Downloaded 28 times










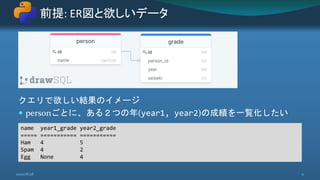
![class Person(models.Model):
class Meta:
db_table = 'person'
name = models.CharField('名前', max_length=255)
class Grade(models.Model):
class Meta:
db_table = 'grade'
year = models.IntegerField('年度')
person = models.ForeignKey(Person, on_delete=models.CASCADE)
seiseki = models.IntegerField('成績', validators=[
MinValueValidator(1),
MaxValueValidator(5)
])
Django ORMの定義例
2020/8/28 12](https://image.slidesharecdn.com/simple-way-with-django-sqlalchemy-20200828-200828085715/85/Django-SQLAlchemy-Way-12-320.jpg)


![外部キー制約が定義されていないModelのJOIN
extrasを使えば、内部結合(INNER JOIN相当)は可能
ただし INNER JOIN と異なり、gradeに値がないpersonは除外される。
LEFT OUTER JOIN は表現できない。
そして、コードの理解が難しくなるので書きたくない...
Django ORMで表現が難しいSQL: FKなし1
2020/8/28 16
# GradeモデルにForeignKeyを定義していない場合
>>> qs = Person.objects.extra(
... tables=['grade'],
... where=['grade.person_id=person.id', 'grade.year=2019']
... ).extra(select={'seiseki': 'grade.seiseki'})
SELECT (grade.seiseki) AS seiseki, person.id, person.name
FROM person, grade
WHERE (grade.person_id=person.id)
AND (grade.year=2019)
extra は最終手段、将来廃止予定
― QuerySet API reference より
(´・ω・`)色々な事情が
ありましてね・・・](https://image.slidesharecdn.com/simple-way-with-django-sqlalchemy-20200828-200828085715/85/Django-SQLAlchemy-Way-16-320.jpg)
![「関連」をModelに設定すれば、普通のORMコードでJOIN可能になる
外部キー制約(ForeignKey)を定義できない状況(マイグレーションでDB
に反映されては困る時)の回避策として使える。
extraで頑張るより良い。
だが、ドキュメントに記載されていない (´・ω・`)
Django ORMで表現が難しいSQL: FKなし2
2020/8/28 17
明示的な関連のない2つのモデルを
JOINする方法は?
― Django Issue #29551 より
class Grade(models.Model):
person_id = models.IntegerField('Person')
person = ForeignObject(
Person,
models.CASCADE,
from_fields=['person_id'],
to_fields=['id']
)](https://image.slidesharecdn.com/simple-way-with-django-sqlalchemy-20200828-200828085715/85/Django-SQLAlchemy-Way-17-320.jpg)







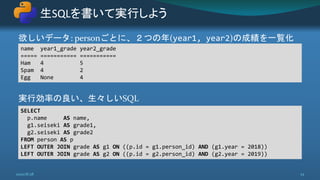
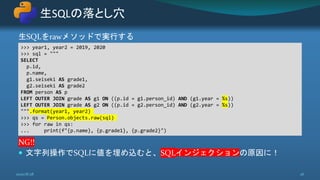
![プレースホルダ (%s) を使い、ドライバ側で値をエスケープ処理する
課題
動的な条件追加などは文字列操作しかない(WHERE句追加など)
パラメータのエスケープ処理
2020/8/28 27
>>> year1, year2 = 2019, 2020
>>> sql = """
SELECT
p.id,
p.name,
g1.seiseki AS grade1,
g2.seiseki AS grade2
FROM person AS p
LEFT OUTER JOIN grade AS g1 ON ((p.id = g1.person_id) AND (g1.year = %s))
LEFT OUTER JOIN grade AS g2 ON ((p.id = g2.person_id) AND (g2.year = %s))
"""
>>> qs = Person.objects.raw(sql, [year1, year2])
>>> for raw in qs:
... print(f"{p.name}, {p.grade1}, {p.grade2}")
生SQLを使う前に、ORMの使用を考え
て! ― 素の SQL 文の実行 より](https://image.slidesharecdn.com/simple-way-with-django-sqlalchemy-20200828-200828085715/85/Django-SQLAlchemy-Way-27-320.jpg)



