Downloaded 33 times






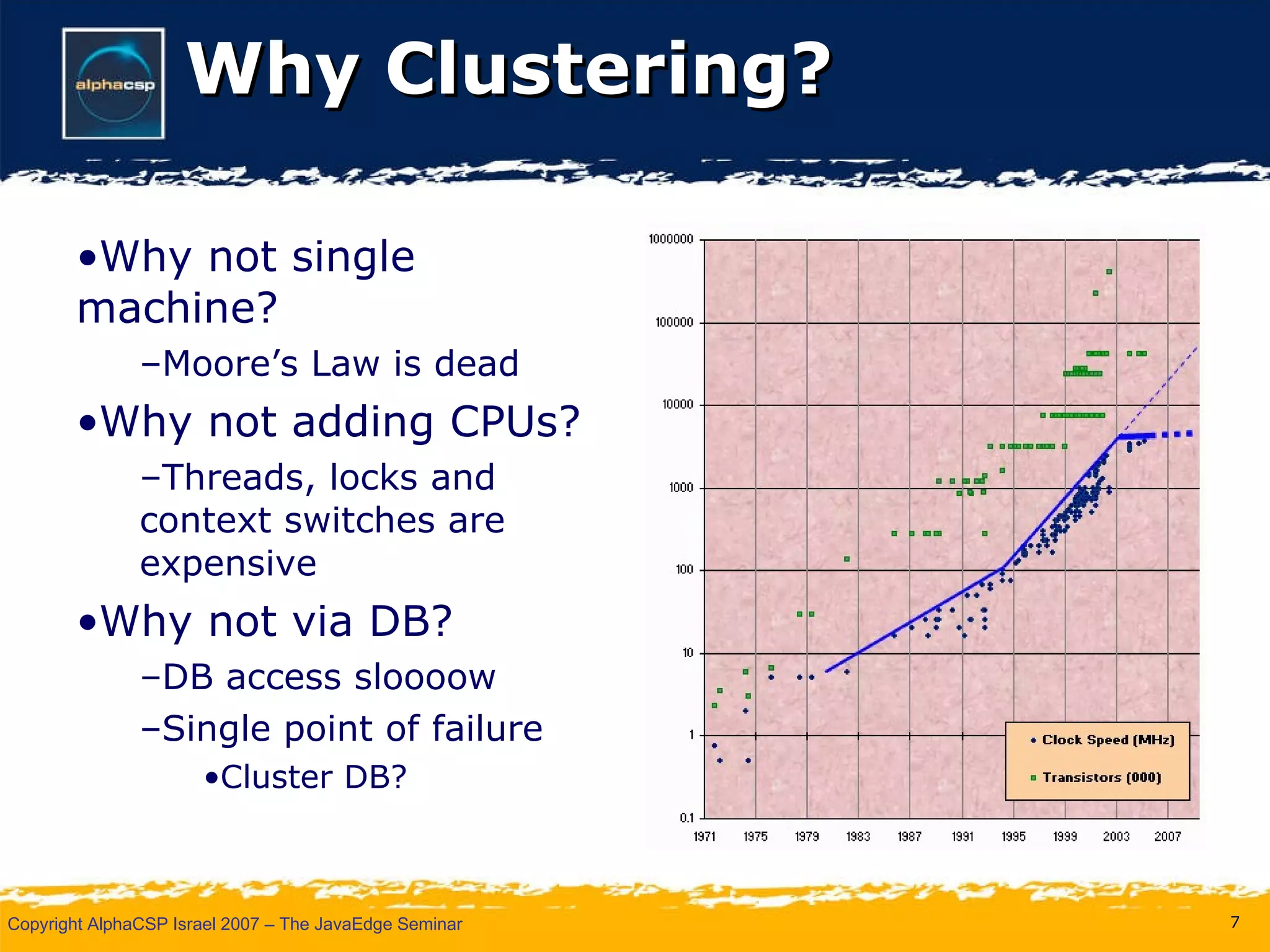











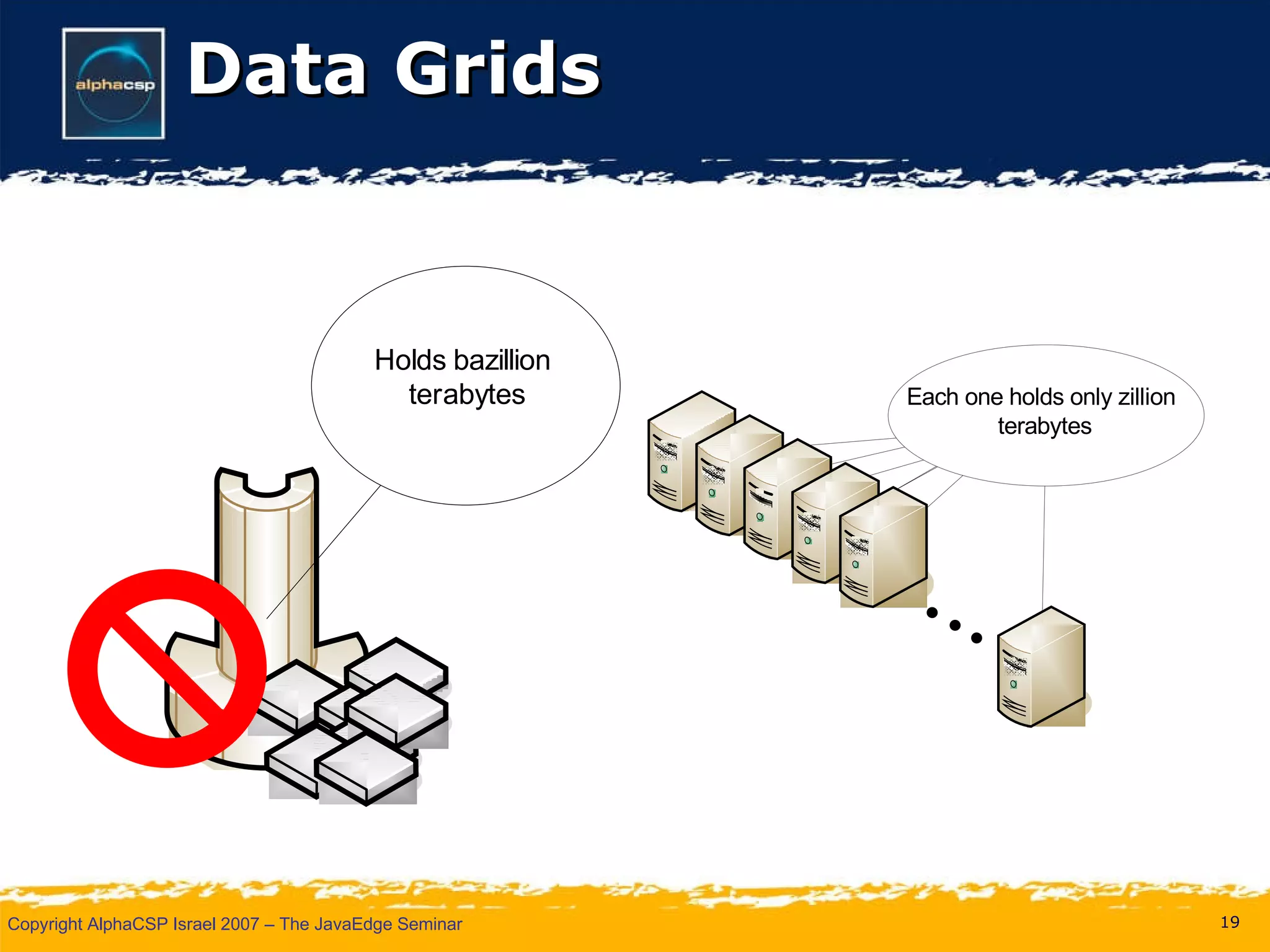




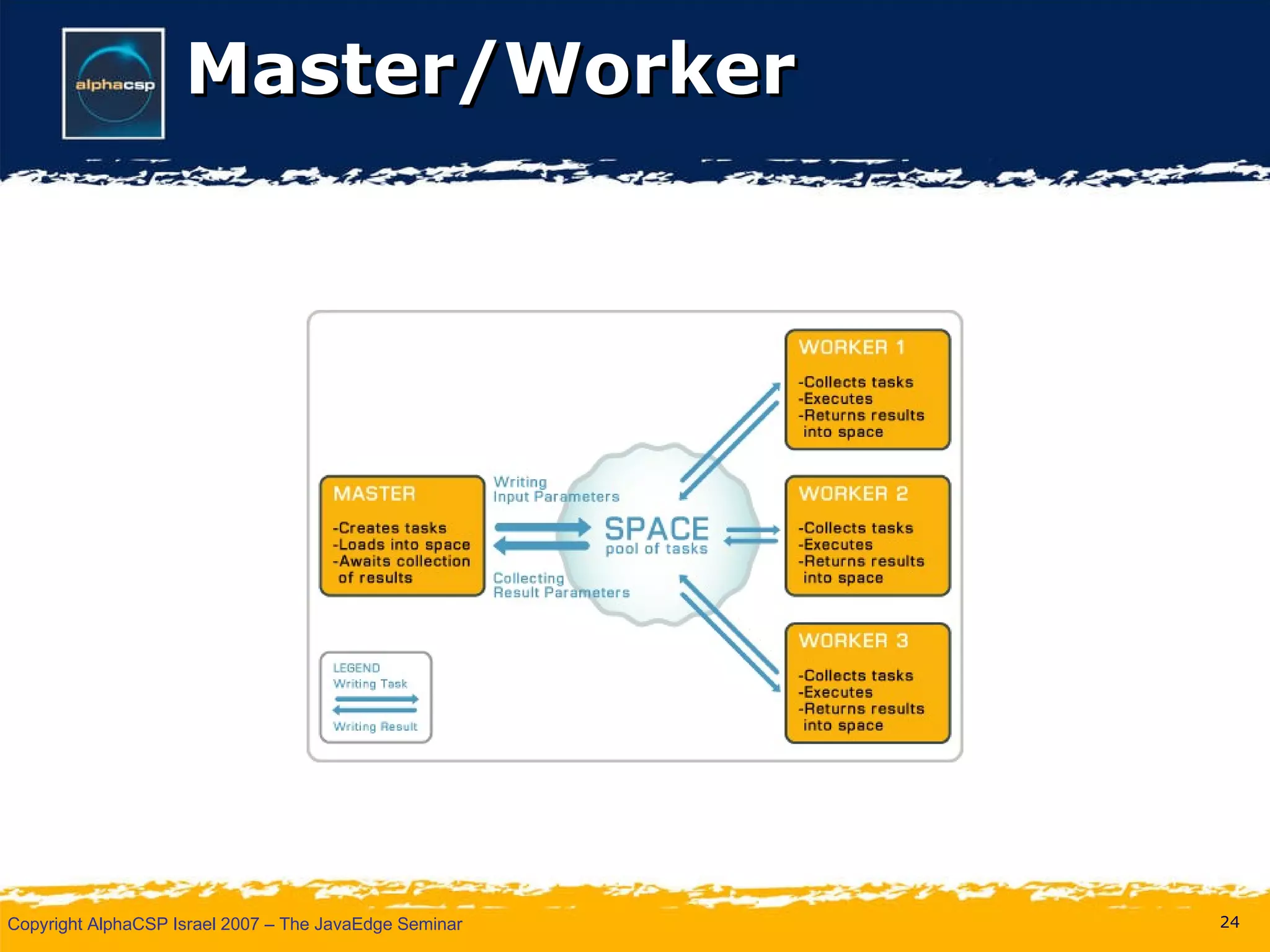
