More Related Content

PDF
Javaはどのように動くのか~スライドでわかるJVMの仕組み 
PPTX
Kubernetesでの性能解析 ~なんとなく遅いからの脱却~(Kubernetes Meetup Tokyo #33 発表資料) 
PDF
Javaコードが速く実⾏される秘密 - JITコンパイラ⼊⾨(JJUG CCC 2020 Fall講演資料) 
PDF
ネットワーク ゲームにおけるTCPとUDPの使い分け 
PDF

PDF

PDF
アーキテクチャから理解するPostgreSQLのレプリケーション 
PPTX
What's hot

PDF
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp 
PDF
より速く より運用しやすく 進化し続けるJVM(Java Developers Summit Online 2023 発表資料) 
PPTX

PDF
オススメのJavaログ管理手法 ~コンテナ編~(Open Source Conference 2022 Online/Spring 発表資料) 
PDF

PDF
Garbage First Garbage Collection (G1 GC) #jjug_ccc #ccc_cd6 
PDF

PPTX
Java 18で入ったJVM関連の(やや細かめな)改善(JJUGナイトセミナー「Java 18 リリース記念イベント」発表資料) 
PPTX
CloudNativePGを動かしてみた! ~PostgreSQL on Kubernetes~(第34回PostgreSQLアンカンファレンス@オンライ... 
PPTX
GraalVMの多言語実行機能が凄そうだったので試しにApache Sparkに組み込んで動かしてみたけどちょっとまだ早かったかもしれない(Open So... 
PDF
PostgreSQLのリカバリ超入門(もしくはWAL、CHECKPOINT、オンラインバックアップの仕組み) 
PPTX
世界一わかりやすいClean Architecture 
PPTX
PostgreSQLのロール管理とその注意点(Open Source Conference 2022 Online/Osaka 発表資料) 
PDF
SQLアンチパターン 幻の第26章「とりあえず削除フラグ」 
PDF
そんなトランザクションマネージャで大丈夫か? 
PDF
さいきんの InnoDB Adaptive Flushing (仮) 
PDF

PPTX
トランザクションをSerializableにする4つの方法 
PDF
Inside vacuum - 第一回PostgreSQLプレ勉強会 
PDF
Viewers also liked

PDF
Spring Bootをはじめる時にやるべき10のこと 
PPTX
java.lang.OutOfMemoryError #渋谷java 
PDF
Java SE 9の紹介: モジュール・システムを中心に 
PPTX

PPTX
JEP280: Java 9 で文字列結合の処理が変わるぞ!準備はいいか!? #jjug_ccc 
PDF

PDF

PDF

PDF
JDK9 新機能 (日本語&ショートバージョン) #jjug 
PDF

PDF
渋谷JVM#1 Immutable時代のプログラミング言語 Clojure 
PDF

PDF

PPTX

PDF

PPTX

PDF
Similar to Java でつくる�低レイテンシ実装の技巧�

PPTX
Linux Performance Analysis in 15 minutes 
PDF

PDF
シンプルでシステマチックな Linux 性能分析方法 
PPTX
CPU / GPU高速化セミナー!性能モデルの理論と実践:理論編 
PPT
�Linux/DB Tuning (DevSumi2010, Japanese) 
PDF
第4回 配信講義 計算科学技術特論A (2021) 
PDF

