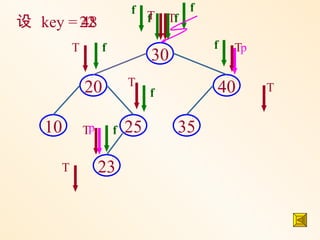
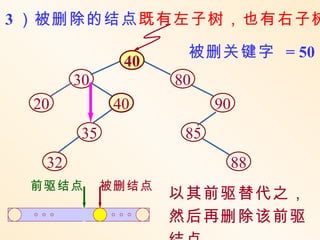
下面讨论平均情况 :
不失一般性,假设长度为 n 的序
列中有 k 个关键字小于第一个关键字
,则必有 n-k-1 个关键字大于第一个关
键字 , 由它构造的二叉排序树:
k n-k-1
的平均查找长度是 n 和 k 的函数
P(n, k) ( 0≤ k ≤ n-1 )
31.
1
P(n, k) =[1 + k * (P(k) + 1) + (n − k − 1) * (P(n − k − 1) + 1)]
n
其中 P(k) 为含有 k 个结点的二叉排序树
的平均查找长度 . 则 P(k)+1 为查找左子树所
用比较次数的平均值 , 而 P(n-k-1) 为查找右子
树中每个结点所用比较次数的平均值 .
32.
假设 n 个关键字的排列是随机的, 即任一
个关键字在序列中将是第 1 个,或第 2
个 , . . . 的概率相同 , 则含 n 个关键字的二
叉排序树的平均查找长度:
n −1
1
ASL = P(n) = ∑ P(n, k)
n k =0
33.
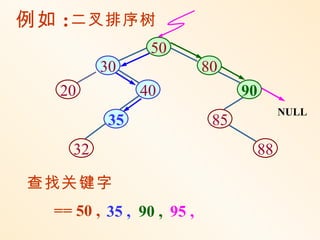
在等概率查找的情况下,
1 n −1 1
P(n) = ∑ 1 + ( k × P(k) + (n − k − 1) × P(n − k − 1))
n k =0 n
n −1
2
= 1+ 2
n
∑ ( k × P(k))
k =1
可类似于解差分方程,此递归方程有解:
n +1
P ( n) = 2 log n + C
n
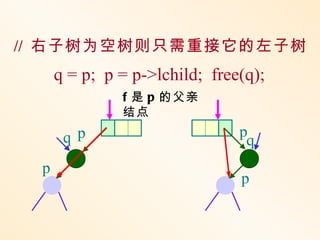
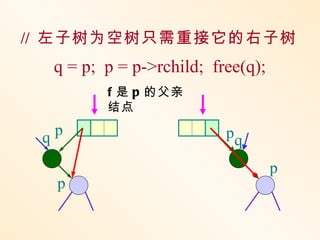
构造二叉平衡(查找)树的方法是:
在插入过程中,采用平衡旋转技术。
假设由于在二叉排序树上插入结
点而
失去平衡的最小子树根结点为 A ,沿插入
路径取直接下两层的结点为 B 和 C ,如果
这
三个结点处于一条直线上,则采用单旋转
进行平衡化;如果这三个结点处于一条折
线
39.
( 1 )单向右旋平衡处理:( LLR)
原因:在 A 的左子树根结点的左子树上插入结点,
的平衡因子由 1 增至 2 ,至使以 A 为根的子树失去平衡
调整方法:以结点 B 为旋转轴,将结点 A 向右旋转
成为
B 的右子树,结点 B 代替原来 A 的位置,原来 B 的右
子树 B
A
成为 A 的左子树。 R
A A
B LL C
BR h h+1 BR AR
C R
h h h h
插入结点
40.
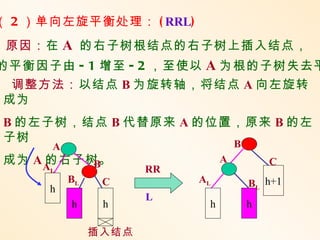
( 2 )单向左旋平衡处理:( RRL)
原因:在 A 的右子树根结点的右子树上插入结点,
的平衡因子由 - 1 增至 - 2 ,至使以 A 为根的子树失去平
调整方法:以结点 B 为旋转轴,将结点 A 向左旋转
成为
B 的左子树,结点 B 代替原来 A 的位置,原来 B 的左
子树 B
A
成为 A A
的右子树。
B A C
L RR
BL C AL BL h+1
h
L
h h h h
插入结点
41.
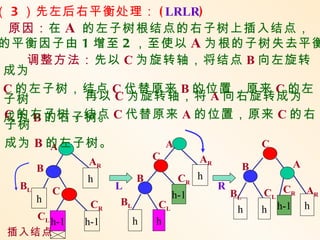
( 3 )先左后右平衡处理:( LRLR)
原因:在 A 的左子树根结点的右子树上插入结点,
的平衡因子由 1 增至 2 ,至使以 A 为根的子树失去平衡
调整方法:先以 C 为旋转轴,将结点 B 向左旋转
成为
C 的左子树,结点 C 代替原来 B 的位置,原来 C 的左
子树 再以 C 为旋转轴,将 A 向右旋转成为
成为 B 的右子树。 C 代替原来 A 的位置,原来 C 的右
C 的右子树,结点
子树
成为 B 的左子树。
A A C
C AR
AR B A
B
h B CR h
BL L R
C h-1 BL CL CR AR
h BL
CR CL h h h-1 h
CL h h
h-1 h-1
插入结点
42.
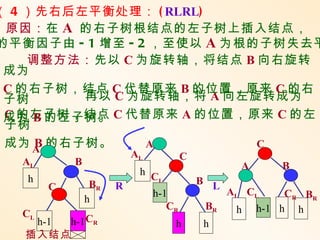
( 4 )先右后左平衡处理:( RLRL)
原因:在 A 的右子树根结点的左子树上插入结点,
的平衡因子由 - 1 增至 - 2 ,至使以 A 为根的子树失去平