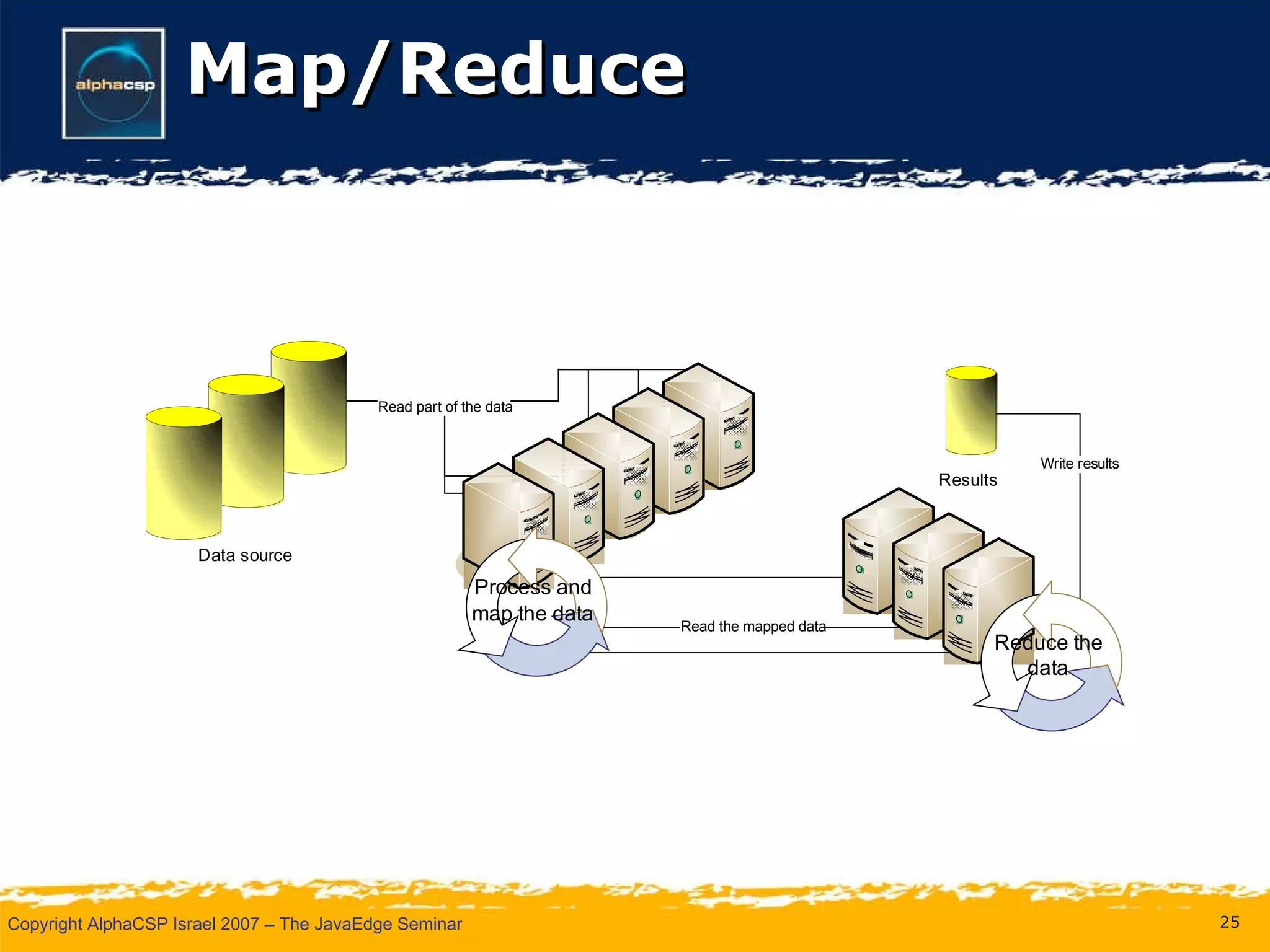



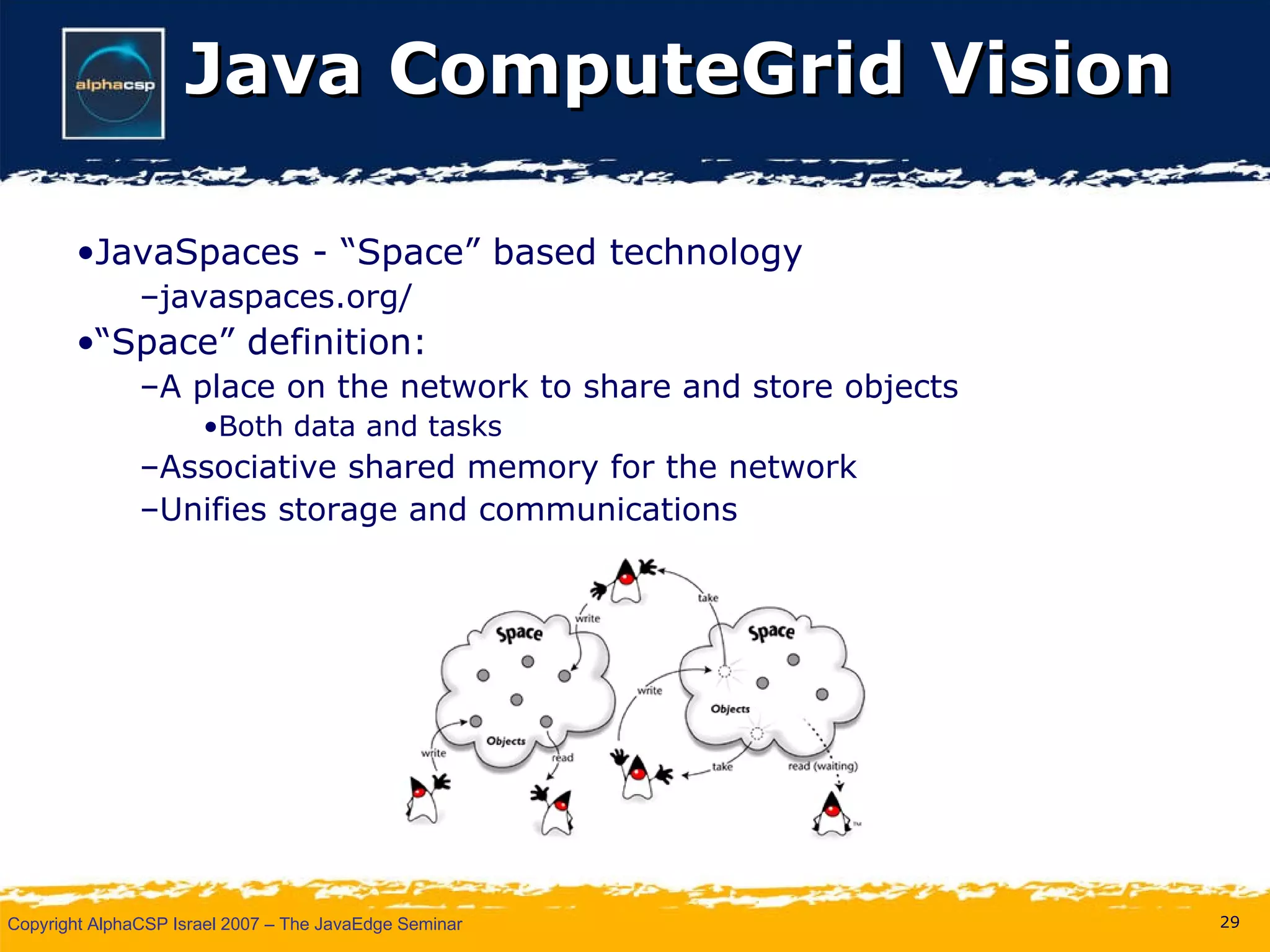


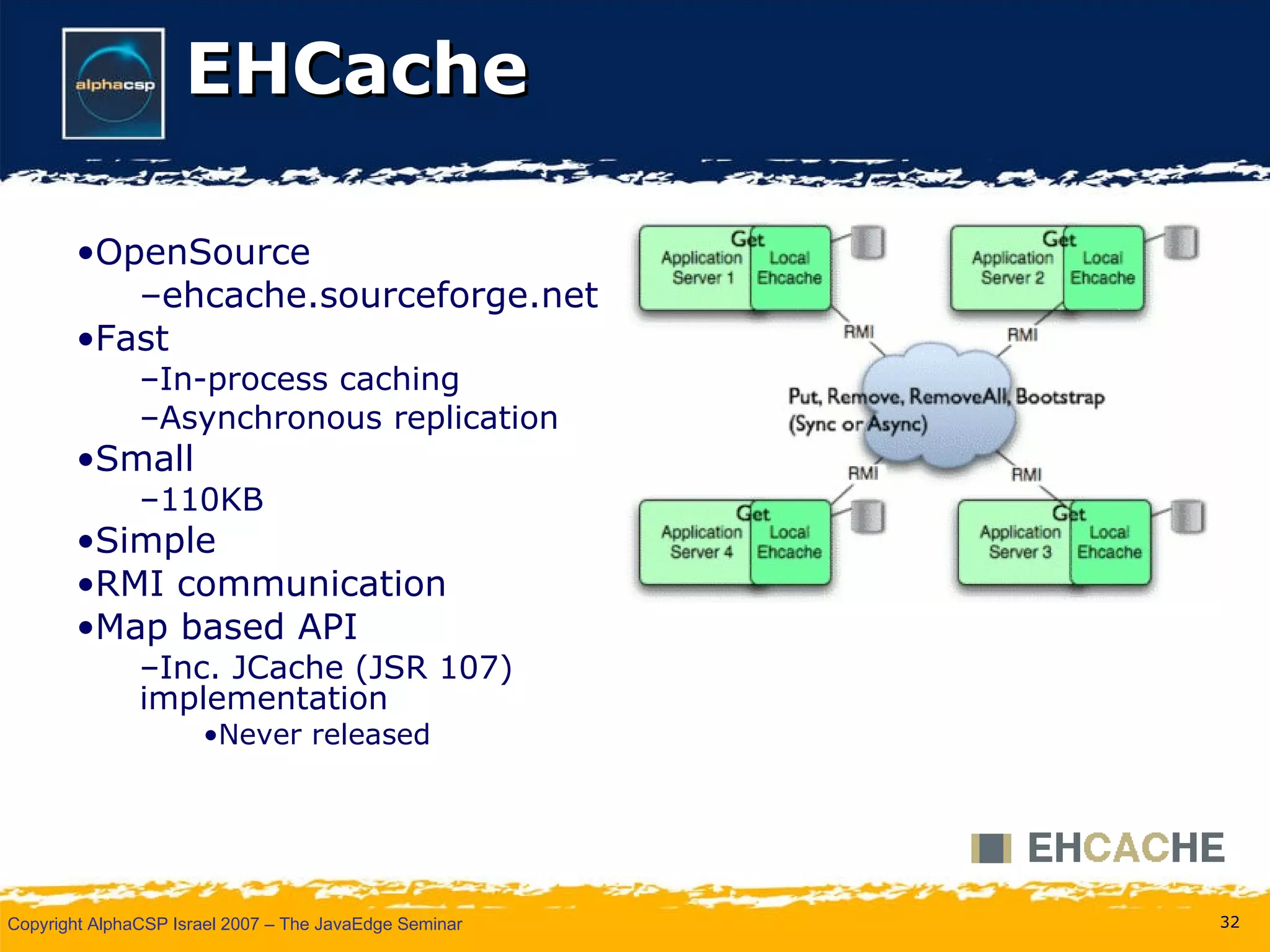






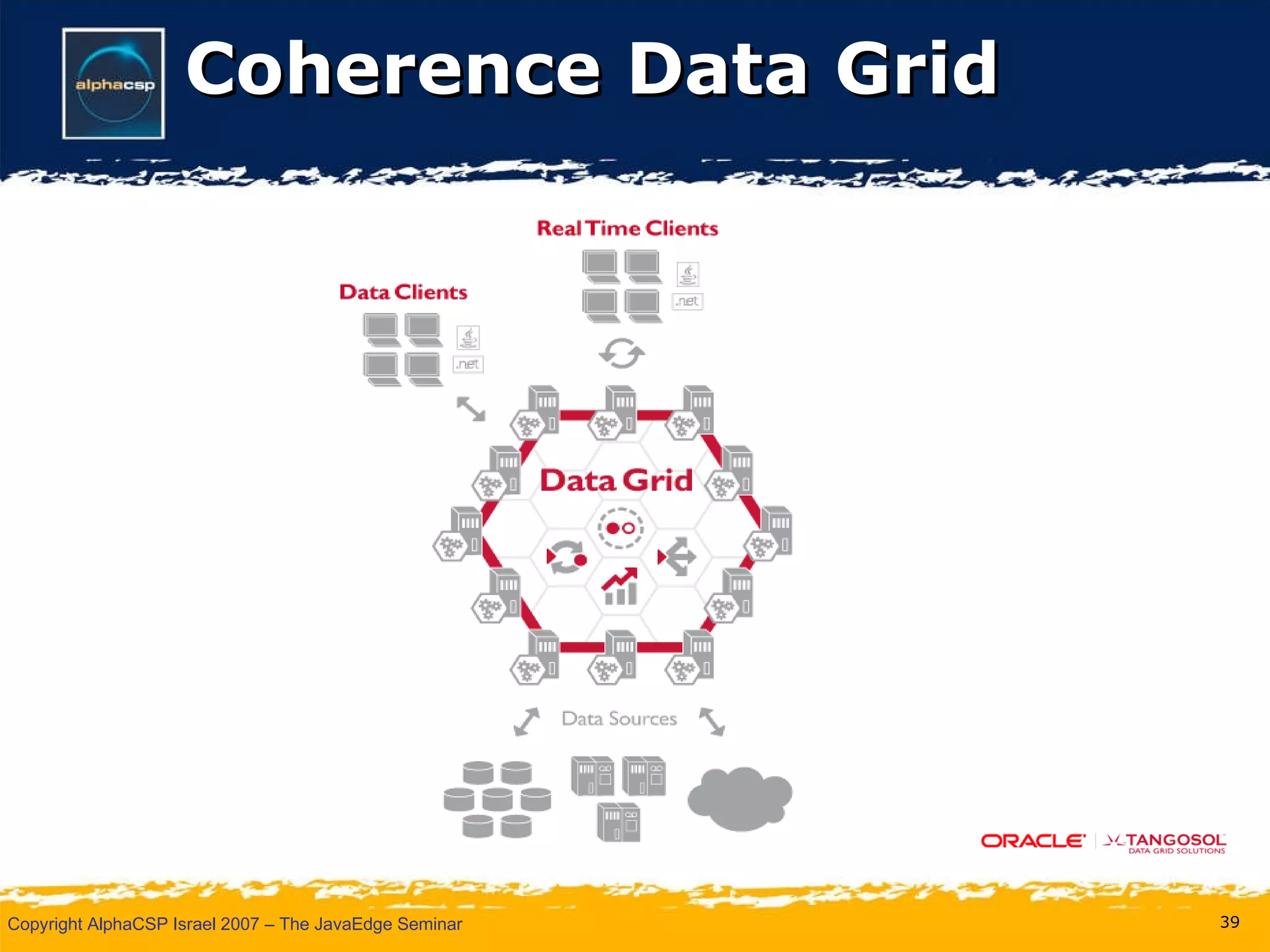