PDF

PPTX

PDF

PDF

PDF
プロファイラGuiを用いたコード分析 20160610 
PPTX

PPTX

PDF

PDF
CMSI計算科学技術特論A(8) 高速化チューニングとその関連技術2 
PPT
遊休リソースを用いた�相同性検索処理の並列化とその評価 
PDF

PDF
20151112 kutech lecture_ishizaki_public 
PDF
perfを使ったpostgre sqlの解析(後編) Java でつくる�低レイテンシ実装の技巧�
- 1.
- 2.
- 3.
いちおう Oracle Contributor
•mysql-connector-java のバグ修正に貢献
• 詳しくは 2016年10月リリースの
5.1.40 の ChangeLog 参照
• Tシャツもらった!
• PostgreSQLのイベントに
行くときに着ようと思ってる
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
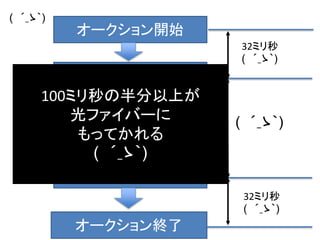
入札は JSON API
•ユーザID
• User-Agent
• サイトURL
• IPアドレス
• Referer
• etc…
• 入札額
• 表示したいタグ
• リンク先URL
• etc…
入札リクエスト
( HTTP Request )
入札レスポンス
(HTTP Response)
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
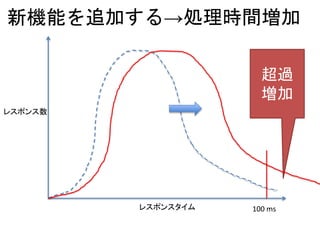
電気信号の速度 = 光速の6割
•2.4GHz の CPU = 1秒間に24億サイクル
• CPU の1サイクルは…
= 1 / (2.4 * 1000 * 1000 * 1000)
= 0.000000000416 秒
→0.416 ナノ秒
• 299279458(m/s) * 0.000000000416 * 0.6
= 0.0747 (m/サイクル)
→1サイクルにつき電気信号は 7.4cm しか
進めない
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
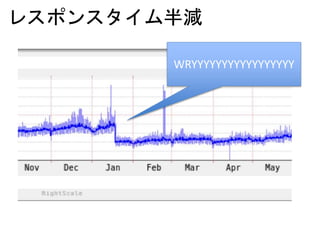
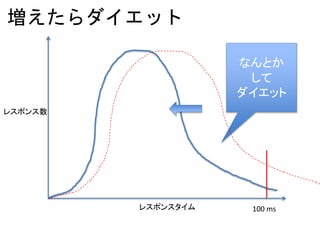
レイテンシ源 (1ms =1,000,000ns)
操作 レイテンシ
LAN 上サーバ間のパケット往復 150,000 ns〜
4KbytesをSSDから読む 150,000ns
HDD のシーク 10,000,000ns (10ms)
出典: https://gist.github.com/jboner/2841832
- 32.
ハードウェア的な制約
• HDD 遅い
=最新のものでも針が動くだけで約5ms
= 使えない
• SSD 遅い
= マイクロ秒単位 → アクセスは最小限に
• LAN 遅い
= 早くとも 100マイクロ秒単位 → 最小限に
- 33.
- 34.
レイテンシ源 (1ms =1,000,000ns)
操作 レイテンシ
L1 キャッシュ上のデータ参照 0.5ns
分岐予測ミス 5ns
L2 キャッシュ上のデータ参照 7ns
メインメモリ上のデータ参照 100ns
出典: https://gist.github.com/jboner/2841832
https://www.quora.com/Linux-Kernel-How-much-processor-time-does-a-process-switching-cost-to-the-process-scheduler
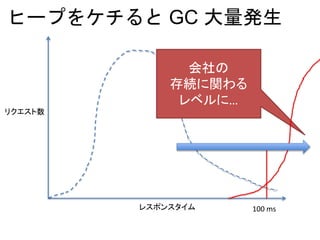
何千回・何万回・何十万回と発生するもの
↓
削減するには
低レベルを意識してコードを最適化する
- 35.
レイテンシ源 (1ms =1,000,000ns)
操作 レイテンシ
Full GC
(-Xmx16g –XX:UseParallelGC -XX:+UseParallelOldGC)
1,500ms〜
(1.5秒〜)
Full GC
(-Xmx24g -XX:+UseG1GC)
16,000ms〜
(16秒〜)
young GC Stop the world
(G1 GC)
80ms〜400ms
出典: 独自測定
- 36.
- 37.
- 38.
- 39.
- 40.
perf
• Linux 向けプロファイラ
•C, C++ で書いたプログラムの
プロファイリングに使う
• 本来 Java 向けのツールではない、が
どうしても使わねばならんのだ
• 実行例
perf record -F 99 -a -g -- sleep 30 && perf report
- 41.
# Overhead Command
#........ ............... .....................................................
#
91.61% java perf-22349.map
|
|--13.64%-- 0x7f855ae9857b
| 0xa06e0019b7d8
|
|--10.68%-- 0x7f855ae98497
| |
| |--99.78%-- 0xa06e0019b7d8
| --0.22%-- [...]
|
|--4.24%-- 0x7f855ae98380
| 0xa06e0019b7d8
|
|--4.13%-- 0x7f855ae985f7
| 0xa06e0019b7d8
|
|--4.11%-- 0x7f855ae98617
| 0xa06e0019b7d8
|
|--2.11%-- 0x7f855ae984bf
| |
| |--99.36%-- 0xa06e0019b7d8
| --0.64%-- [...]
|
|--1.49%-- 0x7f855ae985dd
実行結果 (※壊れてます)
- 42.
JVM による最適化の問題点(1)
• HotspotVM の生成した機械語では frame
pointer が使われない (使う必要が無い)
(frame pointer 用のレジスタ (x86_64 なら rbp
レジスタ) を汎用レジスタとして使う)
• 要するに、メソッドの呼び出し元のメソッド
が判らなくなる
• JVM 起動時に
-XX:+PreserveFramePointer
オプションを付ける
- 43.
- 44.
- 45.
# Overhead Command
#........ ............... ...............................
12.77% java perf-106368.map
[.] Ljp/so_netmedia/rtb/buyer/domain/buyer/XXXXXXXXXXXXXX;.select
|
--- Ljp/so_netmedia/rtb/buyer/domain/buyer/XXXXXXXXXXXXXXX;.select
Ljp/so_netmedia/rtb/buyer/domain/buyer/XXXXXXXXXXXXXXX;.decide
Ljp/so_netmedia/rtb/buyer/application/XXXXXXXXXXXXXXX;.process
Ljp/so_netmedia/rtb/buyer/application/XXXXXXXXXXXXXXX;.execute
Ljp/so_netmedia/rtb/buyer/application/XXXXXXXXXXXXXXX;.channelRead0
Ljp/so_netmedia/rtb/buyer/application/XXXXXXXXXXXXXXX;.channelRead0
Lio/netty/channel/SimpleChannelInboundHandler;.channelRead
Lio/netty/channel/AbstractChannelHandlerContext;.invokeChannelRead
Lio/netty/channel/AbstractChannelHandlerContext;.fireChannelRead
Lio/netty/channel/ChannelInboundHandlerAdapter;.channelRead
Ljp/so_netmedia/rtb/buyer/application/RequestRecordingHandler;.channelRead
Lio/netty/channel/AbstractChannelHandlerContext;.invokeChannelRead
Lio/netty/channel/AbstractChannelHandlerContext;.fireChannelRead
Lio/netty/handler/codec/MessageToMessageDecoder;.channelRead
Lio/netty/channel/AbstractChannelHandlerContext;.invokeChannelRead
Lio/netty/channel/AbstractChannelHandlerContext;.fireChannelRead
Lio/netty/handler/codec/ByteToMessageDecoder;.channelRead
Lio/netty/channel/AbstractChannelHandlerContext;.invokeChannelRead
Lio/netty/channel/AbstractChannelHandlerContext;.fireChannelRead
Lio/netty/handler/timeout/ReadTimeoutHandler;.channelRead
Lio/netty/channel/AbstractChannelHandlerContext;.invokeChannelRead
