Download as PDF, PPTX






![© 2016 Mesosphere, Inc. All Rights Reserved.
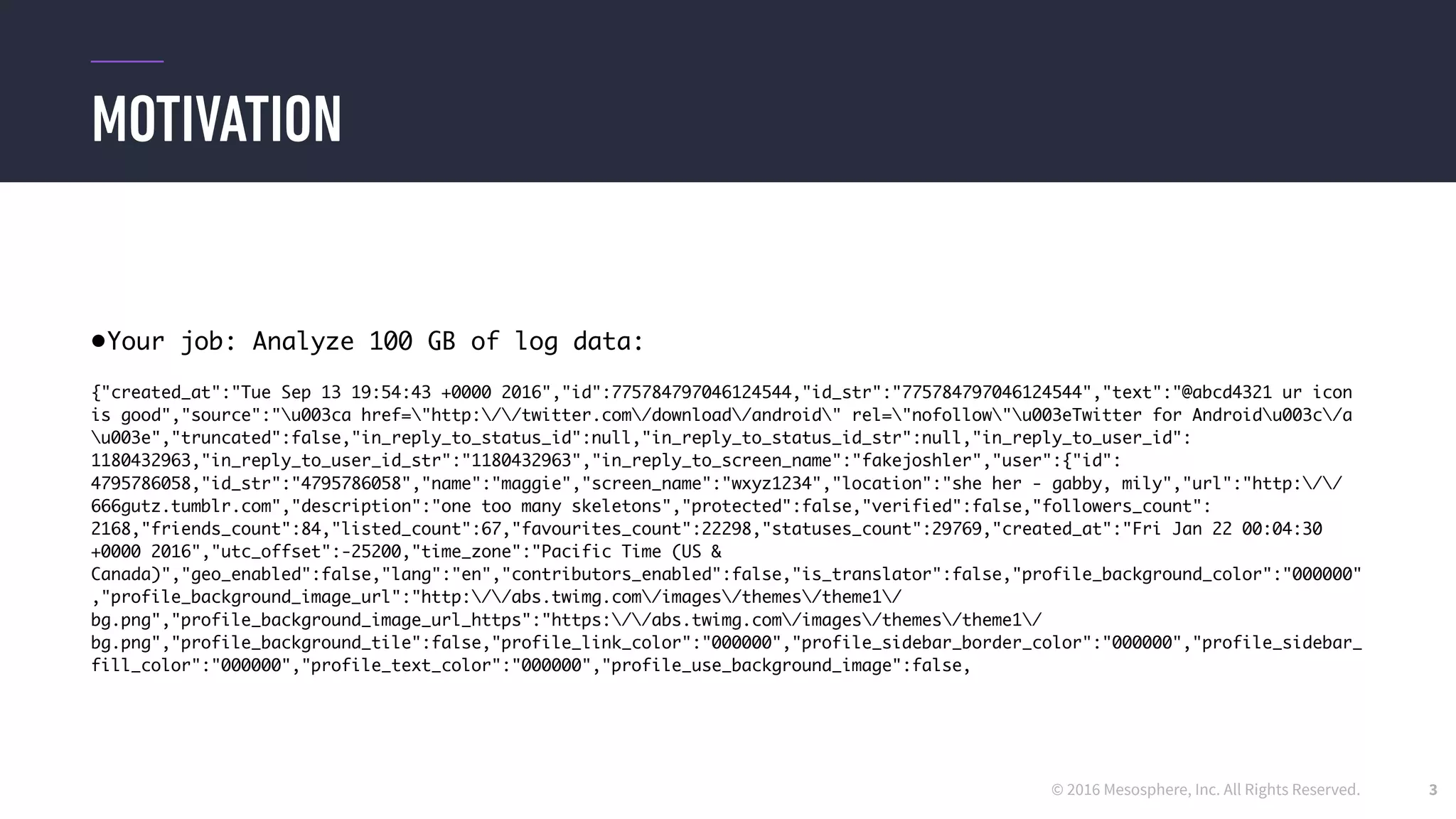
PARSE: READING JSON DATA
8
> spark
res4: org.apache.spark.sql.SparkSession@3fc09112
> val df = spark.read.json(“/path/to/mydata.json”)
df: org.apache.spark.sql.DataFrame = [contributors: string ... 33 more fields]
DataFrame: a table with rows and columns (fields)
Spark DataFrame API
"source":"u003ca href="http://twitter.com/download/android" rel=”nofollow”…](https://image.slidesharecdn.com/sparkdatamungingsbtb2016-161112222822/75/Spark-DataFrames-for-Data-Munging-8-2048.jpg)

![© 2016 Mesosphere, Inc. All Rights Reserved.
EXPLORE (CONT’D)
10
> df.filter(col(”coordinates”).isNotNull) // filters on rows, with given condition
.select("coordinates",“created_at”) // filters on columns
.show()
+------------------------------------------------+------------------------------+
|coordinates |created_at |
+------------------------------------------------+------------------------------+
|[WrappedArray(104.86544034, 15.23611896),Point] |Thu Sep 15 02:00:00 +0000 2016|
|[WrappedArray(-43.301755, -22.990065),Point] |Thu Sep 15 02:00:03 +0000 2016|
|[WrappedArray(100.3833729, 6.13822131),Point] |Thu Sep 15 02:00:30 +0000 2016|
|[WrappedArray(-122.286, 47.5592),Point] |Thu Sep 15 02:00:38 +0000 2016|
|[WrappedArray(110.823004, -6.80342),Point] |Thu Sep 15 02:00:42 +0000 2016|
Other DataFrame ops: count(), describe(), create new columns, …
Spark DataFrame API](https://image.slidesharecdn.com/sparkdatamungingsbtb2016-161112222822/75/Spark-DataFrames-for-Data-Munging-10-2048.jpg)









Spark DataFrames provide a structured API for analyzing large datasets using Spark. DataFrames allow users to parse, explore, transform, and summarize data through SQL queries and procedural processing. The demo shows analyzing 8GB of public tweet data using Spark DataFrames in Zeppelin notebooks. DataFrames simplify common data munging tasks and can also be used for machine learning, streaming data, and production data pipelines in Spark.








![Some R Examples[R table and Graphics] -Advanced Data Visualization in R (Some...](https://cdn.slidesharecdn.com/ss_thumbnails/exampless-160922204223-thumbnail.jpg?width=640&height=640&fit=bounds)

























































