Recommended
PPTX
PPTX
PDF
PPT
Power point hecho animales
PPTX
PPT
PPT
Re-presentat.cristina pigazos requena
PPTX
PDF
任意粒度機能モデルに基づく動的型付けプログラミング言語向けソースコード検索手法の提案
PDF
プログラミングコンテストでのデータ構造 2 ~平衡二分探索木編~
PPTX
高速な挿入と検索が可能なSkip Graphの改良
PDF
PDF
プログラミングコンテストでのデータ構造 2 ~動的木編~
PDF
PPTX
PDF
PDF
PDF
PDF
Algorithm, about balanced binary tree
PDF
PDF
Data-Intensive Text Processing with MapReduce ch4
PDF
論文紹介: Cuckoo filter: practically better than bloom
PPTX
PDF
PDF
PDF
[アルゴリズムイントロダクション勉強会] ハッシュ
PDF
PPTX
PPTX
構造化オーバーレイネットワークを用いた条件付きマルチキャストの提案と評価
PPTX
構造化オーバーレイネットワークを用いた条件付きマルチキャストの提案
More Related Content
PPTX
PPTX
PDF
PPT
Power point hecho animales
PPTX
PPT
PPT
Re-presentat.cristina pigazos requena
PPTX
Similar to P2PネットワークにおけるSkip GraphとBloom Filterを用いた効率的な複数キーワード検索手法の提案
PDF
任意粒度機能モデルに基づく動的型付けプログラミング言語向けソースコード検索手法の提案
PDF
プログラミングコンテストでのデータ構造 2 ~平衡二分探索木編~
PPTX
高速な挿入と検索が可能なSkip Graphの改良
PDF
PDF
プログラミングコンテストでのデータ構造 2 ~動的木編~
PDF
PPTX
PDF
PDF
PDF
PDF
Algorithm, about balanced binary tree
PDF
PDF
Data-Intensive Text Processing with MapReduce ch4
PDF
論文紹介: Cuckoo filter: practically better than bloom
PPTX
PDF
PDF
PDF
[アルゴリズムイントロダクション勉強会] ハッシュ
PDF
PPTX
More from Kota Abe
PPTX
構造化オーバーレイネットワークを用いた条件付きマルチキャストの提案と評価
PPTX
構造化オーバーレイネットワークを用いた条件付きマルチキャストの提案
PDF
WebRTCを用いたWebブラウザ間構造化P2Pネットワークの実現
PDF
WebRTCを用いた耐故障性の高い
ウェブブラウザ間構造化P2Pネットワークの実現
PDF
高いChurn耐性と検索性能を持つキー順序保存型構造化オーバレイネットワークSuzakuの提案と評価
PDF
Constructing Distributed Doubly Linked Lists without Distributed Locking
PPTX
KiZUNA: P2Pネットワークを用いた分散型マイクロブログサービスの実現
PDF
P2Pネットワークにおける経路長あるいは経路表サイズの最大値を柔軟に設定可能な経路表構築方式
PDF
構造化P2Pネットワークにおけるコンテンツの人気度を考慮したショートカットリンクの生成方法とその評価
PDF
Skip Graphをベースとした高速な挿入と検索が可能な構造化オーバレイの提案
PPTX
距離が付加された要素集合をコンパクトに表現できるDistance Bloom Filterの提案とP2Pネットワークにおける最短経路探索への応用
PPTX
Chord#における経路表の維持管理コスト削減手法
ODP
区間をキーとして保持する分散KVSの効率的な実現法
PPT
P2Pシステム上での安定したサービス提供基盤musasabi
PPTX
構造化オーバーレイネットワークに適した分散双方向連結リストDDLL
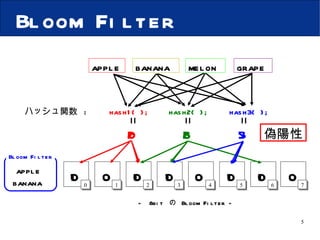
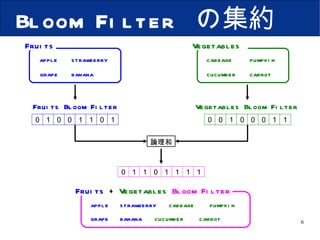
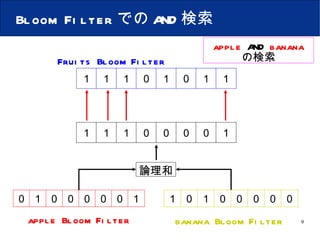