Lio/netty/channel/AbstractChannelHandlerContext;.fireChannelRead
Lio/netty/channel/ChannelInboundHandlerAdapter;.channelRead
Ljp/so_netmedia/rtb/buyer/application/BuyerServerLoggingHandler;.channelRead
Lio/netty/channel/AbstractChannelHandlerContext;.invokeChannelRead
Lio/netty/channel/AbstractChannelHandlerContext;.fireChannelRead
Lio/netty/channel/DefaultChannelPipeline;.fireChannelRead
これが 25,000行ほど続く
- 46.
flame graph
• Netflixの Brendan Gregg さんが作った
perf の結果をグラフ化してくれる
優れもの
• 詳しくは… http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html
- 50.
- 51.
- 52.
- 53.
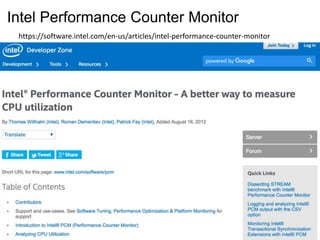
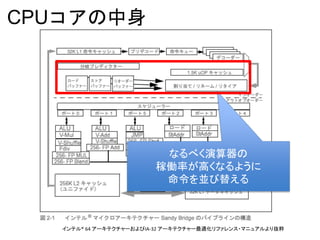
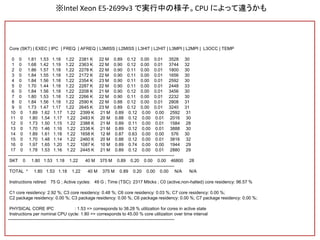
Core (SKT) |EXEC | IPC | FREQ | AFREQ | L3MISS | L2MISS | L3HIT | L2HIT | L3MPI | L2MPI | L3OCC | TEMP
0 0 1.81 1.53 1.18 1.22 2381 K 22 M 0.89 0.12 0.00 0.01 3528 30
1 0 1.68 1.42 1.19 1.22 2363 K 22 M 0.90 0.12 0.00 0.01 3744 32
2 0 1.86 1.57 1.18 1.22 2278 K 22 M 0.90 0.11 0.00 0.01 1800 30
3 0 1.84 1.55 1.18 1.22 2172 K 22 M 0.90 0.11 0.00 0.01 1656 30
4 0 1.84 1.56 1.18 1.22 2354 K 23 M 0.90 0.11 0.00 0.01 2592 30
5 0 1.70 1.44 1.18 1.22 2287 K 22 M 0.90 0.11 0.00 0.01 2448 33
6 0 1.84 1.56 1.18 1.22 2208 K 21 M 0.90 0.12 0.00 0.01 3456 30
7 0 1.80 1.53 1.18 1.22 2266 K 22 M 0.90 0.11 0.00 0.01 2232 30
8 0 1.84 1.56 1.18 1.22 2590 K 22 M 0.88 0.12 0.00 0.01 2808 31
9 0 1.73 1.47 1.17 1.22 2645 K 23 M 0.89 0.12 0.00 0.01 3240 31
10 0 1.89 1.62 1.17 1.22 2399 K 21 M 0.89 0.12 0.00 0.00 2592 31
11 0 1.80 1.54 1.17 1.22 2483 K 20 M 0.88 0.12 0.00 0.01 2016 30
12 0 1.73 1.50 1.15 1.22 2388 K 21 M 0.89 0.11 0.00 0.01 1584 28
13 0 1.70 1.46 1.16 1.22 2338 K 21 M 0.89 0.12 0.00 0.01 3888 30
14 0 1.89 1.61 1.18 1.22 1658 K 12 M 0.87 0.63 0.00 0.00 576 30
15 0 1.70 1.48 1.14 1.22 2460 K 20 M 0.88 0.12 0.00 0.01 3816 32
16 0 1.97 1.65 1.20 1.22 1087 K 10 M 0.89 0.74 0.00 0.00 1944 29
17 0 1.78 1.53 1.16 1.22 2445 K 21 M 0.89 0.12 0.00 0.01 2880 29
---------------------------------------------------------------------------------------------------------------
SKT 0 1.80 1.53 1.18 1.22 40 M 375 M 0.89 0.20 0.00 0.00 46800 28
---------------------------------------------------------------------------------------------------------------
TOTAL * 1.80 1.53 1.18 1.22 40 M 375 M 0.89 0.20 0.00 0.00 N/A N/A
Instructions retired: 75 G ; Active cycles: 49 G ; Time (TSC): 2317 Mticks ; C0 (active,non-halted) core residency: 96.57 %
C1 core residency: 2.92 %; C3 core residency: 0.48 %; C6 core residency: 0.03 %; C7 core residency: 0.00 %;
C2 package residency: 0.00 %; C3 package residency: 0.00 %; C6 package residency: 0.00 %; C7 package residency: 0.00 %;
PHYSICAL CORE IPC : 1.53 => corresponds to 38.28 % utilization for cores in active state
Instructions per nominal CPU cycle: 1.80 => corresponds to 45.00 % core utilization over time interval
---------------------------------------------------------------------------------------------------------------
※Intel Xeon E5-2699v3 で実行中の様子。CPU によって違うかも
- 54.
Core (SKT) |EXEC | IPC | FREQ | AFREQ | L3MISS | L2MISS | L3HIT | L2HIT | L3MPI | L2MPI | L3OCC | TEMP
0 0 1.81 1.53 1.18 1.22 2381 K 22 M 0.89 0.12 0.00 0.01 3528 30
1 0 1.68 1.42 1.19 1.22 2363 K 22 M 0.90 0.12 0.00 0.01 3744 32
2 0 1.86 1.57 1.18 1.22 2278 K 22 M 0.90 0.11 0.00 0.01 1800 30
3 0 1.84 1.55 1.18 1.22 2172 K 22 M 0.90 0.11 0.00 0.01 1656 30
4 0 1.84 1.56 1.18 1.22 2354 K 23 M 0.90 0.11 0.00 0.01 2592 30
5 0 1.70 1.44 1.18 1.22 2287 K 22 M 0.90 0.11 0.00 0.01 2448 33
6 0 1.84 1.56 1.18 1.22 2208 K 21 M 0.90 0.12 0.00 0.01 3456 30
7 0 1.80 1.53 1.18 1.22 2266 K 22 M 0.90 0.11 0.00 0.01 2232 30
8 0 1.84 1.56 1.18 1.22 2590 K 22 M 0.88 0.12 0.00 0.01 2808 31
9 0 1.73 1.47 1.17 1.22 2645 K 23 M 0.89 0.12 0.00 0.01 3240 31
10 0 1.89 1.62 1.17 1.22 2399 K 21 M 0.89 0.12 0.00 0.00 2592 31
11 0 1.80 1.54 1.17 1.22 2483 K 20 M 0.88 0.12 0.00 0.01 2016 30
12 0 1.73 1.50 1.15 1.22 2388 K 21 M 0.89 0.11 0.00 0.01 1584 28
13 0 1.70 1.46 1.16 1.22 2338 K 21 M 0.89 0.12 0.00 0.01 3888 30
14 0 1.89 1.61 1.18 1.22 1658 K 12 M 0.87 0.63 0.00 0.00 576 30
15 0 1.70 1.48 1.14 1.22 2460 K 20 M 0.88 0.12 0.00 0.01 3816 32
16 0 1.97 1.65 1.20 1.22 1087 K 10 M 0.89 0.74 0.00 0.00 1944 29
17 0 1.78 1.53 1.16 1.22 2445 K 21 M 0.89 0.12 0.00 0.01 2880 29
---------------------------------------------------------------------------------------------------------------
SKT 0 1.80 1.53 1.18 1.22 40 M 375 M 0.89 0.20 0.00 0.00 46800 28
