4.ゴミ焼却場の不動産価格への
影響を知りたい。
House Pricesduring Siting Decision Stages: The Case of an
Incinerator from Rumor through Operation
http://www.fsb.miamioh.edu/lij14/420_paper_house.pdf
KIELMC.dtaを利用
North Andoverで1978年以降に将来ゴミ焼却場が建設されるとい
う噂が流れ始め、実際に1981年に建設が始まった。
1978年と1981年の家の取引データから、ゴミ焼却場の建設によっ
て、家の価格が落ちたかを検証したい。また、建設地に近い程強
い影響を受けているかを知りたい。
この研究の単純化ver
22.
Simple Model
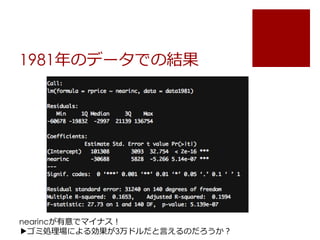
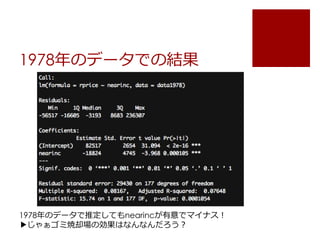
price= a + b*nearinc + error を1981年のデータで推定
Nearinc(ゴミ焼却場に近いか?のダミー)で価格に影響がある
のか?
data <- read.dta("data/KIELMC.dta")
data1981 <- subset(data, year == 1981)
reg.1 <- lm(rprice ~ nearinc, data = data1981)
summary(reg.1)









![推定された線を上に書く
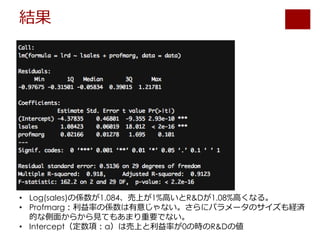
plot(data$lsales, data$lrd, xlab = "sales", ylab = "log(R&D)")
abline(a = result$coefficients["(Intercept)"], b=result$coefficients["lsales"])
ablineで指定した傾きと定数を持った線をかける。
aは定数なので、回帰分析の結果から定数項の値を持ってくる。
bは傾きなので、回帰分析の結果からlsalesの結果を持ってくる。](https://image.slidesharecdn.com/tokyor201502-150221092753-conversion-gate01/85/slide-10-320.jpg)


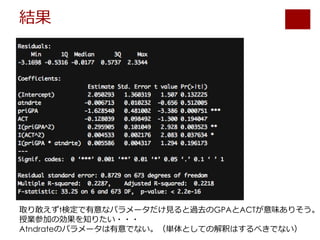

![授業参加の効果(atndrte)
• 期末成績への効果 = -0.0067*参加率 + 0.0056*参加率*priGPA
• 参加率単体のパラメーターはpriGPAが0の時の参加率の効果となる。
• priGPAの平均は2.59。この時の参加率の効果を知りたい。
> mean(data$priGPA)
[1] 2.586775
• 平均的な成績の生徒が10%多く授業に参加すると、平均して成績は0.078上
がる。
• 成績は平均からの乖離を標準偏差で割った値のデータなので、10%の参加率
の上昇で成績は0.078標準偏差上がる。
• この結果は有意に0と異なるのだろうか?](https://image.slidesharecdn.com/tokyor201502-150221092753-conversion-gate01/85/slide-15-320.jpg)