P2PネットワークにおけるSkip GraphとBloom Filterを用いた効率的な複数キーワード検索手法の提案 1. P2P ネットワークにおける Skip Graph と Bloom Filter を用いた 効率的な複数キーワード検索手法の提案 大阪市立大学 創造都市研究科 岩本 大記 石橋 勇人 安倍 広多 松浦 敏雄 2. 背景 Peer-to-Peer ネットワーク 耐障害性 スケーラビリティ 分散ハッシュテーブル (DHT) 大量のドキュメントを分散管理した場合 , ドキュメント全文に AND 検索をかけられない Skip Graph と Bloom Filter を利用し , ノードが保持するドキュメント全文に対し , 効率よく AND 検索を行なう手法を提案 3. Skip Graph [ 構造 ] Level0 Level2 Level1 2 9 5 7 3 8 6 0 000 1 001 0 100 1 011 1 101 0 111 0 010 0000 1001 0100 1011 1101 0111 0010 membership vector 2 9 5 7 3 8 6 key 2 00 00 9 00 10 5 01 00 7 01 11 8 10 01 6 10 11 3 11 01 4. Skip Graph [ membership vector の基数による違い ] membership vector が2進数の場合 membership vector が5進数の場合 高さは平均で log w N Level0 Level1 Level2 Level3 Level4 5. Bloom Filter apple banana grape melon 偽陽性 0 1 2 3 4 5 6 7 - 8bit の Bloom Filter - apple banana Bloom Filter hash1( ); hash2( ); hash3( ); ハッシュ関数 : 0 5 3 2 3 6 1 5 2 2 5 3 0 0 0 0 0 0 0 0 1 0 0 1 0 1 0 0 1 0 1 1 0 1 1 0 1 0 1 1 0 1 1 0 6. Bloom Filter の集約 apple strawberry grape banana Fruits cabbage pumpkin cucumber carrot Vegetables Fruits Bloom Filter Vegetables Bloom Filter 論理和 0 1 0 0 1 1 0 1 0 0 1 0 0 0 1 1 0 1 1 0 1 1 1 1 apple strawberry cabbage pumpkin grape banana cucumber carrot Fruits + Vegetables Bloom Filter 7. 提案手法 [ 構造 ] Level0 Level1 2 9 5 7 3 8 6 2 9 5 7 3 8 6 ポインタ 3 6 8 ドキュメント Bloom Filter 8. 提案手法 [ 構造 ] 5 7 9 6 8 Level0 Level2 Level1 2 9 5 7 3 8 6 2 9 5 7 3 8 6 3 2 9 5 7 8 6 2 Level3 3 5 7 8 6 9 3 9. Bloom Filter での AND 検索 apple Bloom Filter banana Bloom Filter Fruits Bloom Filter apple AND banana の検索 0 1 0 0 0 0 0 1 1 0 1 0 0 0 0 0 1 1 1 0 1 0 1 1 1 1 1 0 0 0 0 1 論理和 10. 提案手法 [ 検索 ] apple AND banana の検索 O(log w N) w = membership vector の基数 N = ノード数 Level0 Level2 Level1 2 9 5 7 3 8 6 2 9 5 7 3 8 6 3 2 9 5 7 8 6 2 Level3 3 5 7 8 6 9 5 7 3 6 8 9 11. 提案手法 [ Bloom Filter の更新 ] O( w log w N) w = membership vector の基数 N = ノード数 Level0 Level2 Level1 2 9 5 7 3 8 6 2 9 5 7 3 8 6 3 2 9 5 7 8 6 2 Level3 3 5 7 8 6 9 5 7 3 9 12. シミュレーションによる評価 提案手法での複数キーワード検索時における 1. 検索ホップ数 2. Bloom Filter 更新時の更新メッセージ数 測定条件 ノード数: 100 〜 1000 個 membership vector の基数:2〜5 ドキュメント:基本英単語 5,800 語からランダムに 300 語を 抽出したテキストファイル 100 個 各ノードはランダムに 1 〜 5 個のドキュメントを保持 Bloom Filter ビット長: 10240 ビット ハッシュ関数:4個 13. 評価 [ ノード数に対する 検索ホップ数 ] membership vector が2進数 3 進数 4 進数 5 進数 検索ホップ数 ノード数 ( N ) ネットワーク全体にヒットする ドキュメントが1つ O(log w N) 14. 提案手法 [ 検索ホップ数 ] Level0 Level2 Level1 2 9 5 7 3 8 6 2 9 5 7 3 8 6 3 2 9 5 7 8 6 2 Level3 3 5 7 8 6 9 5 7 3 6 8 9 15. 