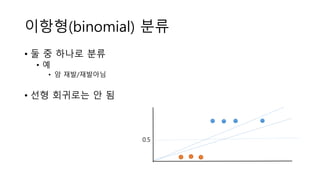
소프트맥스와 다항(multinomial) 분류
•기본 아이디어 각 분류별로 값을 구한 뒤 확률로 변환
𝑤 𝑎1 𝑤 𝑎2 𝑤 𝑎3
𝑤 𝑏1 𝑤 𝑏2 𝑤 𝑏3
𝑤 𝑐1 𝑤 𝑐2 𝑤 𝑐3
×
𝑥1
𝑥2
𝑥3
=
𝑦1
𝑦2
𝑦3
𝑝1
𝑝2
𝑝3
소프트맥스
𝑆 𝑦𝑖 =
𝑒 𝑦𝑗
𝑗 𝑒 𝑦 𝑗
p1 + p2 + p3 = 1.0
24.
소프트맥스 비용함수
• 코로스엔트로피
𝐷 𝑆, 𝐿 = −
𝑖
𝐿𝑖 log 𝑆𝑖
𝑝1
𝑝2
𝑝3
𝑦1
𝑦2
𝑦3
학습데이터 소프트맥스로
구한 확률
𝐿𝑜𝑠𝑠 =
1
𝑚
𝑖
𝐷 𝑆(𝑊𝑋𝑖, 𝐿𝑖)
* 1개 데이터에 대한 값 * 전체 학습 데이터에 대한 값
25.
텐서플로우로 소프트맥스 다항분류 구현하기
xy = np.loadtxt('softmax_train.txt', unpack=False, dtype='float32')
x_data = xy[:, :2] # [8, 2]
y_data = xy[:, 2:] # [8, 3]
X = tf.placeholder(tf.float32, [None, 2]) # [n, 2]
Y = tf.placeholder(tf.float32, [None, 3]) # [n, 3]
W = tf.Variable(tf.zeros([2, 3]))
b = tf.Variable(tf.zeros([3]))
h = tf.nn.softmax(tf.matmul(X, W) + b) # [8, 3], h = softmax(XW + b)
cost = tf.reduce_mean(-tf.reduce_sum(Y*tf.log(h), reduction_indices=1))
optimizer = tf.train.GradientDescentOptimizer(0.001).minimize(cost)
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
for step in range(2001):
sess.run(optimizer, feed_dict={X:x_data, Y:y_data})
if step % 200 == 0:
print (step, sess.run(cost, feed_dict={X: x_data, Y: y_data}),
sess.run(W), sess.run(b))
26.
텐서플로우로 소프트맥스 다항분류 구현하기
a = sess.run(h, feed_dict={X: [[11, 7]]})
print ("a :", a, sess.run(tf.arg_max(a, 1)))
b = sess.run(h, feed_dict={X: [[3, 4]]})
print ("b :", b, sess.run(tf.arg_max(b, 1)))
c = sess.run(h, feed_dict={X: [[1, 0]]})
print ("c :", c, sess.run(tf.arg_max(c, 1)))
a : [[ 0.46272621 0.35483006 0.18244369]] [0]
b : [[ 0.33820099 0.42101386 0.24078514]] [1]
c : [[ 0.27002314 0.29085544 0.4391214 ]] [2]
27.
참고
• 온라인 그래프출력
• https://www.desmos.com/calculator
• 모두를 위한 딥러닝 (김성훈 교수님)
• https://hunkim.github.io/ml/
• 실습한 코드
• https://github.com/madvirus/tfstudy
28.
참고, Anaconda로 설치
•anaconda + jupyter
• 환경 생성
• conda create -n tensorflow python=3.5
• 생성한 환경에서 텐서플로우와 관련 라이브러리 설치
• source activate tensorflow
• pip install tensorflow
• conda install matplotlib
• conda install seaborn
• conda install notebook ipykernel
• ipython kernel install --user
• 참고
• Installation Quickstart: TensorFlow, Anaconda, Jupyte (https://goo.gl/kSeZKI)







