Downloaded 11 times








![9
[note: this talk will be slightly more entertaining if you’re a science fiction fan…
…otherwise it will merely be somewhat informative.]](https://image.slidesharecdn.com/osedefcorelongtalk2017-170207044211/75/InteropWG-Intro-Vertical-Programs-May-2017-9-2048.jpg)



















































![62
Thank you.
[with apologies to fine the folks at the BBC’s “Doctor Who”]
(please don’t have me arrested)](https://image.slidesharecdn.com/osedefcorelongtalk2017-170207044211/75/InteropWG-Intro-Vertical-Programs-May-2017-62-2048.jpg)

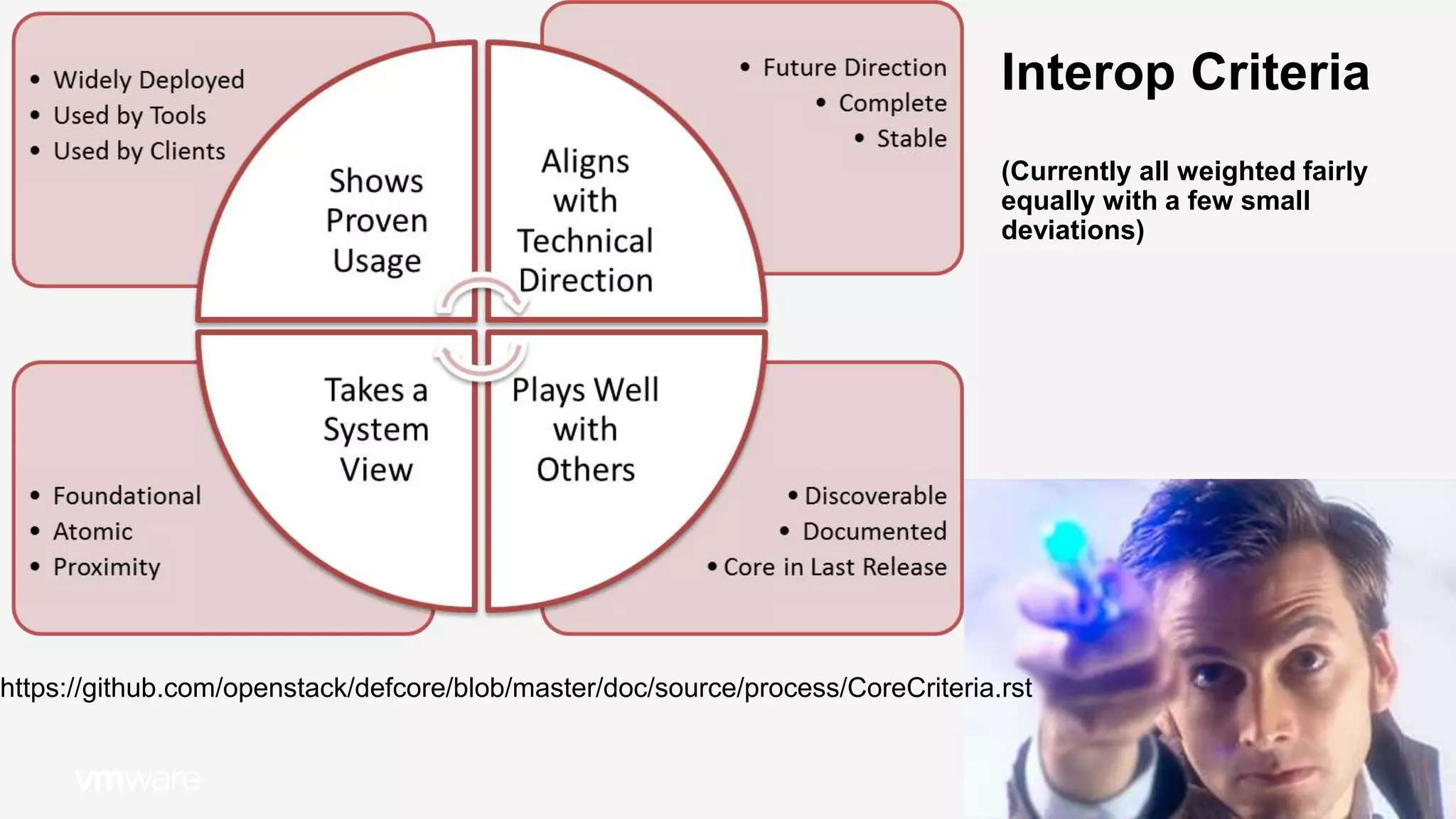
The document summarizes the OpenStack Interoperability Working Group's efforts to promote interoperability across OpenStack distributions and products. It discusses how the group develops guidelines specifying required capabilities and tests. Products must pass these tests to be considered interoperable and qualify for the OpenStack logo program. The guidelines aim to ensure a consistent user experience while allowing flexibility in implementations. The document also outlines the group's governance process and opportunities for participants to provide feedback to help improve interoperability standards over time.





















































![[OpenStack Day in Korea 2015] Keynote 1 - OpenStack Mission Update](https://cdn.slidesharecdn.com/ss_thumbnails/01-150213032657-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)









![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













