송춘자 cjsong@naver.com
ChemEssen,Inc개발부서장
고려대학교 컴퓨터정보통신대학원 소프트웨어공학과
‘16 PostgreSQL DB 시작
‘99 web program 시작
‘97 Oracle Process Monitoring tool 제작 by PB
‘96 OCP-DBA 7.3 취득
‘93 UNIX & C System program 시작
3.
About ChemEssen, Inc
2006 설립, 40개 기술특허, 글로벌 웹서비스
화학기술과 정보기술의 융합 서비스 제공
Chemical Quantum Application + Mathematical Modeling + IT
4.
검색 속도 개선상황 발생
신규 자료 입력 발생
Master data 285만건 1억6백만건, 37배 증가
Master data size 25 GB 1 TB, 40배 증가
검색속도 저하 발생
651 msec 10분 17초, 948 배 증가 (ID)
1.2 초 7분 20초, 367 배 증가 (name)
773 msec 10분, 776 배 증가 (smiles)
Chemical data 특수성
IUPAC Name
• (3R,6R,7R)-2,3,7-trimethyl-6-(propan-2-yl)tetradecane
• N'-[(2E)-3-(3,4-dimethoxyphenyl)prop-2-enoyl]-2-phenylacetohydrazide
Smiles
• CC(C)CCCC(C)C3CCC4C2CC=C1CC(O)CCC1(C)C2CCC34C
Formula
• C27H46O
• C11H14O3S2
5.
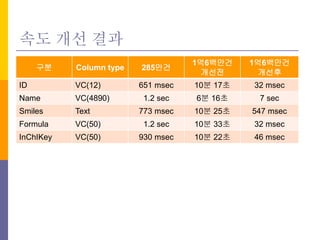
속도 개선 결과
구분Column type 285만건
1억6백만건
개선전
1억6백만건
개선후
ID VC(12) 651 msec 10분 17초 32 msec
Name VC(4890) 1.2 sec 6분 16초 7 sec
Smiles Text 773 msec 10분 25초 547 msec
Formula VC(50) 1.2 sec 10분 33초 32 msec
InChIKey VC(50) 930 msec 10분 22초 46 msec
6.
속도개선방법
개발소스에서 사용중인SQL query 변경
업무규칙 변경 가능 부분 협의 적용
Index 재생성
Text Search 기능 적용
DBMS Parameter 조정
7.
Text Search 기능적용 순서
검색 전용 tsvector 컬럼 추가
ALTER TABLE chemicalsc.tb_chem_info
ADD COLUMN textsearchable_index_col tsvector;
Data update
UPDATE chemicalsc.tb_chem_info SET textsearchable_index_col
= to_tsvector('english', coalesce(replace(upper(iupac_name), ' ', ''), ''));
Gin 인덱스 생성
CREATE INDEX idx_chem_info_textsearchable_index_col
ON chemicalsc.tb_chem_info USING gin (textsearchable_index_col)
TABLESPACE tbs_chemical_idx00;
8.
Sql query -개선 전
SELECT chem_info_id, iupac_name,
(length('Benzene') - length(iupac_name) + 100) as jaro
FROM chemicalsc.tb_chem_info
WHERE iupac_name_upper_stuck like replace(upper( '%Benzene%' ), ' ', '' )
ORDER BY jaro desc, iupac_name asc
LIMIT 2000;
9.
Sql query -개선 후
SET work_mem to '100MB';
SELECT chem_info_id, iupac_name,
(length('benzen’) - length(iupac_name)+100) as jaro
FROM chemicalsc.tb_chem_info
WHERE textsearchable_index_col @@ to_tsquery('english', 'benzen')
ORDER BY jaro desc, iupac_name asc
LIMIT 2000;
10.
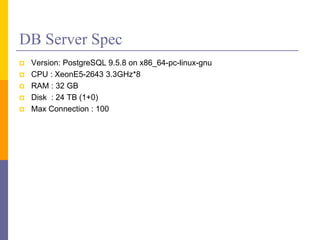
DB Server Spec
Version: PostgreSQL 9.5.8 on x86_64-pc-linux-gnu
CPU : XeonE5-2643 3.3GHz*8
RAM : 32 GB
Disk : 24 TB (1+0)
Max Connection : 100
11.
postgresql.conf
effective_cache_size
데이터캐싱에 사용할 수 있는 메모리 양
인덱스 사용여부 결정
shaed_buffers할당메모리+사용가능한OS캐시 메모리
시스템 전체메모리 *(50% ~ 75%)
32GB * 50% = 16GB, 32GB * 75% = 24GB
maintenance_work_mem
Vacuum, create index 작업시 사용
1GB당50MB
32 * 50MB = 1,600 MB
shared_buffers
Disk IO최소화 목적
시스템 전체 메모리 *25%
32 GB * 0.25 = 8 GB
Data update하면서…
인덱스생성은 data insert / update 이후 생성
인덱스 생성된 상태에서
data file 301개 update 처리진행 42일 소요
Vaccum 설정 check 필수 – 1억건 이상
data file 301개 auto vaccum 처리 10일 소요
데이터 insert 시 COPY command 이용
set command 이후 copy command
Source data 파일 여러 개 분할하여 COPY 진행
입력 실패시 재작업 최소화