---------------------------------------------------------------------------------------------------------------
TOTAL * 1.80 1.53 1.18 1.22 40 M 375 M 0.89 0.20 0.00 0.00 N/A N/A
Instructions retired: 75 G ; Active cycles: 49 G ; Time (TSC): 2317 Mticks ; C0 (active,non-halted) core residency: 96.57 %
C1 core residency: 2.92 %; C3 core residency: 0.48 %; C6 core residency: 0.03 %; C7 core residency: 0.00 %;
C2 package residency: 0.00 %; C3 package residency: 0.00 %; C6 package residency: 0.00 %; C7 package residency: 0.00 %;
PHYSICAL CORE IPC : 1.53 => corresponds to 38.28 % utilization for cores in active state
Instructions per nominal CPU cycle: 1.80 => corresponds to 45.00 % core utilization over time interval
---------------------------------------------------------------------------------------------------------------
※Intel Xeon E5-2699v3 で実行中の様子。CPU によって違うかも
意味わからないと思うので解説
- 55.
- 56.
- 57.
- 58.
- 59.
メモリはすごく遅い
• 足し算1回…0.5サイクル
• L1キャッシュ ... 5サイクル
• L2 キャッシュ … 12サイクル
• L3 キャッシュ… 42サイクル
• メインメモリ…もっと
• メモリアクセスが多いと計算ユニットが
空回りする
= CPU使用率100%でも CPU の中身は
ほとんど遊んでたりする
(Intel Skylake アーキテクチャの場合)
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
Core (SKT) |EXEC | IPC | FREQ | AFREQ | L3MISS | L2MISS | L3HIT | L2HIT | L3MPI | L2MPI | L3OCC | TEMP
0 0 1.81 1.53 1.18 1.22 2381 K 22 M 0.89 0.12 0.00 0.01 3528 30
1 0 1.68 1.42 1.19 1.22 2363 K 22 M 0.90 0.12 0.00 0.01 3744 32
2 0 1.86 1.57 1.18 1.22 2278 K 22 M 0.90 0.11 0.00 0.01 1800 30
3 0 1.84 1.55 1.18 1.22 2172 K 22 M 0.90 0.11 0.00 0.01 1656 30
4 0 1.84 1.56 1.18 1.22 2354 K 23 M 0.90 0.11 0.00 0.01 2592 30
5 0 1.70 1.44 1.18 1.22 2287 K 22 M 0.90 0.11 0.00 0.01 2448 33
6 0 1.84 1.56 1.18 1.22 2208 K 21 M 0.90 0.12 0.00 0.01 3456 30
7 0 1.80 1.53 1.18 1.22 2266 K 22 M 0.90 0.11 0.00 0.01 2232 30
8 0 1.84 1.56 1.18 1.22 2590 K 22 M 0.88 0.12 0.00 0.01 2808 31
9 0 1.73 1.47 1.17 1.22 2645 K 23 M 0.89 0.12 0.00 0.01 3240 31
10 0 1.89 1.62 1.17 1.22 2399 K 21 M 0.89 0.12 0.00 0.00 2592 31
11 0 1.80 1.54 1.17 1.22 2483 K 20 M 0.88 0.12 0.00 0.01 2016 30
12 0 1.73 1.50 1.15 1.22 2388 K 21 M 0.89 0.11 0.00 0.01 1584 28
13 0 1.70 1.46 1.16 1.22 2338 K 21 M 0.89 0.12 0.00 0.01 3888 30
14 0 1.89 1.61 1.18 1.22 1658 K 12 M 0.87 0.63 0.00 0.00 576 30
15 0 1.70 1.48 1.14 1.22 2460 K 20 M 0.88 0.12 0.00 0.01 3816 32
16 0 1.97 1.65 1.20 1.22 1087 K 10 M 0.89 0.74 0.00 0.00 1944 29
17 0 1.78 1.53 1.16 1.22 2445 K 21 M 0.89 0.12 0.00 0.01 2880 29
---------------------------------------------------------------------------------------------------------------
SKT 0 1.80 1.53 1.18 1.22 40 M 375 M 0.89 0.20 0.00 0.00 46800 28
---------------------------------------------------------------------------------------------------------------
TOTAL * 1.80 1.53 1.18 1.22 40 M 375 M 0.89 0.20 0.00 0.00 N/A N/A
Instructions retired: 75 G ; Active cycles: 49 G ; Time (TSC): 2317 Mticks ; C0 (active,non-halted) core residency: 96.57 %
C1 core residency: 2.92 %; C3 core residency: 0.48 %; C6 core residency: 0.03 %; C7 core residency: 0.00 %;
C2 package residency: 0.00 %; C3 package residency: 0.00 %; C6 package residency: 0.00 %; C7 package residency: 0.00 %;
PHYSICAL CORE IPC : 1.53 => corresponds to 38.28 % utilization for cores in active state
Instructions per nominal CPU cycle: 1.80 => corresponds to 45.00 % core utilization over time interval
---------------------------------------------------------------------------------------------------------------
※Intel Xeon E5-2699v3 で実行中の様子。CPU によって違うかも
- 67.
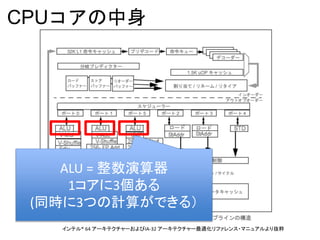
読み方
• IPC
– instructionper cycle
– 命令を1サイクルで何個できたか
– (CPUによって違うけど) 2 超えたらすごいと思う
– 1を割っている場合は…
= 演算ユニットがメモリアクセス待ちで
待っている
= (理論上) もっと改善できる
• L3hit … L3 キャッシュヒット率
• L2hit … L2 キャッシュヒット率
- 68.
- 69.
# ........ ............................................... .....
#
5.28% java perf-106368.map [.] Ljava/util/Arrays;.binarySearch0
|
--- Ljava/util/Arrays;.binarySearch0
|
|--96.20%-- Ljava/util/Arrays;.binarySearch
| Ljp/so_netmedia/rtb/kvs/domain/user/XXXXXXXXXXXXXXX;.XXXXXXXXXXXXXXX
| Ljp/so_netmedia/rtb/kvs/domain/user/XXXXXXXXXXXXXXX;.XXXXXXXXXXXXXXX
| Ljp/so_netmedia/rtb/kvs/domain/user/XXXXXXXXXXXXXXX;.XXXXXXXXXXXXXXX
| Ljp/so_netmedia/rtb/kvs/domain/user/XXXXXXXXXXXXXXX;.XXXXXXXXXXXXXXX
| Ljp/so_netmedia/rtb/buyer/domain/buyer/XXXXXXXXXXXXXXX;.isCalculated
| Ljp/so_netmedia/rtb/buyer/domain/buyer/XXXXXXXXXXXXXXX;.match
| Ljp/so_netmedia/rtb/buyer/domain/buyer/XXXXXXXXXXXXXXX;.select