![テーブル定義 (ORMのモデル定義が不要な場合)
クエリビルダ実行例 (SQLの文法に近い表現)
SQLAlchemyのテーブル定義と実行
2020/8/28 31
import sqlalchemy as sa
metadata = sa.MetaData()
person = sa.Table(
'person',
metadata,
sa.Column('id', sa.Integer),
sa.Column('name', sa.String),
)
>>> stmt = sa.select([person]).where(person.c.name.contains('a'))
>>> print(stmt)
SELECT person.id, person.name
FROM person
WHERE (person.name LIKE '%' || :name_1 || '%')](https://image.slidesharecdn.com/simple-way-with-django-sqlalchemy-20200828-200828085715/85/Django-SQLAlchemy-Way-31-320.jpg)
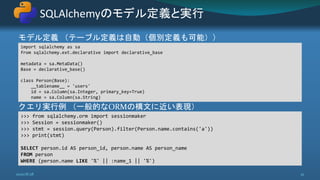


![SQLビルダーの書き味はほぼSQL
ほぼSQLをPythonコードで書けるのが最大のメリット
SQLAlchemyのクエリステートメント
2020/8/28 35
import sqlalchemy as sa
year1, year2 = 2019, 2020
g1 = grade.alias('g1') # AS g1
g2 = grade.alias('g2') # AS g2
stmt = sa.select([
person.c.id,
person.c.name,
g1.c.seiseki.label('grade1'),
g2.c.seiseki.label('grade2'),
]).select_from(
person.
outerjoin(g1, sa.and_(g1.c.person_id == person.c.id, g1.c.year == year1)).
outerjoin(g2, sa.and_(g2.c.person_id == person.c.id, g2.c.year == year2))
)](https://image.slidesharecdn.com/simple-way-with-django-sqlalchemy-20200828-200828085715/85/Django-SQLAlchemy-Way-35-320.jpg)
![sqliteのdialect(方言)に変換
SQLAでの実装コードそのままのSQLが生成される
compile時に接続先RDB用のdialectを選ぶ必要がある
SQLAlchemyで生成されるSQL
2020/8/28 36
>>> from sqlalchemy.dialects.sqlite import dialect
>>> query = stmt.compile(dialect=dialect())
>>> sql, params = str(query), query.params
>>> print(sql)
>>> print('params=', params)
SELECT
person.id,
person.name,
g1.seiseki AS grade1,
g2.seiseki AS grade2
FROM person
LEFT OUTER JOIN grade AS g1 ON g1.person_id = person.id AND g1.year = %s
LEFT OUTER JOIN grade AS g2 ON g2.person_id = person.id AND g2.year = %s
params= [2019, 2020]](https://image.slidesharecdn.com/simple-way-with-django-sqlalchemy-20200828-200828085715/85/Django-SQLAlchemy-Way-36-320.jpg)
![ SQLAlchemyからRDBに接続するために独自のコネクションは使いたくない
Djangoの設定と別に管理したくない、コネクションを共存したい
Djangoのconnectionを使ってSQLを実行
結果は行毎に値のタプルとなるため、行毎の辞書に変換
SQLAlchemyとDjangoの共存
2020/8/28 37
from django.db import transaction
def execute_raw_sql(sql, params):
conn = transaction.get_connection()
with conn.cursor() as cursor:
cursor.execute(sql, params)
yield from cursor
def execute(stmt):
sql, params = ... # compile等
results = execute_raw_sql(sql, params)
columns = [c.name for c in stmt.columns]
for row in results:
yield dict(zip(columns, row))](https://image.slidesharecdn.com/simple-way-with-django-sqlalchemy-20200828-200828085715/85/Django-SQLAlchemy-Way-37-320.jpg)



![インストール
Django settings.py
Django Modelに sa が生えるので、sa経由で実行
.sa 以降はSQLAlchemyのORM
Aldjemyの設定
2020/8/28 41
$ pip install aldjemy
INSTALLED_APPS = [
...
'aldjemy',
]
>>> Person.sa.query().filter(Person.sa.name.contains('a')).all()
[<aldjemy.orm.Person object at 0x0000026D09D49220>,
<aldjemy.orm.Person object at 0x0000026D09D49310>]](https://image.slidesharecdn.com/simple-way-with-django-sqlalchemy-20200828-200828085715/85/Django-SQLAlchemy-Way-41-320.jpg)
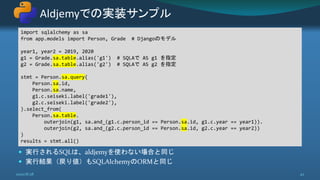


