Recommended
PDF
PPTX
東京大学2020年度深層学習(Deep learning基礎講座) 第9回「深層学習と自然言語処理」
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
PDF
Cache-Oblivious データ構造入門 @DSIRNLP#5
PDF
Optuna Dashboardの紹介と設計解説 - 2022/12/10 Optuna Meetup #2
PDF
乱択データ構造の最新事情 -MinHash と HyperLogLog の最近の進歩-
PDF
PPTX
近年のHierarchical Vision Transformer
PDF
Chainer で Tensor コア (fp16) を使いこなす
PDF
Automatic Mixed Precision の紹介
PDF
論文紹介 "DARTS: Differentiable Architecture Search"
PDF
PDF
PDF
PDF
プログラミングコンテストでのデータ構造 2 ~平衡二分探索木編~
PDF
トピックモデルの評価指標 Perplexity とは何なのか?
PPTX
Humpback whale identification challenge反省会
PDF
SSII2019OS: 深層学習にかかる時間を短くしてみませんか? ~分散学習の勧め~
PDF
PDF
【DL輪読会】"Masked Siamese Networks for Label-Efficient Learning"
PDF
PDF
PPTX
PDF
PDF
PDF
PDF
Layer Normalization@NIPS+読み会・関西
PPTX
PPT
CA Japan seminar CA Easytrieve updates 2012/6/5
DOCX
More Related Content
PDF
PPTX
東京大学2020年度深層学習(Deep learning基礎講座) 第9回「深層学習と自然言語処理」
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
PDF
Cache-Oblivious データ構造入門 @DSIRNLP#5
PDF
Optuna Dashboardの紹介と設計解説 - 2022/12/10 Optuna Meetup #2
PDF
乱択データ構造の最新事情 -MinHash と HyperLogLog の最近の進歩-
PDF
PPTX
近年のHierarchical Vision Transformer
What's hot
PDF
Chainer で Tensor コア (fp16) を使いこなす
PDF
Automatic Mixed Precision の紹介
PDF
論文紹介 "DARTS: Differentiable Architecture Search"
PDF
PDF
PDF
PDF
プログラミングコンテストでのデータ構造 2 ~平衡二分探索木編~
PDF
トピックモデルの評価指標 Perplexity とは何なのか?
PPTX
Humpback whale identification challenge反省会
PDF
SSII2019OS: 深層学習にかかる時間を短くしてみませんか? ~分散学習の勧め~
PDF
PDF
【DL輪読会】"Masked Siamese Networks for Label-Efficient Learning"
PDF
PDF
PPTX
PDF
PDF
PDF
PDF
Layer Normalization@NIPS+読み会・関西
PPTX
Similar to FM-indexによる全文検索
PPT
CA Japan seminar CA Easytrieve updates 2012/6/5
DOCX
PDF
DSIRNLP#3 LT: 辞書挟み込み型転置インデクスFIg4.5
PDF
PDF
PDF
20160929_InnoDBの全文検索を使ってみた by 株式会社インサイトテクノロジー 中村範夫
PDF
PDF
PDF
PDF
PPTX
PPTX
ファントム異常を排除する高速なトランザクション処理向けインデックス
More from Sho IIZUKA
PDF
PDF
PDF
PDF
PDF
勝手に解説 TopCoder Marathon Match 82 ColorLinker
PDF
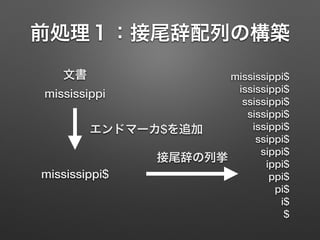
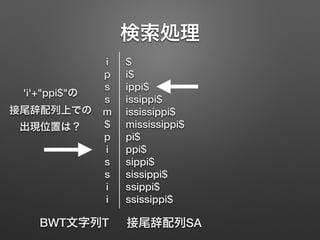
FM-indexによる全文検索 1. 2. 3. 4. 前処理1:接尾辞配列の構築
0 mississippi$
1 ississippi$
2 ssissippi$
3 sissippi$
4 issippi$
5 ssippi$
6 sippi$
7 ippi$
8 ppi$
9 pi$
10 i$
11 $
11 $
10 i$
7 ippi$
4 issippi$
1 ississippi$
0 mississippi$
9 pi$
8 ppi$
6 sippi$
3 sissippi$
5 ssippi$
2 ssissippi$
辞書順でソートする
※$は任意のアルファベットよりも
順位が小さいとする
接尾辞配列SA
5. 6. 検索処理
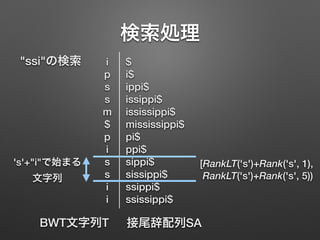
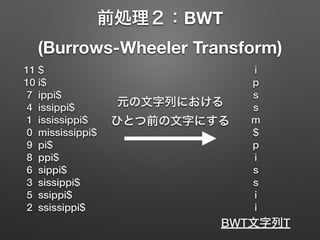
• BWT文字列T = ipssm$pissii について,
次の関数を定義する
• Rank(c,p) : T[0,p)の範囲で,
アルファベットcの出現数を返す
• RankLT(c) : T全体で, cよりも順位が小さい
アルファベットの出現数を返す
7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18.








![検索処理
$
i$
ippi$
issippi$
ississippi$
mississippi$
pi$
ppi$
sippi$
sissippi$
ssippi$
ssissippi$
i
p
s
s
m
$
p
i
s
s
i
i
BWT文字列T 接尾辞配列SA
'i'+"ppi$"の
接尾辞配列上での
出現位置は?
LF-mapping
c=T[p] に続く文字列の
SA上での出現位置は
RankLT(c)+Rank(c,p)](https://image.slidesharecdn.com/fm-index-150202091343-conversion-gate02/85/FM-index-10-320.jpg)