| Ljp/so_netmedia/rtb/buyer/domain/buyer/XXXXXXXXXXXXXXX;.decide
| Ljp/so_netmedia/rtb/buyer/application/XXXXXXXXXXXXXXX;.process
| Ljp/so_netmedia/rtb/buyer/application/XXXXXXXXXXXXXXX;.execute
| Ljp/so_netmedia/rtb/buyer/application/XXXXXXXXXXXXXXX;.channelRead0
| Ljp/so_netmedia/rtb/buyer/application/XXXXXXXXXXXXXXX;.channelRead0
| Lio/netty/channel/SimpleChannelInboundHandler;.channelRead
| Lio/netty/channel/AbstractChannelHandlerContext;.invokeChannelRead
| Lio/netty/channel/AbstractChannelHandlerContext;.fireChannelRead
| Lio/netty/channel/ChannelInboundHandlerAdapter;.channelRead
| Ljp/so_netmedia/rtb/buyer/application/RequestRecordingHandler;.channelRead
| Lio/netty/channel/AbstractChannelHandlerContext;.invokeChannelRead
java.util.Arrays.binarySearch は L2キャッシュミス発生源
アルゴリズム的に仕方無い
- 70.
12.40% java perf-106368.map[.] Ljava/util/HashMap;.getNode
|
--- Ljava/util/HashMap;.getNode
|
|--35.09%-- Ljava/util/LinkedHashMap;.get
| |
| |--62.05%-- Ljp/so_netmedia/rtb/......
| | |
| | |--89.88%-- Ljp/so_netmedia/rtb/buyer/domain/....
| | | Ljp/so_netmedia/rtb/buyer/domain/.....
| | | Ljp/so_netmedia/rtb/buyer/domain/
| | | Ljp/so_netmedia/rtb/buyer/domain/
| | | Ljp/so_netmedia/rtb/buyer/domain/
| | | Ljp/so_netmedia/rtb/buyer/application
| | | Ljp/so_netmedia/rtb/buyer/application/
| | | Ljp/so_netmedia/rtb/buyer/application
| | | Ljp/so_netmedia/rtb/buyer/application
| | | Lio/netty/channel/.....
| | | Lio/netty/channel/......
| | | Lio/netty/channel
java.util.HashMap.get は L2キャッシュミス発生源
データの持ち方を変えることで改善できる(かも)
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
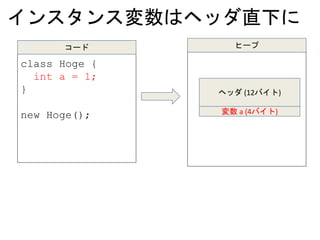
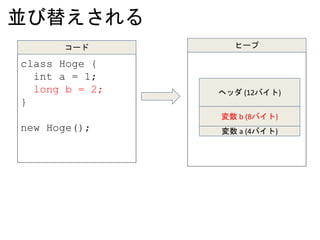
配列
new int[] {1, 2, 3 };
コード ヒープ
ヘッダ (12バイト)
数値 “1” (4バイト)
数値 “2” (4バイト)
数値 “3” (4バイト)
配列の長さ “3” (4バイト)
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
HashSet → ArrayListへ置換
してみた
• HashSet
– 中身は HashMap
– add, get, remove, contains, size の
実行時間が O(1)
• ArrayList
– 中身は配列
– get, remove, contains, size の実行時間が O(N)
O(1) < O(N) のはずなんだが…
- 85.
- 86.
もっとやりたい人
• HotSpot VMが生み出した機械語を
逆アセンブルして見てみましょう。
詳しい使い方はおググりください
-XX:+PrintAssembly
:
0x000000010d528f80: mov %eax,-0x14000(%rsp)
0x000000010d528f87: push %rbp
0x000000010d528f88: sub $0x30,%rsp
0x000000010d528f8c: movabs $0x12166e950,%rax
0x000000010d528f96: mov 0x8(%rax),%edi
0x000000010d528f99: add $0x8,%edi
0x000000010d528f9c: mov %edi,0x8(%rax)
0x000000010d528f9f: movabs $0x12166e460,%rax ; {metadata({method}
{0x000000012166e460} 'disjoint' '([I[I)Z' in '.......
- 87.
ここまで来れば
• 逆アセンブル結果を見て Javaのソースを
書き換えることで高速化できる
• ループアンローリング等、C/C++ でしか
有効でないと思われていたテクニックも
Java で使える
• インラインアセンブラを使えない点を除けば
ほとんど C/C++ と同レベルの最適化が
できる
• ただし GC だけはどうしようもない
- 88.
- 89.
- 90.
G1 GC しかない
•G1 GC は非常に優秀
• G1 GC については JJUG CCC 2015 Fall の
KUBOTA Yuji さんの発表を参照
http://www.slideshare.net/YujiKubota/garbage-
first-garbage-collection
• 大量にヒープとCPUコアを割り当てれば
Full GC が滅多に起きない
- 91.
GC による Stopthe world
• -XX:+UseParallelGC → 0.3%
-XX:+UseG1GC → 0.1%
• もはや G1 GC でいいんじゃないか
• 弊社の主戦力は G1 GC 、ヒープ30GBytes
- 92.
ヒープ 30GBytes の世界
•ヒープダンプ取れない
(取るのに10時間以上かかる…)
• 取れても VisualVM で開けない
(大量のメモリを積んだマシンでないと…)
• 開けても解析できない
(OQL 1つ走らせるのに2時間以上…)
ヒーププロファイリング困難
- 93.
恐怖の GCLocker InitiatedGC
• JNI API の
GetPrimitiveArrayCritical
GetStringCritical
を呼ぶと GC の実行が保留される
→そのまま放置すると OutOfMemoryError
• ReleasePrimitiveArrayCritical
ReleaseStringCritical
を呼ぶと GC が再開する
→GC 保留中にたまったガベージを
一気に回収する = 時間がかかることがある
- 94.
使ってはいけない Java SEAPI
java.io.ObjectInputStream#bytesToFloats, bytesToDoubles
java.io.ObjectOutputStream#floatsToBytes, doublesToBytes
java.nio.Bits#copyFromShortArray, copyToShortArray
java.nio.Bits#copyFromIntArray, copyToIntArray
java.nio.Bits#copyFromLongArray, copyToLongArray
java.util.zip.Adler32#updateBytes
java.util.zip.CRC32#updateBytes
java.util.zip.Deflater#setDictionary, deflateBytes
java.util.zip.Inflater#setDictionary, inflateBytes
java.lang.ClassLoader$NativeLibrary.load, unload
java.lang.ClassLoader#findBuiltinLib
java.util.TimeZone#getSystemTimeZoneID
java.util.zip.ZipFile#open
GCLocker Initiated GC を発生させるので、使わない!
- 95.
GClocker Initiated GC対策
• GC ログを見て、
GClocker Initated GC を見たら直ちに
「使ってはいけないAPI」を使っている
箇所を特定し、駆逐して差し上げる
• ライブラリの中でも使っていたりする
• デバッガを使って「使ってはいけない API」
を使っている箇所を燻り出す
- 96.
モニタリング
• GC ログを監視
–GCはさだめ
– さだめは死
– 己のさだめをうけとめよ
• HTTPレスポンスのパーセンタイル値を
監視
– 99.9、99、98、95、75、50パーセンタイル値
- 97.
弊社の現状
• 平均 約5 ms でレスポンスを返しています
• 99.5% のリクエストは 100 ミリ秒以内に
返しています
• 今後もがんばります。Java で戦い続けます
• 他にも色々テクニックがありますが
またの機会に





























