9 函式
修課時間排序 (三)
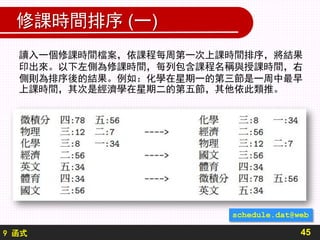
在程式中的排序規則函式,by_weekly_earlier_hr,首先分解各
列取出上課時間,在迴圈中將各個上課時間再度依冒號分解為中文數字與英
文數字字串,由此利用前述方法將各個上課鐘點轉為數字,回傳最小值。在
程式中,中文數字所對應的數字是先在主函式處理存成字典,名稱為 c2n
,再透過 global 方式給排序規則函式使用,這是不得已的作法,因為排
序規則函式僅接受由排序函式 sort 傳入的串列元素參數。在正常的情況
下程式設計要避免使用 global 變數,在下個範例會詳加說明使用
global 的缺點。
47
16.
9 函式
修課時間排序 (四)
48
defmain() :
global c2n
cnum = ’一二三四五’
c2n = dict( [ ( b , a ) for a , b in enumerate(cnum) ] )
with open("schedule.dat") as infile :
schedules = infile.readlines()
#依據課程在一周內最早上課時間排序
schedules.sort( key=by_weekly_earlier_time )
for s in schedules : print( s.rstrip() )
# 設定排序標準
def by_weekly_earlier_time( schedule ) :
global c2n
course , *csect = schedule.split()
all = []
for p in csect :
17.
9 函式
修課時間排序 (五)
49
#拆解上課時間
a , b = p.split(’:’)
w = c2n[a]
# 將此門課所有上課時間以整數表示
for c in b :
s = int(c)
all.append(w*10+s)
# 回傳該門課在一周最早上課時間所代表的整數
return sorted(all)[0]
# 執行主函式
main()
本題另有一種作法,即在讀入課程檔時,立即計算該門課的最早上課時間
對應數字,將課名與數字存入字典 snum,其資料為 {’化學’:3, ’國文
’:25 , ..., }。在排序時,只要用 split() 取得第一筆字串(即課名)
,馬上可使用 snum 得到該課最早上課時間的對應數字,以此數字當成排序
標準。這種程式寫法避免了之前程式需要不斷地執行排序規則函式,會讓程式
執行更有效率。
18.
9 函式
修課時間排序 (六)
50
defmain() :
global snum
cnum = ’一二三四五’
c2n = dict( [ ( b , a ) for a , b in enumerate(cnum) ] )
# 課程與上課時間
schedules = []
# 字典,儲存課名與一周最早上課時間比較數字
snum = {}
# 讀檔
with open("schedule.dat") as infile :
for line in infile :
schedule = line.strip()
schedules += [ schedule ]
# 回傳課程與其一周最早上課時間比較數字
course , num = course_eariler_number(schedule,c2n)
# 存入字典
snum[course] = num
19.
9 函式
修課時間排序 (七)
51
#依據課程在一周內最早上課時間排序
schedules.sort( key = lambda s : snum[s.split()[0]] )
# 列印
for s in schedules :
print( s.strip() )
# 尋找最早上課時間代表數字
def course_earlier_number( schedule , c2n ) :
# 分解課名與上課時間
course , *csect = schedule.split()
all = []
for p in csect :
# 拆解上課時間
a , b = p.split(’:’)
w = c2n[a]
# 將此門課所有上課時間以整數表示
for c in b :
s = int(c)
all.append(w*10+s)
return ( course , min(all) )
# 執行主函式
main()

![9 函式
微分方程式數值求解 (三)
35
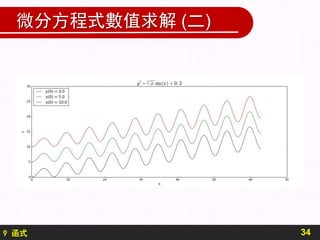
import pylab
#----------------------------------------
# y’ = x**(1/3) sin(x) + 0.2
#
# i.c. y(0) = val val = range(0,11,5)
#----------------------------------------
def fn(x) :
return x**(1/3) * pylab.sin(x) + 0.2
# 設定周邊空白為白色
pylab.figure(facecolor=’white’)
a , b , n = 0 , 20*pylab.pi , 501
dx = (b-a)/(n-1)
# 設定 xs , ys
xs = [ a + i*dx for i in range(n) ]
ys = [None] * n
# c :起始值,在此分別為 0 5 10 三數
# 以下計算相同微分方程式但不同起始值的解答
for c in range(0,11,5) :](https://image.slidesharecdn.com/xw9fmjcntmlm40klkyit-signature-15a100956dc4ac36757d902aef007c07d9a1e9823eeb88f7d8381730ec35fbdb-poli-180818142452/85/Ch9-3-320.jpg)
![9 函式
微分方程式數值求解 (四)
36
ys[0] = c
for i in range(1,n) :
ys[i] = ys[i-1] + dx * fn(xs[i-1])
sym = ’y(0) = ’ + str(ys[0])
pylab.plot(xs,ys,label=sym)
# 設定圖形標頭文字
pylab.title(r”$y’ = sqrt[3]{x}, sin(x) + 0.2$",fontsize=20)
# 設定 X 軸與 Y 軸文字
pylab.xlabel(’X’)
pylab.ylabel(’Y’)
# 設定各線條圖例位置
pylab.legend(loc=’upper left’)
pylab.show()](https://image.slidesharecdn.com/xw9fmjcntmlm40klkyit-signature-15a100956dc4ac36757d902aef007c07d9a1e9823eeb88f7d8381730ec35fbdb-poli-180818142452/85/Ch9-4-320.jpg)




