劣モジュラ最適化と機械学習 2.0-2.3 劣モジュラ関数の基本性質・例・最適化 間違えているところや疑問点などがありましたら下記のツイッターアカウントまでご一報ください。 @gen_goose_gen












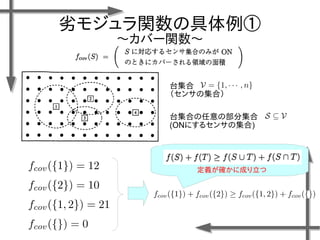






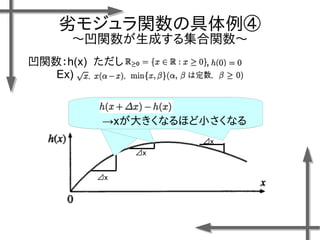





















![劣モジュラ関数の最適化
〜(制約なし)劣モジュラ関数最小化〜
・多項式時間アルゴリズムが存在する
現在の最小計算量: [Orlin,2009]
これでも大きい
最大でかかる計算量保証
・多項式性は保証されないが実用的なアルゴリズムがある
(最小ノルム点アルゴリズム)
・関数fによっては高速に最適解が見つかる
(Ex:最小s-tカット問題)](https://image.slidesharecdn.com/submodularoptimizationandmachinelearning20-23-170515044708/85/2-0-2-3-42-320.jpg)
![劣モジュラ関数の最適化
〜対称劣モジュラ関数最小化〜
:自明解になる→取り除いて最適解を見つける
∵任意の に対して
・効率的なアルゴリズムが存在: [Queyranne,1998]
・Ex:無向グラフの最小カット問題](https://image.slidesharecdn.com/submodularoptimizationandmachinelearning20-23-170515044708/85/2-0-2-3-43-320.jpg)
![劣モジュラ関数の最適化
〜(単調な)劣モジュラ関数最大化〜
すべての について
・NP困難問題
(多項式時間では解けないと考えられているが種名されていない問題)
・近似的な解は多項式時間で求められる
貪欲法の一種で最適値の0.63倍以上の目的関数値を達成可能
[Nemhauser,Wolsey,Fisher,1978]](https://image.slidesharecdn.com/submodularoptimizationandmachinelearning20-23-170515044708/85/2-0-2-3-44-320.jpg)
![劣モジュラ関数の最適化
〜非負な劣モジュラ関数最大化〜
すべての について
・NP困難問題
(多項式時間では解けないと考えられているが種名されていない問題)
・近似的な解は多項式時間で求められる
貪欲法の一種で最適値の0.5倍以上の目的関数値を達成可能
[Buchbinder,Feldman,Naor,Schwartz,2012]
・Ex:無向グラフの最大カット問題
貪欲法の一種で最適値の0.878倍以上の目的関数値を達成可能](https://image.slidesharecdn.com/submodularoptimizationandmachinelearning20-23-170515044708/85/2-0-2-3-45-320.jpg)




