評価 [ ノード数に対する 検索ホップ数 ] membership vector が2進数 3 進数 4 進数 5 進数 検索ホップ数 ノード数 ( N ) ネットワーク全体にヒットする ドキュメントが1つ O(log w N) 16. 評価 [ ヒットするドキュメント数が変化したときの検索ホップ数 ] ヒットするドキュメントの存在率 (%) 検索ホップ数 ノード数が 500 のとき ヒットする キュメントの存在率を変化 3 進数 4 進数 5 進数 membership vector が2進数 ホップ数はほとんど増加しない 17. 評価 [ 更新時のホップ数 ] ノード数 メッセージホップ数 3 進数 4 進数 5 進数 更新時のメッセージホップ数 membership vector が2進数 O( w log w N) 18. 提案手法 [ Bloom Filter の更新ホップ数 ] Level0 Level2 Level1 2 9 5 7 3 8 6 2 9 5 7 3 8 6 3 2 9 5 7 8 6 2 Level3 3 5 7 8 6 9 19. 評価 [ 更新時のホップ数 ] ノード数 メッセージホップ数 membership vector が2進数 3 進数 4 進数 5 進数 更新時のメッセージホップ数 基数が大きい程更新コストが大きくなる O( w log w N) 20. まとめ 効率的な複数キーワード検索を実現 AND 検索を O(log w N) 時間で実行できる. ( w =membership vector の基数 , N = ノード数 ) 検索時間は,検索キーワードの数やドキュメントの数に依存しない. 今後の課題 AND と OR を組み合わせた条件で検索ができるように拡張. 大量のドキュメントがマッチした場合 , 検索結果の上限数を決める. 21. Editor's Notes #3 現在, 耐障害性やスケーラビリティの点からP2P術が注目されています. P2Pの分野では, 分散ハッシュテーブルに基づく構造化P2Pネットワークがよく研究されていますが, DHTでは, keyとvalueを1つのセットとするため, ノードが大量のドキュメントを保持している場合, ノードが持つドキュメント全文に対し,複数の言葉を指定して全てを含むドキュメントの検索, いわゆる, AND 検索をすることが難しいという問題があります. そこで, Skip GraphとBloom Filterについては, 次に説明します #4 SkipGraph の構造を説明します。 Skip Graph に参加するノード群があります . 各ノードは , ノードを識別する key と 乱数で割り当てられた membership vector を持ちます . この Skip Graph は , membership vector が2進数のものです . SkipGraph にはいくつかの階層があり , Level0 では , key の昇順に並んだ全てのノードが左右に隣接するノードと双方向に繋がり , 1つの連結リストを作ります . Level1 では , membership vector の上位1ビットが同じノード同士が繋がり , 連結リストを作ります . Level2 では上位2ビットが同じものというように連結リストを作っていき , 連結リスト上でノード数が 1 になるレベルまで同じ処理を行います . 図のように , 各ノードは複数の連結リストに参加する形になります . このようにレベルが上がるにつれ , 連結リストの数が増え , 連結リストに属するノードの数は約半分になる . これは membership vector が2進数の例です . 次に membership vector の基数を変えた場合について述べます。 #5 このように, Skip Graphは, membership vector の基数の値が大きくなると, 高さが低くなます. 高さはノード数がNの場合, 平均で logwN となります. #6 次に , Bloom Filter について説明します . Bloom Filter は , 複数の要素からなる集合の中に目的とする要素が含まれているかを簡単に判定することができるデータ構造です . まず , ハッシュ関数とビット列を用意します . このハッシュ関数の数とビット列のサイズは任意に設定できるので , 例として , 3 つのハッシュ関数と 8bit からなる Bloom Filter を用意します . ビット数が 8 の場合 , ハッシュ関数で得られる値は , 0から 7 の範囲に収まるようにしておきます . はじめに , 用意したブルームフィルタを全て「0」で初期化します . ブルームフィルタに追加しておく要素を「 apple 」と「 banana 」とすると , まず , 「 apple 」を 3 つのハッシュ関数で変換し,得られた値「 0, 3, 5 」を配列のインデックスとみなし,該当する箇所を1にします . 