharecdn.com/20cb304-se-unitv-digitalnotes-221130052203-9a200c9a/75/20CB304-SE-UNIT-V-Digital-Notes-pptx-43-2048.jpg)