![9 函式
印製年曆 (一)
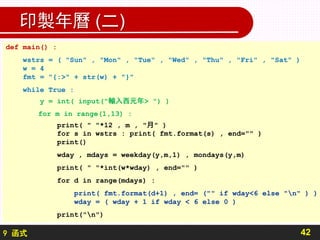
印製年曆首先要應用由日期推算星期幾的公式,此公式如下:
( Y+[Y/4]−[Y/100]+[Y/400]+[2.6 × M−0.2]+D ) mod 7
以上公式中的年(Y)、月(M)兩數字與實際日期的年月是有所差異。在
公式中,每年的三月被當成公式中的一月,四月為二月,次年的一、二月為
公式中當年的十一、十二月。例如:西元日期 2000 年 1 月 1 日,在
公式中的 Y = 1999,M = 11,D = 1。又如西元1999 年 12 月 31
日在公式中 Y = 1999,M = 10,D = 31。公式中的 [x] 為 x 的整
數部份,mod 為餘數運算子。公式回傳 [0,6] 之間整數,分別代表星期
日到星期六。
本範例程式總共有四個函式,除 main 函式外,其他三個函式作用分
別是 (1)計算某年是否為閏年? (2)求得某年月的天數 (3)求得某日是
星期幾。有了這三個函式協同運作,列印年曆過程就變得很直接,程式由兩
層迴圈組成,外迴圈為月份迴圈,內迴圈為日期迴圈。此外程式有兩個小細
節,分別為每月初一的前面空格算法,與要記得每印完星期六後隨即要跳列
。整體來說,年曆列印問題是一個簡單且直接的函式應用問題。
41](https://image.slidesharecdn.com/xw9fmjcntmlm40klkyit-signature-15a100956dc4ac36757d902aef007c07d9a1e9823eeb88f7d8381730ec35fbdb-poli-180818142452/85/Ch9-9-320.jpg)
![9 函式
印製年曆 (三)
43
# 某年是否為閏年
def isleap( y ) :
return True if y%400 == 0 or ( y%100 and y%4 == 0 ) else False
# 某年某月的日數
def mondays( y , m ) :
days = [ 31 , 28 , 31 , 30 , 31 , 30 ,
31 , 31 , 30 , 31 , 30 , 31 ]
if m == 2 :
return 29 if isleap(y) else 28
else :
return days[m-1]
# 計算某年月日星期幾
def weekday( y , m , d ) :
( y , m ) = ( y-1 , m+10 ) if m < 3 else ( y , m - 2 )
return ( y + y//4 - y//100 + y//400 + int(2.6*m-0.2) + d )%7
# 執行主函式
main()](https://image.slidesharecdn.com/xw9fmjcntmlm40klkyit-signature-15a100956dc4ac36757d902aef007c07d9a1e9823eeb88f7d8381730ec35fbdb-poli-180818142452/85/Ch9-11-320.jpg)