「 banana 」も同様にし,得られた値の箇所を1します . このとき,すでにビットが立っている箇所は,そのまま「 1 」にしておきます. これで,要素「 apple 」と「 banana 」を含むブルームフィルタが完成です . このブルームフィルタを使い, 要素「 apple 」「 melon 」「 grape 」をチェックする場合を説明します . まず,要素「 apple 」を3つのハッシュ関数で変換し , 得られた値「 0, 3, 5 」と Bloom Filter を比較します. この場合,3箇所とも「 1 」であるので,要素「 apple 」は含まれているといえます. 次に,要素「 melon 」をチェックします . メロンをハッシュ変換し,得られた値「 1, 2, 5 」を比較します. この場合,インデックス「1」の箇所が「 0 」です . Bloom Filter では , 1つでも 0 の箇所があればその要素は必ず , 含まれていないといえます . 最後に,要素「 grape 」をチェックします. 「 3, 5, 2 」が得られ , Bloom Filter を比較すると全て「 1 」になっています.ですが,今, Bloom Filter に含まれている要素は「 apple 」と「 banana 」だけなので,実際には要素「 grape 」は含まれていません. Bloom Filter では , このように含まれていないにもかかわらず,含まれていると判定していまうことがあります , これを偽陽性と呼びます. #7 また、フルーツの集合とベジタブルの集合があった場合 , これら 2 つの Bloom Filter の論理和をとることで , 和集合を意味する Bloom Filter ができます . 以上が Bloom Filter の構造になります。 #8 提案手法の構造を説明します. 基本的に Skip Graph と同じ構造です. 各ノードは Skip Graph でのkeyやmembership vector , 左右のノードへのポインタに含め, Bloom Filter を持ちます. レベル0では, 各ノードが保持するドキュメントを Bloom Filter に変換したものを持ちます. レベル1では, 連結リスト上の右に挿入されているノードから1つレベルを下り, 左にあるノードから 自ノードまでに存在するノードの Bloom Filter を持ちます . このとき , Bloom Filter の取得と同時にそのノードへのポインタも取得します . #9 論理和をとることで, 全ノードの全ドキュメントを表す, Bloom Filter が得られます. 各ノードも同じようにBloom Filterを持ちます. 次に提案手法での検索について説明に入りますが, #10 先に Bloom Filter での AND 検索の説明をしたいと思います. フルーツという集合があり, これに アップルとバナナがどちらも含まれているかを調べるとき, #11 ノード2が apple と banana の2つのキーワードを含むドキュメントを検索する流れを説明します . この2つのキーワードが含まれているドキュメントがノード3とノード8に存在するとします . はじめに , 2つの検索キーワード apple と banana を Bloom Filter に変換し , 論理和をとって集約します . このとき , Bloom Filter の偽陽性が発生したドキュメントも含まれます . このように検索範囲を絞り込みながら検索処理はパラレルに行なわれていきます . また , 発信元であるノード2は検索メッセージを送信した後は , ドキュメントが送られてくるのを待ち , 一定時間が過ぎると検索処理を終了します . 以上が提案手法での検索の流れとなります . 検索にかかる時間は , O(logwN) になると予想されます . #12 次に , Bloom Filter の更新の流れを説明します . 一周し , 発信元のノードに辿り着いた時点で , 処理を終了します . 以上が更新処理の流れとなります . この更新処理は, ノードの参加・離脱・ドキュメントの変更などがあるため, 定期的に行なう必要があります. また , この更新処理は , ノードの参加時にも行なわれます . 更新にかかるコストは , 平均で O(wlogwN) となると予想されます . #13 提案手法での複数キーワード検索時における,検索メッセージ数,検索ホップ数, Bloom Filter 更新時の更新メッセージ数の計測を行ないました . ドキュメントは, 基本英単語 5,800 語からランダムに300語を抜き出したテキストファイルを使用しました. 同様のドキュメントを100個用意し, 各ノードはこの100個の中からランダムに選ばれた複数個のドキュメント(最小で1個,最大で 5 個)を保持するようにしました. #14 これは , 指定したキーワードにマッチするドキュメントがネットワーク中に 1 つだけある 場合の 検索にかかる時間を表したグラフです . #15 赤矢印で何ホップあるか計測したものです #16 試行は 10 回行い , 平均値をプロットました . 