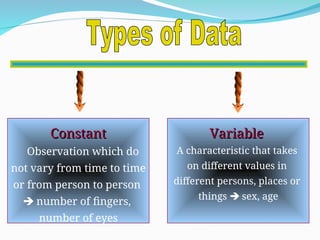
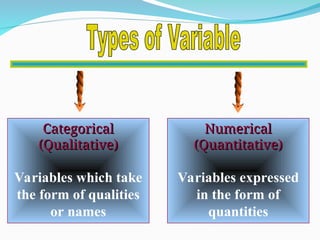
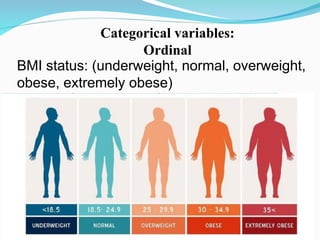
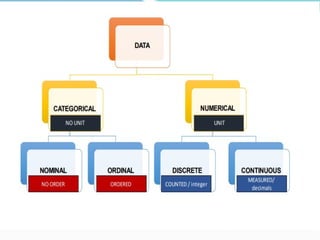
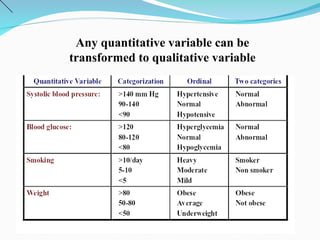
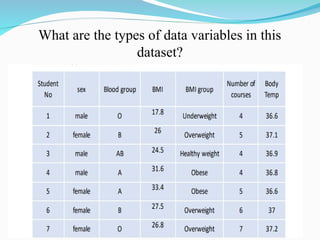
The document outlines a biostatistics course aimed at preventive medicine, covering topics such as types of variables, statistical estimation, hypothesis testing, and data analysis using software like SPSS. It emphasizes the importance of biostatistics for physicians to interpret vital statistics, evaluate research studies, and understand epidemiologic problems. Additionally, it discusses data collection methods, types of variables, data organization, and presentation techniques in statistical analysis.



































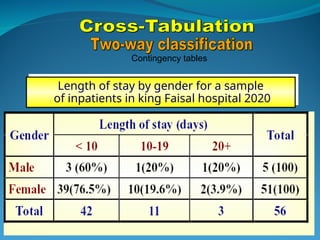
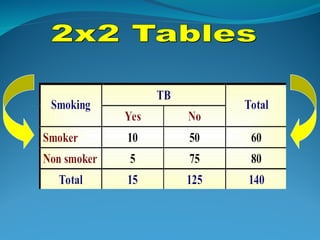
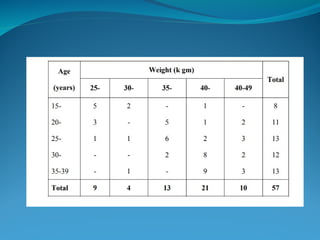















































![ONFH[AVN HIP] -TRIPLE REGIME -A NOVAL SURGICAL CONCEPT .pptx](https://cdn.slidesharecdn.com/ss_thumbnails/onfhavnhip2026koaconcalicutdrgokuldevdrmashraf-260210064517-213ec005-thumbnail.jpg?width=640&height=640&fit=bounds)