![텐서플로우로 선형회귀 구현하기
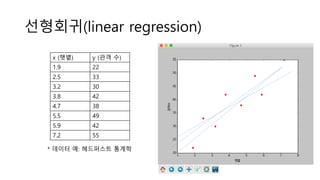
# 학습 데이터
x_data = [1.9, 2.5, 3.2, 3.8, 4.7, 5.5, 5.9, 7.2]
y_data = [22, 33, 30, 42, 38, 49, 42, 55]
import tensorflow as tf
W = tf.Variable(tf.random_uniform([1], -1.0, 1.0))
b = tf.Variable(tf.zeros([1]))
y = W * x_data + b # 가설
loss = tf.reduce_mean(tf.square(y - y_data)) # 차의 제곱 평균
# 경사 하강법
train = tf.train.GradientDescentOptimizer(0.015).minimize(loss)
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
print('FIRST', sess.run(loss), sess.run(W), sess.run(b))
for step in range(1800):
sess.run(train)
if step % 20 == 0:
print(step, sess.run(loss), sess.run(W), sess.run(b))
FIRST 1365.22 [ 0.69029188] [ 0.]
0 180.363 [ 5.76034307] [ 1.07642579]
20 38.5053 [ 7.97524023] [ 2.60947013]
40 35.2595 [ 7.780509] [ 3.57756996]
60 32.475 [ 7.60014772] [ 4.47422886]
…
…
…
1420 15.671 [ 5.34873962] [ 15.66702652]
1440 15.6709 [ 5.34782982] [ 15.6715498]
1460 15.6708 [ 5.34698725] [ 15.67573929]
1480 15.6708 [ 5.34620667] [ 15.67961884]
1500 15.6707 [ 5.34548378] [ 15.68321228]
1520 15.6707 [ 5.3448143] [ 15.6865406]
1540 15.6707 [ 5.34419394] [ 15.68962383]
1560 15.6706 [ 5.34361982] [ 15.69247818]
1580 15.6706 [ 5.34308767] [ 15.69512367]
1600 15.6706 [ 5.3425951] [ 15.69757462]
1620 15.6706 [ 5.34213877] [ 15.69984341]
1640 15.6706 [ 5.34171629] [ 15.7019434]
1660 15.6705 [ 5.34132433] [ 15.70388889]](https://image.slidesharecdn.com/tensorflowregression-161122032922/85/Tensorflow-regression-10-320.jpg)
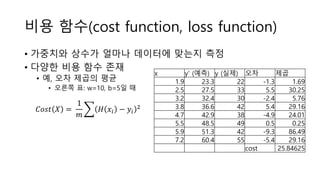
![Matplotlib로 결과 출력
import matplotlib
matplotlib.rcParams['font.family'] = 'NanumBarunGothic'
import matplotlib.pyplot as plt
plt.plot(x_data, y_data, 'ro')
plt.plot(x_data, sess.run(W) * x_data + sess.run(b))
plt.xlabel('햇볕')
plt.ylabel('관객수')
plt.legend()
plt.show()](https://image.slidesharecdn.com/tensorflowregression-161122032922/85/Tensorflow-regression-11-320.jpg)