検索ホップ数はノード数の O(logwN) となっています . w は membership vector の基数で , N はノード数です . また membership vector の基数を大きくするとホップ数が減少することがわかります . #17 次に , マッチするドキュメントが少ない場合と多い場合での変化を調べるため , 正解となるドキュメントを用意して , ノー ド数を 500 個で固定した時の先程の赤線で示したものが何ホップかかるかを計測したものです . このグラフからマッチするドキュメントが増加しても ホップ数はほとんど増加しないことが確認できます . これは , 高さは変わらず , パラレルに検索を行なっているためだと考えられます . #18 これは , Bloom filter を更新するための 更新 メッセージホップ数を計測したグラフです . #19 これです . #20 縦軸に更新メッセージのホップ数 , 横軸にノード数 を表しています . 基数が大きいほどホップ数が増えているますが , これは 更新 メッセージを横方向に転送する回数が増えるためです . ## 基数が大きい程更新コストが大きくなることを←図 #21 まとめとして, 検索キーワードの数やドキュメントの数に依存せず, AND検索をo(log w N)時間で実行でたことから, P2Pネットワーク上で効率よく複数キーワード検索を実行できるといます. 今後の課題として , 提案手法では AND 検索のみを扱っていましたが, AND と OR を組み合わせた条件で検索ができるように拡張したいと思います.また,大量のドキュメントがマッチした場合,検索するノードへ大量のデータが 送られることになるため,検索結果の上限数を決められるような方法を検討する必要があると考えます.



![Skip Graph [ 構造 ] Level0 Level2 Level1 2 9 5 7 3 8 6 0 000 1 001 0 100 1 011 1 101 0 111 0 010 0000 1001 0100 1011 1101 0111 0010 membership vector 2 9 5 7 3 8 6 key 2 00 00 9 00 10 5 01 00 7 01 11 8 10 01 6 10 11 3 11 01](https://image.slidesharecdn.com/2011-iwamoto-dps-110327021643-phpapp02/85/P2P-Skip-Graph-Bloom-Filter-3-320.jpg)
![Skip Graph [ membership vector の基数による違い ] membership vector が2進数の場合 membership vector が5進数の場合 高さは平均で log w N Level0 Level1 Level2 Level3 Level4](https://image.slidesharecdn.com/2011-iwamoto-dps-110327021643-phpapp02/85/P2P-Skip-Graph-Bloom-Filter-4-320.jpg)
![提案手法 [ 構造 ] Level0 Level1 2 9 5 7 3 8 6 2 9 5 7 3 8 6 ポインタ 3 6 8 ドキュメント Bloom Filter](https://image.slidesharecdn.com/2011-iwamoto-dps-110327021643-phpapp02/85/P2P-Skip-Graph-Bloom-Filter-7-320.jpg)
![提案手法 [ 構造 ] 5 7 9 6 8 Level0 Level2 Level1 2 9 5 7 3 8 6 2 9 5 7 3 8 6 3 2 9 5 7 8 6 2 Level3 3 5 7 8 6 9 3](https://image.slidesharecdn.com/2011-iwamoto-dps-110327021643-phpapp02/85/P2P-Skip-Graph-Bloom-Filter-8-320.jpg)
![提案手法 [ 検索 ] apple AND banana の検索 O(log w N) w = membership vector の基数 N = ノード数 Level0 Level2 Level1 2 9 5 7 3 8 6 2 9 5 7 3 8 6 3 2 9 5 7 8 6 2 Level3 3 5 7 8 6 9 5 7 3 6 8 9](https://image.slidesharecdn.com/2011-iwamoto-dps-110327021643-phpapp02/85/P2P-Skip-Graph-Bloom-Filter-10-320.jpg)