![join か outerjoin を明示的に指定
INNER JOIN / LEFT OUTER JOIN
2020/8/28 45
>>> stmt = sa.select([
... person.c.name,
... grade.c.year,
... grade.c.seiseki,
... ]).select_from(
... person.outerjoin(grade,
... sa.and_(grade.c.person_id == person.c.id, grade.c.year == 2019))
... )
SELECT person.name, grade.year, grade.seiseki
FROM person
LEFT OUTER JOIN grade ON grade.person_id = person.id AND grade.year = %s
name year seiseki
===== ==== =======
Ham 2019 4
Spam 2019 4
Egg None None](https://image.slidesharecdn.com/simple-way-with-django-sqlalchemy-20200828-200828085715/85/Django-SQLAlchemy-Way-45-320.jpg)
![FKがある場合
JOINの明示は必要だが、ON句は不要
FKがない場合
ON句を指定できます
FKのあるJOIN, FKのないJOIN
2020/8/28 46
>>> stmt = sa.select([
... person.c.name,
... grade.c.seiseki,
... ]).select_from(
... person.join(grade)
... )
>>> stmt = sa.select([
... person.c.name,
... grade.c.seiseki,
... ]).select_from(
... person.join(grade, grade.c.person_id==person.c.id)
... )](https://image.slidesharecdn.com/simple-way-with-django-sqlalchemy-20200828-200828085715/85/Django-SQLAlchemy-Way-46-320.jpg)
![セルフJOIN
2020/8/28 47
>>> g1, g2 = grade.alias('g1'), grade.alias('g2')
>>> stmt = sa.select([
... person.c.name,
... g2.c.year,
... g1.c.seiseki.label('last_year_grade'),
... g2.c.seiseki.label('current_year_grade'),
... (g2.c.seiseki - g1.c.seiseki).label('diff'),
... ]).select_from(
... g1.join(person).join(g2,
... sa.and(g1.c.person_id == g2.c.person_id, g1.c.year == g2.c.year + 1))
... ).order_by(person.c.id, g1.c.year)
SELECT person.name, g2.year,
g1.seiseki AS last_year_grade,
g2.seiseki AS current_year_grade,
g2.seiseki - g1.seiseki AS diff
FROM grade AS g1
JOIN person ON person.id = g1.person_id
JOIN grade AS g2 ON g1.person_id = g2.person_id
AND g1.year = g2.year + %s
ORDER BY person.id, g1.year](https://image.slidesharecdn.com/simple-way-with-django-sqlalchemy-20200828-200828085715/85/Django-SQLAlchemy-Way-47-320.jpg)





Simple Way with Django + SQLAlchemy AT PyCon JP 2020 https://pycon.jp/2020/timetable/?id=203756 質疑応答 > Ryuji Tsutsui から全員に: 02:58 PM > INNNER JOIN > Nが1個多い? ほんとだ。slideshareにあげた資料、直せません! > Taku Shimizu から全員に: 03:00 PM > 「ドキュメントに記載されていない」なかなかのパワーフレーズですね でしょー > uranusjr から全員に: 03:04 PM > g2の別名はT3になるのはなぜですか? Djangoが自動的にテーブルを2回JOINすることもあって、そういう場合自動的にテーブル名の別名が付けられます。T2,T3,T4と連番で増えていきます。 たぶん、登場する3つ目のテーブルだからT3なのだと思います。 `annotate(g2=FilteredRelation(...)` のように名前指定しているのに使われないのは、バグなのかどうなのか追ってません。SQLは動作するので、バグとはいえないかも。 > Manabu から全員に: 03:17 PM > SQLAlchemy の モデルクラスを直接書いていましたが、 automap_base() は使わないのですか? 全テーブルを使いたいわけではないのと、用途の目的から、SQLAlchemyでForeignKeyを独自に追加定義したいなどもあるため、個別に書いています。 automap_base()を使っても良いと思います。 > c-bata から全員に: 03:19 PM > DBのマイグレーションはalembicを使う感じでしょうか? Dango ORM側で全てマイグレーションするか、それ以外(alembicや生DDL)でマイグレーションするかは統一すればよいと思います。 Django ORM側でやるのが楽だと思いますが、Redshiftなどの場合生DDLでやるしかなかったりするし、そういう環境でこそこの方法が有用だったりします。 > あ、基本的にDjango ORMを使っていて、難しいクエリだけSQLALchemyで SQL生成している感じですかね。 はい。そういう感じです。



































