![9 函式
修課時間排序 (四)
48
def main() :
global c2n
cnum = ’一二三四五’
c2n = dict( [ ( b , a ) for a , b in enumerate(cnum) ] )
with open("schedule.dat") as infile :
schedules = infile.readlines()
#依據課程在一周內最早上課時間排序
schedules.sort( key=by_weekly_earlier_time )
for s in schedules : print( s.rstrip() )
# 設定排序標準
def by_weekly_earlier_time( schedule ) :
global c2n
course , *csect = schedule.split()
all = []
for p in csect :](https://image.slidesharecdn.com/xw9fmjcntmlm40klkyit-signature-15a100956dc4ac36757d902aef007c07d9a1e9823eeb88f7d8381730ec35fbdb-poli-180818142452/85/Ch9-16-320.jpg)
![9 函式
修課時間排序 (五)
49
# 拆解上課時間
a , b = p.split(’:’)
w = c2n[a]
# 將此門課所有上課時間以整數表示
for c in b :
s = int(c)
all.append(w*10+s)
# 回傳該門課在一周最早上課時間所代表的整數
return sorted(all)[0]
# 執行主函式
main()
本題另有一種作法,即在讀入課程檔時,立即計算該門課的最早上課時間
對應數字,將課名與數字存入字典 snum,其資料為 {’化學’:3, ’國文
’:25 , ..., }。在排序時,只要用 split() 取得第一筆字串(即課名)
,馬上可使用 snum 得到該課最早上課時間的對應數字,以此數字當成排序
標準。這種程式寫法避免了之前程式需要不斷地執行排序規則函式,會讓程式
執行更有效率。](https://image.slidesharecdn.com/xw9fmjcntmlm40klkyit-signature-15a100956dc4ac36757d902aef007c07d9a1e9823eeb88f7d8381730ec35fbdb-poli-180818142452/85/Ch9-17-320.jpg)
![9 函式
修課時間排序 (六)
50
def main() :
global snum
cnum = ’一二三四五’
c2n = dict( [ ( b , a ) for a , b in enumerate(cnum) ] )
# 課程與上課時間
schedules = []
# 字典,儲存課名與一周最早上課時間比較數字
snum = {}
# 讀檔
with open("schedule.dat") as infile :
for line in infile :
schedule = line.strip()
schedules += [ schedule ]
# 回傳課程與其一周最早上課時間比較數字
course , num = course_eariler_number(schedule,c2n)
# 存入字典
snum[course] = num](https://image.slidesharecdn.com/xw9fmjcntmlm40klkyit-signature-15a100956dc4ac36757d902aef007c07d9a1e9823eeb88f7d8381730ec35fbdb-poli-180818142452/85/Ch9-18-320.jpg)
![9 函式
修課時間排序 (七)
51
# 依據課程在一周內最早上課時間排序
schedules.sort( key = lambda s : snum[s.split()[0]] )
# 列印
for s in schedules :
print( s.strip() )
# 尋找最早上課時間代表數字
def course_earlier_number( schedule , c2n ) :
# 分解課名與上課時間
course , *csect = schedule.split()
all = []
for p in csect :
# 拆解上課時間
a , b = p.split(’:’)
w = c2n[a]
# 將此門課所有上課時間以整數表示
for c in b :
s = int(c)
all.append(w*10+s)
return ( course , min(all) )
# 執行主函式
main()](https://image.slidesharecdn.com/xw9fmjcntmlm40klkyit-signature-15a100956dc4ac36757d902aef007c07d9a1e9823eeb88f7d8381730ec35fbdb-poli-180818142452/85/Ch9-19-320.jpg)



![9 函式
中文成語筆劃排序 (五)
56
def main() :
global sdict
# 1:讀入筆畫檔,設定 sdict 字典(由 字-->筆劃)
sdict = {}
read_strokes( sdict )
# 2:讀入成語檔,設定 idioms 成語串列
idioms = []
read_idioms( idioms )
# 3:依各字筆劃數排序
idioms.sort( key = by_strokes )
# 4:列印排序後的成語
print_idioms( idioms , sdict )
# 讀取筆劃檔,設定 sdict 字典(由 字-->筆劃)
def read_strokes( sdict ) :
with open( "strokes.dat" ) as infile :
for line in infile :
ucode , strokes = line.split()
ch = chr(int(ucode[2:],16))
sdict[ch] = int(strokes)](https://image.slidesharecdn.com/xw9fmjcntmlm40klkyit-signature-15a100956dc4ac36757d902aef007c07d9a1e9823eeb88f7d8381730ec35fbdb-poli-180818142452/85/Ch9-24-320.jpg)
![9 函式
中文成語筆劃排序 (六)
57
# 讀入成語檔,設定 idioms 成語串列
def read_idioms( idioms ) :
with open("idioms.dat") as infile :
for line in infile :
idioms += [ line.strip() ]
# 排序標準:依各字筆劃數排序
def by_strokes( idiom ) :
global sdict
return [ sdict[c] for c in idiom ]
# 列印成語
def print_idioms( idioms , sdict ) :
s1 = 0
for ws in idioms :
s2 = sdict[ws[0]]
if s1 != s2 :
if s1 : print()
print( s2 , "劃:" )
print( ws , "-".join( map( lambda c : str(sdict[c]) , ws ) ) )
s1 = s2
# 執行主函式
main()](https://image.slidesharecdn.com/xw9fmjcntmlm40klkyit-signature-15a100956dc4ac36757d902aef007c07d9a1e9823eeb88f7d8381730ec35fbdb-poli-180818142452/85/Ch9-25-320.jpg)





































![[系列活動] 手把手打開Python資料分析大門](https://cdn.slidesharecdn.com/ss_thumbnails/python-171213042421-thumbnail.jpg?width=640&height=640&fit=bounds)







