![# Overhead Command
# ........ ............... .....................................................
#
91.61% java perf-22349.map
|
|--13.64%-- 0x7f855ae9857b
| 0xa06e0019b7d8
|
|--10.68%-- 0x7f855ae98497
| |
| |--99.78%-- 0xa06e0019b7d8
| --0.22%-- [...]
|
|--4.24%-- 0x7f855ae98380
| 0xa06e0019b7d8
|
|--4.13%-- 0x7f855ae985f7
| 0xa06e0019b7d8
|
|--4.11%-- 0x7f855ae98617
| 0xa06e0019b7d8
|
|--2.11%-- 0x7f855ae984bf
| |
| |--99.36%-- 0xa06e0019b7d8
| --0.64%-- [...]
|
|--1.49%-- 0x7f855ae985dd
実行結果 (※壊れてます)](https://image.slidesharecdn.com/jjugccc2016fallm3-161221061554/85/Java-41-320.jpg)



![# Overhead Command
# ........ ............... ...............................
12.77% java perf-106368.map
[.] Ljp/so_netmedia/rtb/buyer/domain/buyer/XXXXXXXXXXXXXX;.select
|
--- Ljp/so_netmedia/rtb/buyer/domain/buyer/XXXXXXXXXXXXXXX;.select
Ljp/so_netmedia/rtb/buyer/domain/buyer/XXXXXXXXXXXXXXX;.decide
Ljp/so_netmedia/rtb/buyer/application/XXXXXXXXXXXXXXX;.process
Ljp/so_netmedia/rtb/buyer/application/XXXXXXXXXXXXXXX;.execute
Ljp/so_netmedia/rtb/buyer/application/XXXXXXXXXXXXXXX;.channelRead0
Ljp/so_netmedia/rtb/buyer/application/XXXXXXXXXXXXXXX;.channelRead0
Lio/netty/channel/SimpleChannelInboundHandler;.channelRead
Lio/netty/channel/AbstractChannelHandlerContext;.invokeChannelRead
Lio/netty/channel/AbstractChannelHandlerContext;.fireChannelRead
Lio/netty/channel/ChannelInboundHandlerAdapter;.channelRead
Ljp/so_netmedia/rtb/buyer/application/RequestRecordingHandler;.channelRead
Lio/netty/channel/AbstractChannelHandlerContext;.invokeChannelRead
Lio/netty/channel/AbstractChannelHandlerContext;.fireChannelRead
Lio/netty/handler/codec/MessageToMessageDecoder;.channelRead
Lio/netty/channel/AbstractChannelHandlerContext;.invokeChannelRead
Lio/netty/channel/AbstractChannelHandlerContext;.fireChannelRead
Lio/netty/handler/codec/ByteToMessageDecoder;.channelRead
Lio/netty/channel/AbstractChannelHandlerContext;.invokeChannelRead
Lio/netty/channel/AbstractChannelHandlerContext;.fireChannelRead
Lio/netty/handler/timeout/ReadTimeoutHandler;.channelRead
Lio/netty/channel/AbstractChannelHandlerContext;.invokeChannelRead
Lio/netty/channel/AbstractChannelHandlerContext;.fireChannelRead
Lio/netty/channel/ChannelInboundHandlerAdapter;.channelRead
Ljp/so_netmedia/rtb/buyer/application/BuyerServerLoggingHandler;.channelRead
Lio/netty/channel/AbstractChannelHandlerContext;.invokeChannelRead
Lio/netty/channel/AbstractChannelHandlerContext;.fireChannelRead
Lio/netty/channel/DefaultChannelPipeline;.fireChannelRead
これが 25,000行ほど続く](https://image.slidesharecdn.com/jjugccc2016fallm3-161221061554/85/Java-45-320.jpg)