调整方法:先以 C 为旋转轴,将结点 B 向右旋转
成为
C 的右子树,结点 C 代替原来 B 的位置,原来 C 的右
子树 再以 C 为旋转轴,将 A 向左旋转成为
成为 B 的左子树。 C 代替原来 A 的位置,原来 C 的左
C 的左子树,结点
子树
成为 A 的右子树。
B A C
AL C
AL B A B
h C
h L B L
C BR R
h-1 AL CL CR BR
h
CR BR h h-1 h h
CL
h-1 h-1 CR h h
插入结点
43.
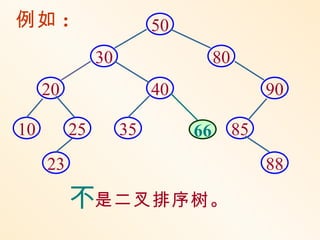
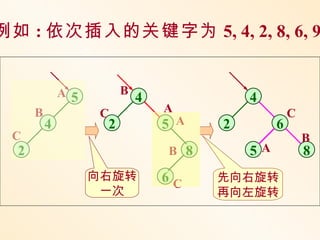
例如 : 依次插入的关键字为5, 4, 2, 8, 6, 9
A 5 B
4 4
B C A C
4 2 5 A 2 6
C B
2 B 8 5A 8
向右旋转 6C 先向右旋转
一次 再向左旋转
44.
向左旋转一次
A
4
B
2 6
C
5 8
B
9 6
A C
4 8
继续插入关键字 2 5 9
9
45.
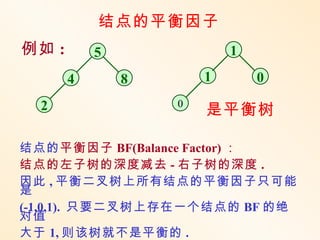
平衡树的查找性能分析:
在平衡树上进行查找的过程和二
叉排序树相同,因此,查找过程中和给
定值进行比较的关键字的个数不超过平
衡 树的深度。
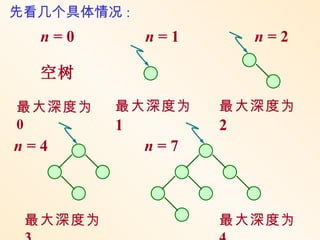
问:含 n 个关键字的二叉平衡
树可能达到的最大深度是多少?
























![1
P(n, k) = [1 + k * (P(k) + 1) + (n − k − 1) * (P(n − k − 1) + 1)]
n
其中 P(k) 为含有 k 个结点的二叉排序树
的平均查找长度 . 则 P(k)+1 为查找左子树所
用比较次数的平均值 , 而 P(n-k-1) 为查找右子
树中每个结点所用比较次数的平均值 .](https://image.slidesharecdn.com/2-120715165028-phpapp01/85/2-31-320.jpg)















![第九章 查找[3]](https://cdn.slidesharecdn.com/ss_thumbnails/3-120715165035-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


![第九章 查找[1]](https://cdn.slidesharecdn.com/ss_thumbnails/1-120715165009-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


![第九章+查找[4]](https://cdn.slidesharecdn.com/ss_thumbnails/4-120715165045-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





























































![第七章 图[4]1](https://cdn.slidesharecdn.com/ss_thumbnails/41-120715164911-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![第七章 图[3]](https://cdn.slidesharecdn.com/ss_thumbnails/3-120715164851-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![第七章 图[2]1](https://cdn.slidesharecdn.com/ss_thumbnails/21-120715164840-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![第七章 图[1]](https://cdn.slidesharecdn.com/ss_thumbnails/1-120715164819-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