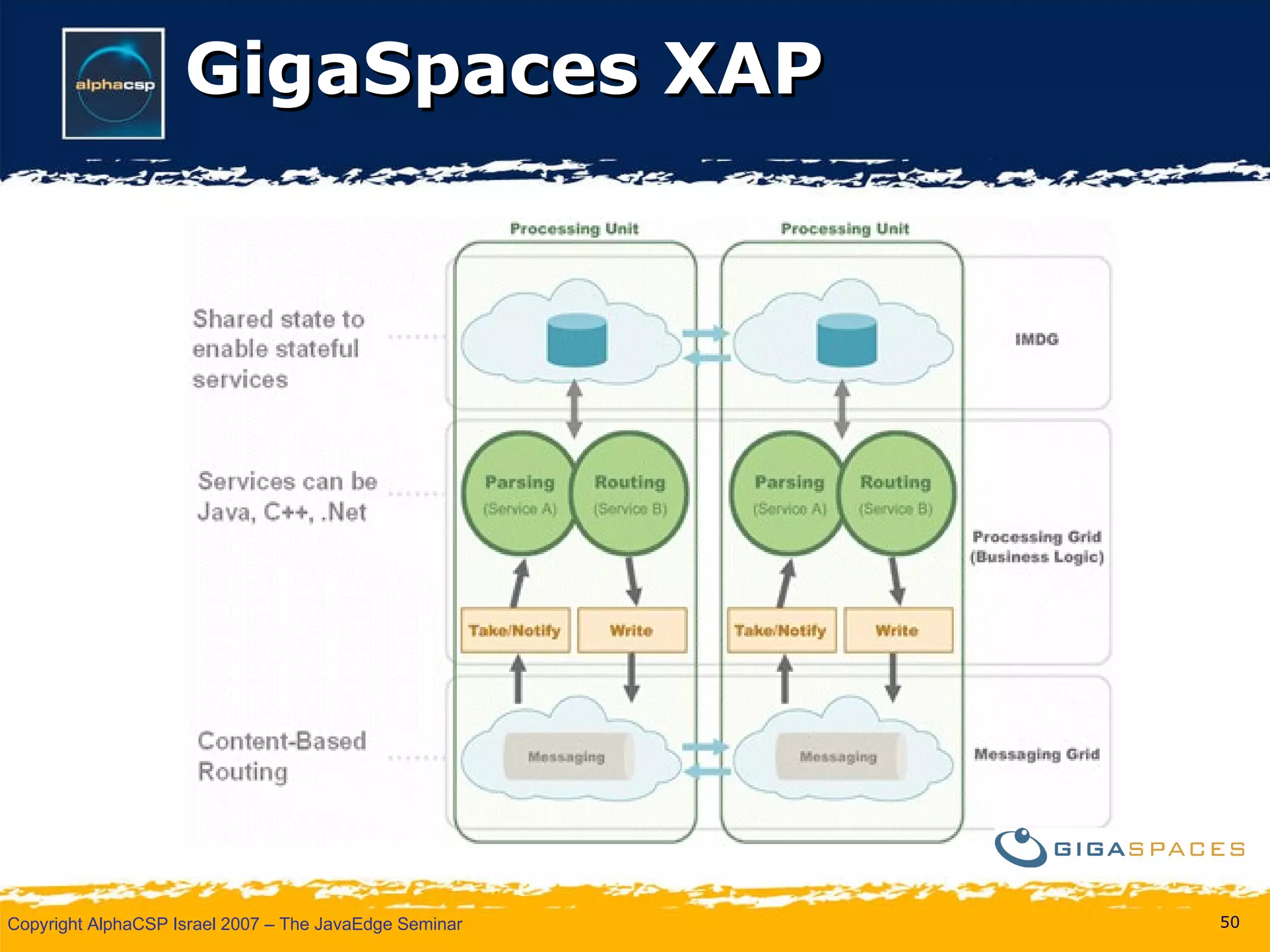






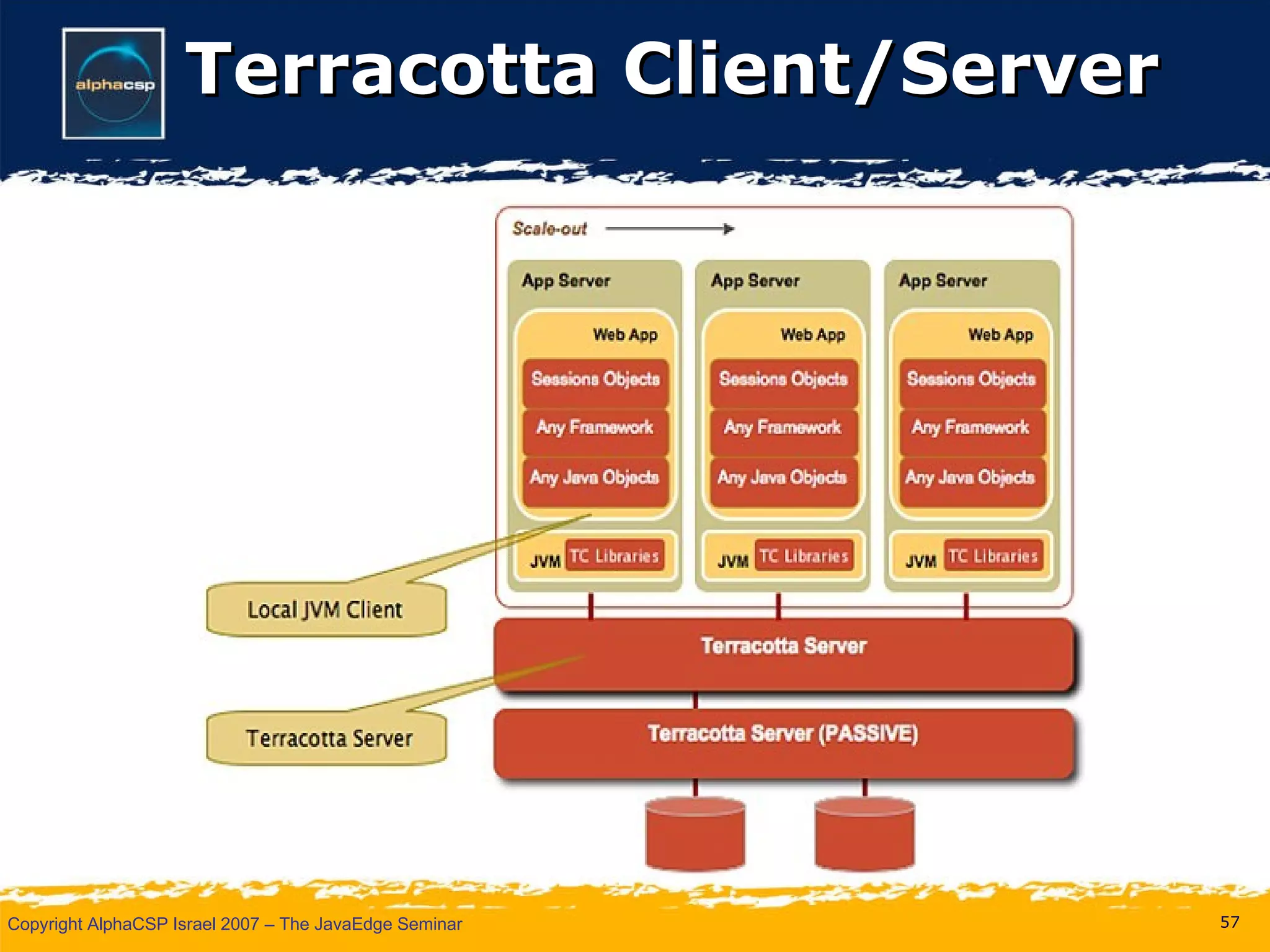





The document discusses the evolution of clustering in Java applications. It describes how early clustering solutions focused on replicating state between nodes for scalability and failover. More modern approaches use data grids, computational grids, and clustered virtual machines to distribute data and processing across nodes for improved performance and resource utilization. A variety of open source and commercial implementations are presented, including EHCache, GlassFish Shoal, Oracle Coherence, JBoss POJO Cache, GigaSpaces, and Terracotta.
















































![[Webinar] The Frog And The Butler: CI Pipelines For Modern DevOps](https://cdn.slidesharecdn.com/ss_thumbnails/jenkinsartifactory-170830053058-thumbnail.jpg?width=640&height=640&fit=bounds)



















![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


