![# ........ ............... ................................ .....
#
5.28% java perf-106368.map [.] Ljava/util/Arrays;.binarySearch0
|
--- Ljava/util/Arrays;.binarySearch0
|
|--96.20%-- Ljava/util/Arrays;.binarySearch
| Ljp/so_netmedia/rtb/kvs/domain/user/XXXXXXXXXXXXXXX;.XXXXXXXXXXXXXXX
| Ljp/so_netmedia/rtb/kvs/domain/user/XXXXXXXXXXXXXXX;.XXXXXXXXXXXXXXX
| Ljp/so_netmedia/rtb/kvs/domain/user/XXXXXXXXXXXXXXX;.XXXXXXXXXXXXXXX
| Ljp/so_netmedia/rtb/kvs/domain/user/XXXXXXXXXXXXXXX;.XXXXXXXXXXXXXXX
| Ljp/so_netmedia/rtb/buyer/domain/buyer/XXXXXXXXXXXXXXX;.isCalculated
| Ljp/so_netmedia/rtb/buyer/domain/buyer/XXXXXXXXXXXXXXX;.match
| Ljp/so_netmedia/rtb/buyer/domain/buyer/XXXXXXXXXXXXXXX;.select
| Ljp/so_netmedia/rtb/buyer/domain/buyer/XXXXXXXXXXXXXXX;.decide
| Ljp/so_netmedia/rtb/buyer/application/XXXXXXXXXXXXXXX;.process
| Ljp/so_netmedia/rtb/buyer/application/XXXXXXXXXXXXXXX;.execute
| Ljp/so_netmedia/rtb/buyer/application/XXXXXXXXXXXXXXX;.channelRead0
| Ljp/so_netmedia/rtb/buyer/application/XXXXXXXXXXXXXXX;.channelRead0
| Lio/netty/channel/SimpleChannelInboundHandler;.channelRead
| Lio/netty/channel/AbstractChannelHandlerContext;.invokeChannelRead
| Lio/netty/channel/AbstractChannelHandlerContext;.fireChannelRead
| Lio/netty/channel/ChannelInboundHandlerAdapter;.channelRead
| Ljp/so_netmedia/rtb/buyer/application/RequestRecordingHandler;.channelRead
| Lio/netty/channel/AbstractChannelHandlerContext;.invokeChannelRead
java.util.Arrays.binarySearch は L2キャッシュミス発生源
アルゴリズム的に仕方無い](https://image.slidesharecdn.com/jjugccc2016fallm3-161221061554/85/Java-69-320.jpg)
![12.40% java perf-106368.map [.] Ljava/util/HashMap;.getNode
|
--- Ljava/util/HashMap;.getNode
|
|--35.09%-- Ljava/util/LinkedHashMap;.get
| |
| |--62.05%-- Ljp/so_netmedia/rtb/......
| | |
| | |--89.88%-- Ljp/so_netmedia/rtb/buyer/domain/....
| | | Ljp/so_netmedia/rtb/buyer/domain/.....
| | | Ljp/so_netmedia/rtb/buyer/domain/
| | | Ljp/so_netmedia/rtb/buyer/domain/
| | | Ljp/so_netmedia/rtb/buyer/domain/
| | | Ljp/so_netmedia/rtb/buyer/application
| | | Ljp/so_netmedia/rtb/buyer/application/
| | | Ljp/so_netmedia/rtb/buyer/application
| | | Ljp/so_netmedia/rtb/buyer/application
| | | Lio/netty/channel/.....
| | | Lio/netty/channel/......
| | | Lio/netty/channel
java.util.HashMap.get は L2キャッシュミス発生源
データの持ち方を変えることで改善できる(かも)](https://image.slidesharecdn.com/jjugccc2016fallm3-161221061554/85/Java-70-320.jpg)