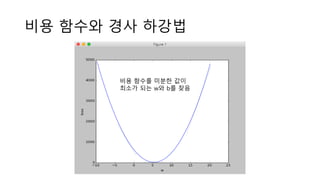
![텐서플로우로 로지스틱 회귀 구현하기
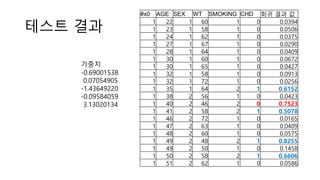
• 데이터 예
• 아빠가 들려 주는 [통계] 로지스
틱 회귀분석 후 ROC 커브 그리
기 (https://goo.gl/bxcn4c)
#x0 AGE SEX WT SMOKING CHD
1 22 1 60 1 0
1 23 1 58 1 0
1 24 1 62 1 0
1 27 1 67 1 0
1 28 1 64 1 0
1 30 1 60 1 0
1 30 1 65 1 0
1 32 1 58 1 0
1 32 1 72 1 0
1 35 1 64 2 1
1 38 2 56 1 0
1 40 2 46 2 0
1 41 2 58 2 1
1 46 2 72 1 0
1 47 2 63 1 0
1 48 2 60 1 0
1 49 2 48 2 1
1 49 2 50 1 0
1 50 2 58 2 1
1 51 2 62 1 0](https://image.slidesharecdn.com/tensorflowregression-161122032922/85/Tensorflow-regression-18-320.jpg)
![텐서플로우로 로지스틱 회귀 구현하기
* https://github.com/FuZer/Study_TensorFlow 참고
import tensorflow as tf
import numpy as np
xy = np.loadtxt('logistic_train2.txt', unpack=True, dtype='float32')
x_data = xy[0:-1] # [5, 20]
y_data = xy[-1] # [1, 20]
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
W = tf.Variable(tf.random_uniform([1, len(x_data)], -1.0, 1.0)) # [1, 5]
h = tf.matmul(W, X) # [1, 20]
hypothesis = tf.sigmoid(h)
cost = -tf.reduce_mean(Y * tf.log(hypothesis) + (1 - Y) * tf.log(1 - hypothesis))
a = tf.Variable(0.0015) # learning rate
optimizer = tf.train.GradientDescentOptimizer(a)
train = optimizer.minimize(cost) # goal is minimize cost
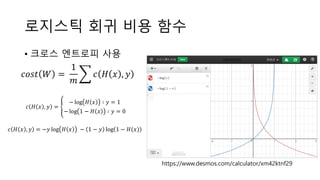
𝑐𝑜𝑠𝑡 𝑊 =
1
𝑚
𝑐 𝐻𝑦𝑝𝑜 𝑥 , 𝑦
𝑐 𝐻 𝑥 , 𝑦 = −𝑦 log 𝐻 𝑥 − 1 − 𝑦 log 1 − 𝐻(𝑥)
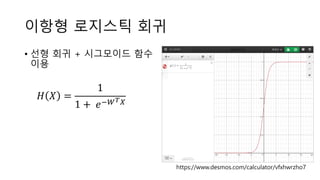
𝐻𝑦𝑝𝑜 𝑋 =
1
1 + 𝑒−𝑊 𝑇 𝑋](https://image.slidesharecdn.com/tensorflowregression-161122032922/85/Tensorflow-regression-19-320.jpg)
![* https://github.com/FuZer/Study_TensorFlow 참고
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
for step in range(20001): # 10,000-60,000까지 변경해가며 해 봤음
sess.run(train, feed_dict={X: x_data, Y: y_data})
if step % 200 == 0:
print (step, sess.run(cost, feed_dict={X: x_data, Y: y_data}), sess.run(W))
print('-----------------------------------------')
print(sess.run(hypothesis, feed_dict={X: [[1], [35], [1], [64], [2]]}) > 0.5)
0.199018 [[-0.69001538 0.07054905 -1.43649220 -0.09584059 3.13020134]]
0.195910 [[-0.53398216 0.02894925 -0.96797615 -0.09904154 3.71121287]]
텐서플로우로 로지스틱 회귀 구현하기](https://image.slidesharecdn.com/tensorflowregression-161122032922/85/Tensorflow-regression-20-320.jpg)



![텐서플로우로 소프트맥스 다항 분류 구현하기
xy = np.loadtxt('softmax_train.txt', unpack=False, dtype='float32')
x_data = xy[:, :2] # [8, 2]
y_data = xy[:, 2:] # [8, 3]
X = tf.placeholder(tf.float32, [None, 2]) # [n, 2]
Y = tf.placeholder(tf.float32, [None, 3]) # [n, 3]
W = tf.Variable(tf.zeros([2, 3]))
b = tf.Variable(tf.zeros([3]))
h = tf.nn.softmax(tf.matmul(X, W) + b) # [8, 3], h = softmax(XW + b)
cost = tf.reduce_mean(-tf.reduce_sum(Y*tf.log(h), reduction_indices=1))
optimizer = tf.train.GradientDescentOptimizer(0.001).minimize(cost)
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
for step in range(2001):
sess.run(optimizer, feed_dict={X:x_data, Y:y_data})
if step % 200 == 0:
print (step, sess.run(cost, feed_dict={X: x_data, Y: y_data}),
sess.run(W), sess.run(b))](https://image.slidesharecdn.com/tensorflowregression-161122032922/85/Tensorflow-regression-25-320.jpg)
![텐서플로우로 소프트맥스 다항 분류 구현하기
a = sess.run(h, feed_dict={X: [[11, 7]]})
print ("a :", a, sess.run(tf.arg_max(a, 1)))
b = sess.run(h, feed_dict={X: [[3, 4]]})
print ("b :", b, sess.run(tf.arg_max(b, 1)))
c = sess.run(h, feed_dict={X: [[1, 0]]})
print ("c :", c, sess.run(tf.arg_max(c, 1)))
a : [[ 0.46272621 0.35483006 0.18244369]] [0]
b : [[ 0.33820099 0.42101386 0.24078514]] [1]
c : [[ 0.27002314 0.29085544 0.4391214 ]] [2]](https://image.slidesharecdn.com/tensorflowregression-161122032922/85/Tensorflow-regression-26-320.jpg)

































![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 4장. 모델 훈련](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180814064959-thumbnail.jpg?width=640&height=640&fit=bounds)











![[GomGuard] 뉴런부터 YOLO 까지 - 딥러닝 전반에 대한 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/part1mlp2cnn-slidesharev-180308015531-thumbnail.jpg?width=640&height=640&fit=bounds)
























