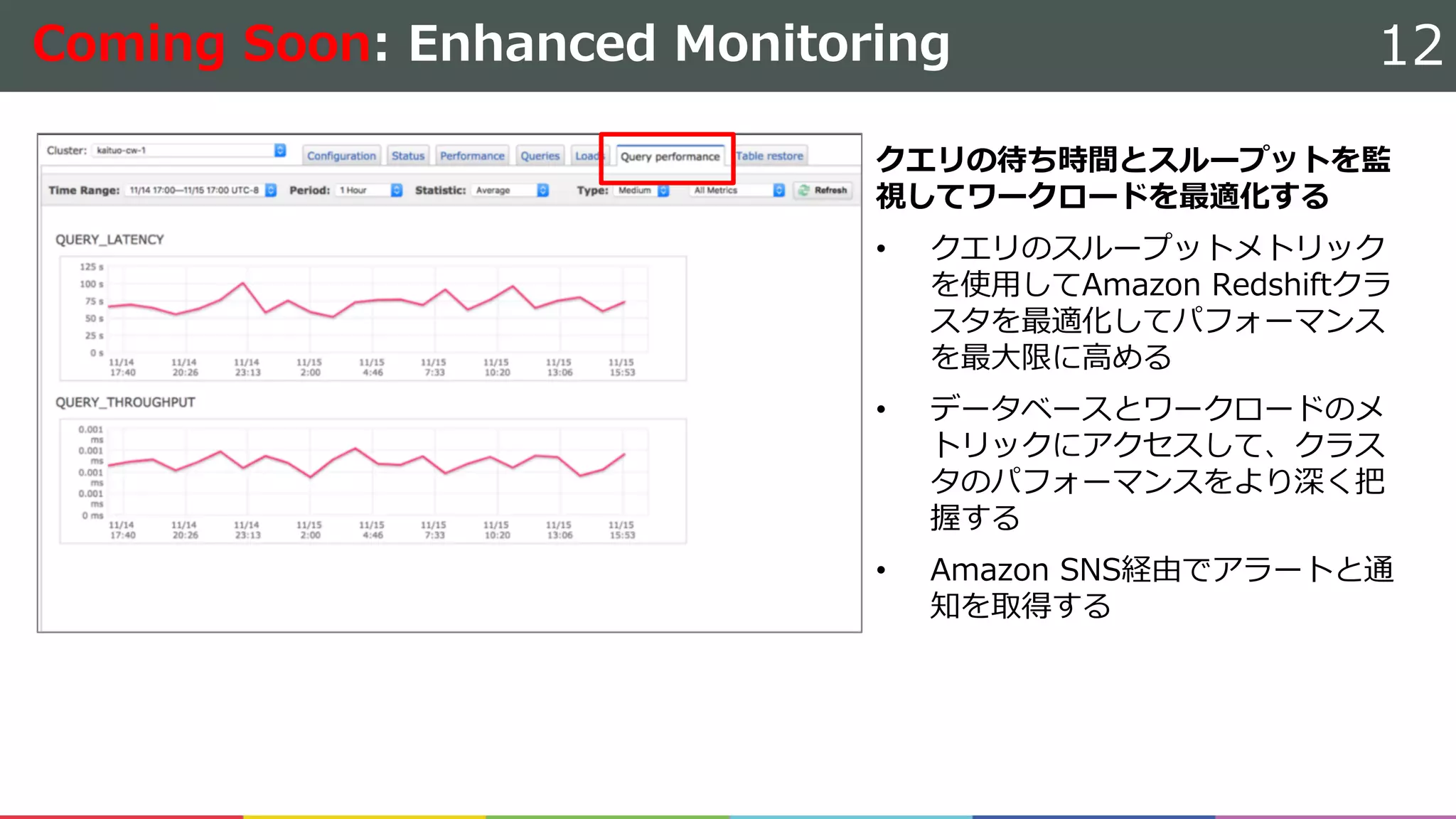
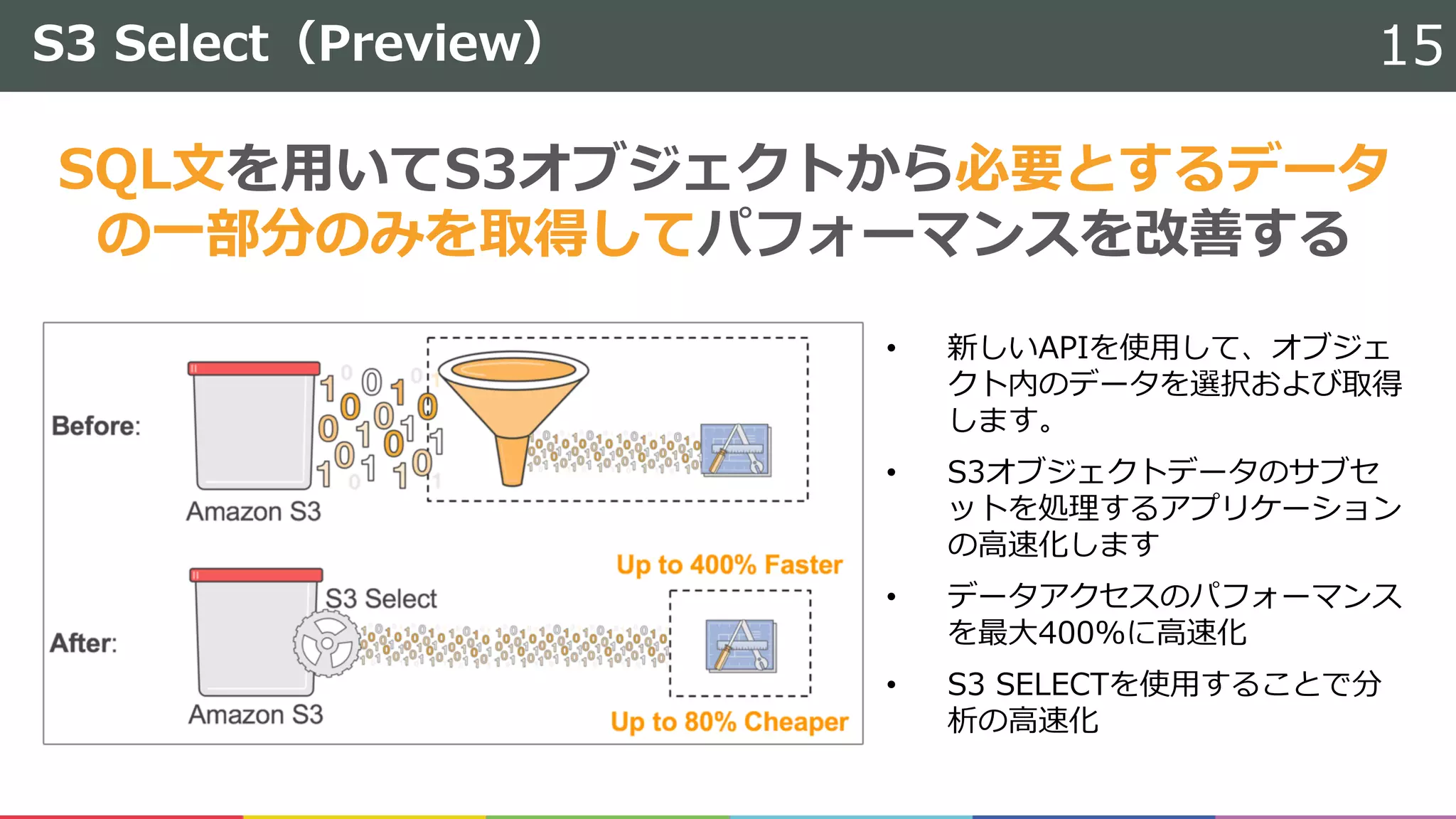
以下のDBサービスに関するアップデート・新サービスについて解説しました。 ・Amazon Redshift ・Amazon S3 Select / Glacier Select ・Amazon Neptune ・Amazon DynamoDB ・Amazon Aurora MySQL-compatible edition















































![[MongoDB勉強会 in 2017] MongoDB on AWS](https://cdn.slidesharecdn.com/ss_thumbnails/mongodb2017mongodbonaws-170912003504-thumbnail.jpg?width=640&height=640&fit=bounds)











![[CTC Forum 2019/10/25] 事例から学ぶ!AWS 移行でデータベースの管理・コストを削減する方法](https://cdn.slidesharecdn.com/ss_thumbnails/ctcforum20191025learnfromexamplesawsmigrationmethodtoreducedatabasemanagementandcost-191107204532-thumbnail.jpg?width=640&height=640&fit=bounds)






















