Download to read offline



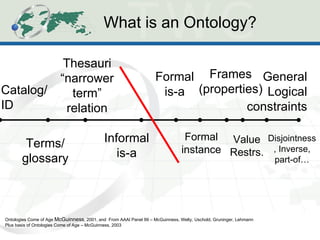


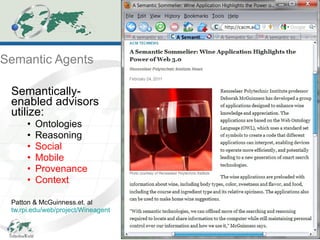




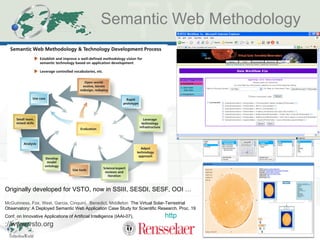
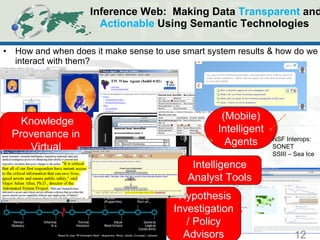








The document discusses the evolution and application of ontologies in various fields since their initial presentation in 2000, emphasizing the transition from expressiveness to ecosystem considerations for ontology-enabled applications. It highlights the growing integration of ontologies in e-commerce and scientific research, with a focus on the challenges of compatibility, provenance, and maintenance. Key observations include the democratization of ontology creation, the rise of semi-automated tools, and the importance of modular design and community engagement.








![Context Aware Harassment Detection in Social Media [Overview]](https://cdn.slidesharecdn.com/ss_thumbnails/harassment-short-v3-nov15-151119171214-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)


























































