Download as PDF, PPTX




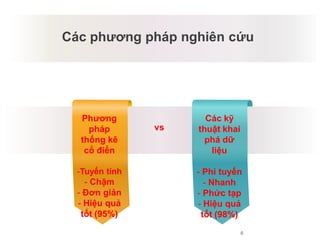






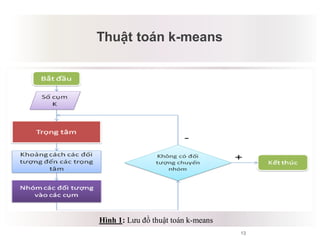

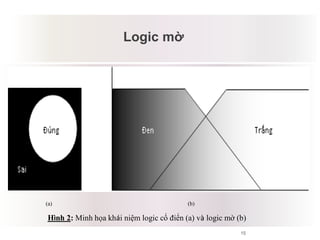




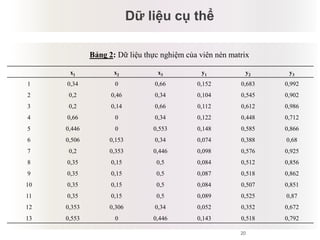
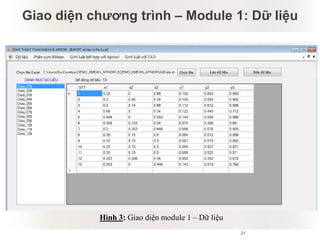
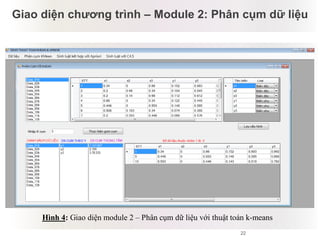

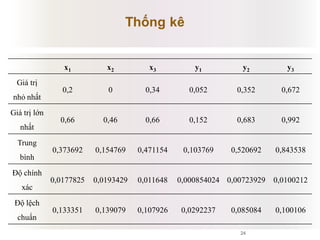
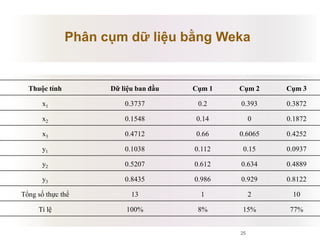

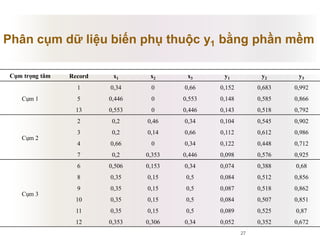
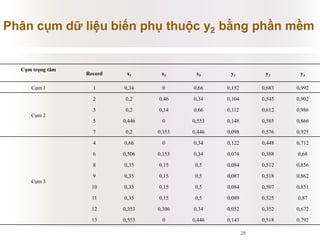
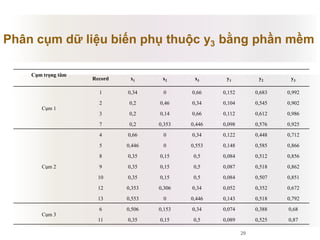






Tài liệu báo cáo về ứng dụng phân cụm dữ liệu trong phân tích công thức dược phẩm, giới thiệu lý thuyết và ứng dụng của thuật toán k-means và logic mờ. Nghiên cứu sử dụng dữ liệu thực nghiệm để kiểm tra biến độc lập và phụ thuộc liên quan đến công thức dược phẩm. Kết luận cho thấy phương pháp này hiệu quả và phù hợp với ngành dược, đồng thời mở ra hướng phát triển mới trong nghiên cứu.



































