![配列
new int[] { 1, 2, 3 };
コード ヒープ
ヘッダ (12バイト)
数値 “1” (4バイト)
数値 “2” (4バイト)
数値 “3” (4バイト)
配列の長さ “3” (4バイト)](https://image.slidesharecdn.com/jjugccc2016fallm3-161221061554/85/Java-78-320.jpg)


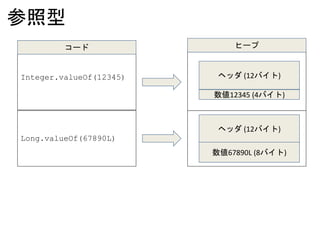
![HashMap<String, Integer> m
HashMap$Node[16]
"Apple"
3
"Orange" "Banana"
102
HashMap$NodeHashMap$NodeHashMap$Node
key valuekey value key value
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15](https://image.slidesharecdn.com/jjugccc2016fallm3-161221061554/85/Java-81-320.jpg)

![ObjectIntHashMap<String> m
Object[8] keys
"Apple"
"Orange"
"Banana"
int[8] values
0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7
1003 0 0 2 0 0
全体のサイズが小さくなる。キャッシュにも乗りやすい](https://image.slidesharecdn.com/jjugccc2016fallm3-161221061554/85/Java-83-320.jpg)