Download as PDF, PPTX























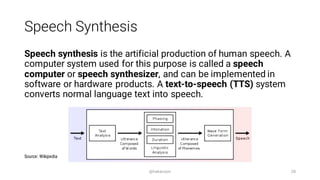














![OS X Embedded Speech Commands
Allows precise adjustments to pronunciation, word emphasize,
and overall cadence of speech
Examples:
• char NORM | LTRL
• emph + | -
• inpt TEXT | PHON | TUNE
• nmbr NORM | LTRL
• rate [+ | -] <RealValue>
@hakanson 44
Source: Speech Synthesis in OS X](https://image.slidesharecdn.com/introductiontospeechinterfacesforwebapplications-160416150903/85/Introduction-to-Speech-Interfaces-for-Web-Applications-44-320.jpg)
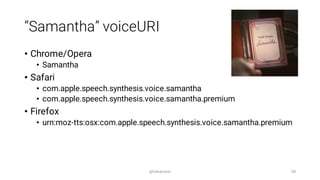
![TK-421
Text
• TK-4 2 1
SSML
• TK-<say-as interpret-as="digits">421</say-as>
OS X Comands
• TK-[[nmbr LTRL]]421[[nmbr NORM]]
@hakanson 46
http://starwars.wikia.com/wiki/TK-421](https://image.slidesharecdn.com/introductiontospeechinterfacesforwebapplications-160416150903/85/Introduction-to-Speech-Interfaces-for-Web-Applications-46-320.jpg)
![867-5309
Text
• 867-5309
SSML
• <say-as interpret-as=”telephone”>8675309</say-as>
OS X Comands
• TK-[[nmbr LTRL]]8675309[[nmbr NORM]]
@hakanson 47
https://en.wikipedia.org/wiki/867-5309/Jenny](https://image.slidesharecdn.com/introductiontospeechinterfacesforwebapplications-160416150903/85/Introduction-to-Speech-Interfaces-for-Web-Applications-47-320.jpg)
![@hakanson 48
Utterance SSML OS X Commands
lang xml:lang=“”
pitch <prosody pitch =“”> pbas [+ | -] <RealValue>
rate <prosody rate=“”> rate [+ | -] <RealValue>
voice <voice>
volume <prosody volume=“”> volm [+ | -] <RealValue>](https://image.slidesharecdn.com/introductiontospeechinterfacesforwebapplications-160416150903/85/Introduction-to-Speech-Interfaces-for-Web-Applications-48-320.jpg)










![JavaScript Example
recognition.onresult = function(event) {
var color = event.results[0][0].transcript;
diagnostic.textContent = 'Result received: ' + color + '.';
bg.style.backgroundColor = color;
}
@hakanson 59](https://image.slidesharecdn.com/introductiontospeechinterfacesforwebapplications-160416150903/85/Introduction-to-Speech-Interfaces-for-Web-Applications-59-320.jpg)


![SRGS
• Speech Recognition Grammar Specification (SRGS)
• Version 1.0; W3C Recommendation 16 March 2004
• Grammars are used so that developers can specify the words
and patterns of words to be listened for by a speech recognizer
• Augmented BNF (ABNF) or XML syntax
• Modelled on the JSpeech Grammar Format specification [JSGF]
@hakanson 62
https://www.w3.org/TR/speech-grammar/](https://image.slidesharecdn.com/introductiontospeechinterfacesforwebapplications-160416150903/85/Introduction-to-Speech-Interfaces-for-Web-Applications-62-320.jpg)




![“Alexa Skills Kit” Style Example (2 of 2)
IntentSchema.json
{
"intents": [
{
"intent": ”SetBackground",
"slots": [
{
"name": ”Color",
"type": "LIST_OF_COLORS"
}
]
}
]
}
customSlotTypes/LIST_OF_COLORS
aqua
azure
beige
bisque
black
blue
brown
chocolate
coral
crimson
cyan
…
@hakanson 67](https://image.slidesharecdn.com/introductiontospeechinterfacesforwebapplications-160416150903/85/Introduction-to-Speech-Interfaces-for-Web-Applications-67-320.jpg)
![Sample “OK, Google” Commands
• Remind me to [do a task]. Ex.: "Remind me to get dog food at Target," will create a
location-based reminder. "Remind me to take out the trash tomorrow morning,"
will give you a time-based reminder.
• When's my next meeting?
• How do I [task]? Ex.: "How do I make an Old Fashioned cocktail?" or "How do I fix
a hole in my wall?”
• If a song is playing, ask questions about the artist. For instance, "Where is she
from?" (Android 6.0 Marshmallow)
• To learn more about your surroundings, you can ask things like "What is the name
of this place?" or "Show me movies at this place" or "Who built this bridge?"
@hakanson 68
Source: “The complete list of 'OK, Google' commands”](https://image.slidesharecdn.com/introductiontospeechinterfacesforwebapplications-160416150903/85/Introduction-to-Speech-Interfaces-for-Web-Applications-68-320.jpg)
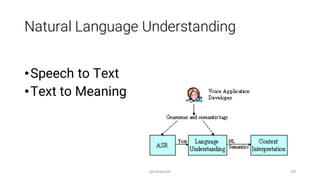











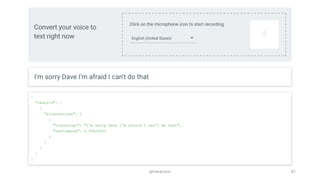



The document discusses the integration of speech interfaces in web applications using the Web Speech API, which allows for speech synthesis and recognition. It highlights concepts such as multimodal interaction, voice user interfaces, and the design considerations necessary for effective voice interactions. Furthermore, it covers current browser support and provides examples of intelligent personal assistants like Siri, Google Now, Cortana, and Alexa.

































