![검색 속도 개선 상황 발생
신규 자료 입력 발생
Master data 285만건 1억6백만건, 37배 증가
Master data size 25 GB 1 TB, 40배 증가
검색속도 저하 발생
651 msec 10분 17초, 948 배 증가 (ID)
1.2 초 7분 20초, 367 배 증가 (name)
773 msec 10분, 776 배 증가 (smiles)
Chemical data 특수성
IUPAC Name
• (3R,6R,7R)-2,3,7-trimethyl-6-(propan-2-yl)tetradecane
• N'-[(2E)-3-(3,4-dimethoxyphenyl)prop-2-enoyl]-2-phenylacetohydrazide
Smiles
• CC(C)CCCC(C)C3CCC4C2CC=C1CC(O)CCC1(C)C2CCC34C
Formula
• C27H46O
• C11H14O3S2](https://image.slidesharecdn.com/cjsongpostgresqldbtuningexam-20171102-171106043044/85/Pgday-Seoul-2017-7-PostgreSQL-DB-Tuning-4-320.jpg)









![[Pgday.Seoul 2020] SQL Tuning](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-201117134901-thumbnail.jpg?width=640&height=640&fit=bounds)
![[pgday.Seoul 2022] PostgreSQL구조 - 윤성재](https://cdn.slidesharecdn.com/ss_thumbnails/pgday2022-postgresql-20221112-221114014106-bbfb1955-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2021] 1. 예제로 살펴보는 포스트그레스큐엘의 독특한 SQL](https://cdn.slidesharecdn.com/ss_thumbnails/sql-211217063145-thumbnail.jpg?width=640&height=640&fit=bounds)
![[pgday.Seoul 2022] POSTGRES 테스트코드로 기여하기 - 이동욱](https://cdn.slidesharecdn.com/ss_thumbnails/postgres-221114014538-b9df2ddf-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2021] 2. Porting Oracle UDF and Optimization](https://cdn.slidesharecdn.com/ss_thumbnails/oracleudfmigration20211203-211227052428-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Pgday.Seoul 2019] Citus를 이용한 분산 데이터베이스](https://cdn.slidesharecdn.com/ss_thumbnails/citus20191207studypgday-191218045308-thumbnail.jpg?width=640&height=640&fit=bounds)












![[db tech showcase Tokyo 2014] B26: PostgreSQLを拡張してみよう by SRA OSS, Inc. 日本支社 高塚遥](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014b26postgresqlharukatakatsuka-141120010548-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)