![提案手法 [ Bloom Filter の更新 ] O( w log w N) w = membership vector の基数 N = ノード数 Level0 Level2 Level1 2 9 5 7 3 8 6 2 9 5 7 3 8 6 3 2 9 5 7 8 6 2 Level3 3 5 7 8 6 9 5 7 3 9](https://image.slidesharecdn.com/2011-iwamoto-dps-110327021643-phpapp02/85/P2P-Skip-Graph-Bloom-Filter-11-320.jpg)

![評価 [ ノード数に対する 検索ホップ数 ] membership vector が2進数 3 進数 4 進数 5 進数 検索ホップ数 ノード数 ( N ) ネットワーク全体にヒットする ドキュメントが1つ O(log w N)](https://image.slidesharecdn.com/2011-iwamoto-dps-110327021643-phpapp02/85/P2P-Skip-Graph-Bloom-Filter-13-320.jpg)
![提案手法 [ 検索ホップ数 ] Level0 Level2 Level1 2 9 5 7 3 8 6 2 9 5 7 3 8 6 3 2 9 5 7 8 6 2 Level3 3 5 7 8 6 9 5 7 3 6 8 9](https://image.slidesharecdn.com/2011-iwamoto-dps-110327021643-phpapp02/85/P2P-Skip-Graph-Bloom-Filter-14-320.jpg)
![評価 [ ノード数に対する 検索ホップ数 ] membership vector が2進数 3 進数 4 進数 5 進数 検索ホップ数 ノード数 ( N ) ネットワーク全体にヒットする ドキュメントが1つ O(log w N)](https://image.slidesharecdn.com/2011-iwamoto-dps-110327021643-phpapp02/85/P2P-Skip-Graph-Bloom-Filter-15-320.jpg)
![評価 [ ヒットするドキュメント数が変化したときの検索ホップ数 ] ヒットするドキュメントの存在率 (%) 検索ホップ数 ノード数が 500 のとき ヒットする キュメントの存在率を変化 3 進数 4 進数 5 進数 membership vector が2進数 ホップ数はほとんど増加しない](https://image.slidesharecdn.com/2011-iwamoto-dps-110327021643-phpapp02/85/P2P-Skip-Graph-Bloom-Filter-16-320.jpg)
![評価 [ 更新時のホップ数 ] ノード数 メッセージホップ数 3 進数 4 進数 5 進数 更新時のメッセージホップ数 membership vector が2進数 O( w log w N)](https://image.slidesharecdn.com/2011-iwamoto-dps-110327021643-phpapp02/85/P2P-Skip-Graph-Bloom-Filter-17-320.jpg)
![提案手法 [ Bloom Filter の更新ホップ数 ] Level0 Level2 Level1 2 9 5 7 3 8 6 2 9 5 7 3 8 6 3 2 9 5 7 8 6 2 Level3 3 5 7 8 6 9](https://image.slidesharecdn.com/2011-iwamoto-dps-110327021643-phpapp02/85/P2P-Skip-Graph-Bloom-Filter-18-320.jpg)
![評価 [ 更新時のホップ数 ] ノード数 メッセージホップ数 membership vector が2進数 3 進数 4 進数 5 進数 更新時のメッセージホップ数 基数が大きい程更新コストが大きくなる O( w log w N)](https://image.slidesharecdn.com/2011-iwamoto-dps-110327021643-phpapp02/85/P2P-Skip-Graph-Bloom-Filter-19-320.jpg)

![[ ]](https://image.slidesharecdn.com/2011-iwamoto-dps-110327021643-phpapp02/85/P2P-Skip-Graph-Bloom-Filter-21-320.jpg)

























![[アルゴリズムイントロダクション勉強会] ハッシュ](https://cdn.slidesharecdn.com/ss_thumbnails/random-171021132555-thumbnail.jpg?width=640&height=640&fit=bounds)
