![[pgday.Seoul 2022] 서비스개편시 PostgreSQL 도입기 - 진소린 & 김태정](https://cdn.slidesharecdn.com/ss_thumbnails/postgresql-221121085744-f0fb1a8a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Foss4 g2013 korea]postgis와 geoserver를 이용한 대용량 공간데이터 기반 일기도 서비스 구축 사례](https://cdn.slidesharecdn.com/ss_thumbnails/foss4g2013koreapostgisgeoserver-140325221011-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[2015-06-26] Oracle 성능 최적화 및 품질 고도화 3](https://cdn.slidesharecdn.com/ss_thumbnails/2015-06-26oracle3-150623063728-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)


![[2015 07-06-윤석준] Oracle 성능 최적화 및 품질 고도화 4](https://cdn.slidesharecdn.com/ss_thumbnails/2015-07-06-oracle4-150702090606-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Pgday.Seoul 2018] PostgreSQL 11 새 기능 소개](https://cdn.slidesharecdn.com/ss_thumbnails/pgday2018-pg11-181112042714-thumbnail.jpg?width=640&height=640&fit=bounds)









![[pgday.Seoul 2022] PostgreSQL with Google Cloud](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-postgresqlwithgooglecloud-221114013605-5def484f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2018] 이기종 DB에서 PostgreSQL로의 Migration을 위한 DB2PG](https://cdn.slidesharecdn.com/ss_thumbnails/04-pgdaydb2pgv1-181112042107-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Pgday.Seoul 2017] 6. GIN vs GiST 인덱스 이야기 - 박진우](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-171106044702-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2017] 2. PostgreSQL을 위한 리눅스 커널 최적화 - 김상욱](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-171106040432-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2017] 3. PostgreSQL WAL Buffers, Clog Buffers Deep Dive - 이근오](https://cdn.slidesharecdn.com/ss_thumbnails/pgday171104-171106041604-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2017] 1. PostGIS의 사례로 본 PostgreSQL 확장 - 장병진](https://cdn.slidesharecdn.com/ss_thumbnails/postgispostgresqlpgday2017-171103060406-171106044046-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2017] 8. PostgreSQL 10 새기능 소개 - 김상기](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-seoul-2017-pg10-new-features-171106041845-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2018] Greenplum의 노드 분산 설계](https://cdn.slidesharecdn.com/ss_thumbnails/02-20181103pgdayseminarv1-181112041352-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Pgday.Seoul 2018] PostgreSQL 성능을 위해 개발된 라이브러리 OS 소개 apposha](https://cdn.slidesharecdn.com/ss_thumbnails/06-pgdayseoul2018sangwook-181112042505-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2018] AWS Cloud 환경에서 PostgreSQL 구축하기](https://cdn.slidesharecdn.com/ss_thumbnails/03-pgday-flytothecloudkimdongsu-181112041825-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2018] replacing oracle with edb postgres](https://cdn.slidesharecdn.com/ss_thumbnails/01-replacingoraclewithedbpostgres20181023-181112040354-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2019] Advanced FDW](https://cdn.slidesharecdn.com/ss_thumbnails/tarantulav2-191218044914-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Pgday.Seoul 2018] PostgreSQL Authentication with FreeIPA](https://cdn.slidesharecdn.com/ss_thumbnails/05-20181103pgdayseoulpostgresqlauthenticationwithfreeipa-181112042327-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2019] AppOS 고성능 I/O 확장 모듈로 성능 10배 향상시키기](https://cdn.slidesharecdn.com/ss_thumbnails/appos-2019-191218045825-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2017] 5. 테드폴허브(올챙이) PostgreSQL 확장하기 - 조현종](https://cdn.slidesharecdn.com/ss_thumbnails/postgresql-171106044405-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2020] 포스트그레스큐엘 자국어화 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/postgresqli18nko-201117135339-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2017] 4. Composite Type/JSON 파라미터를 활용한 TVP구현(with C#, JAVA) - 지현명](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-171106042708-thumbnail.jpg?width=640&height=640&fit=bounds)