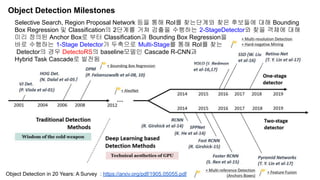
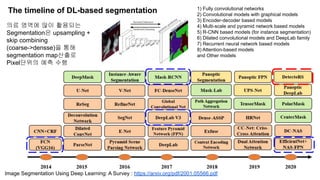
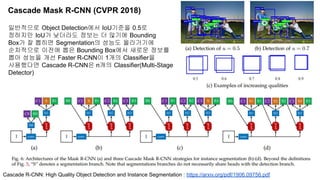
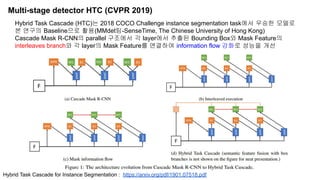
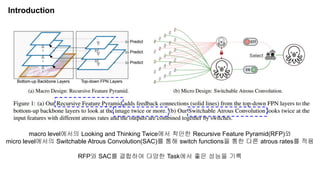
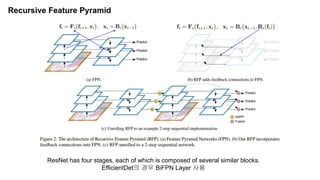
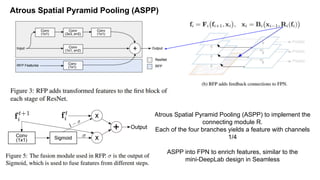
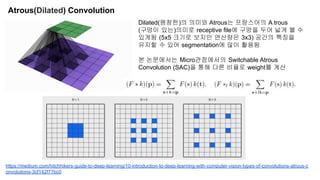
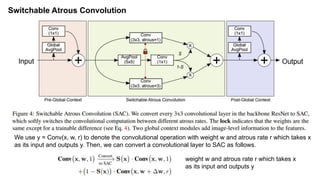
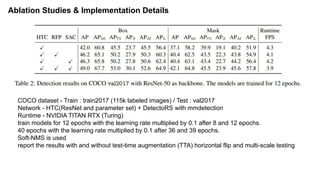
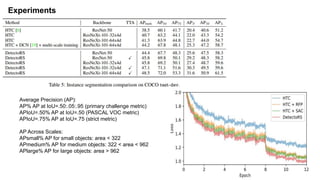
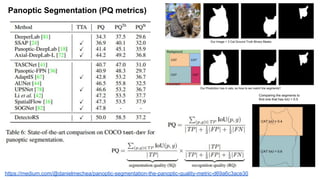
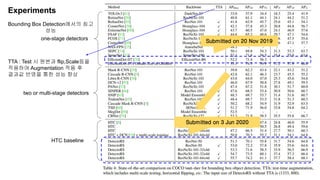
The document discusses advancements in object detection using recursive feature pyramids and switchable atrous convolution, which enhance the performance of detectors through feedback connections and multi-scale processing. It highlights the evolution of detectors, particularly the cascade R-CNN and hybrid task cascade, achieving state-of-the-art results on COCO datasets for object detection and segmentation tasks. The paper emphasizes techniques that mimic human visual perception to improve detection accuracy for occluded and large objects.






























![[ 2021 AI + X 여름 캠프 ] 3. computer vision applications](https://cdn.slidesharecdn.com/ss_thumbnails/3-210731153340-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Paper] GIRAFFE: Representing Scenes as Compositional Generative Neural Featu...](https://cdn.slidesharecdn.com/ss_thumbnails/papergirafferepresentingscenesascompositionalgenerativeneuralfeaturefields-210823043723-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] Multiscale Vision Transformers(MVit)](https://cdn.slidesharecdn.com/ss_thumbnails/papermultiscalevisiontransformers-210808092058-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] dynamic routing between capsules](https://cdn.slidesharecdn.com/ss_thumbnails/paperdynamicroutingbetweencapsules-210509101120-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] anti spoofing for face recognition](https://cdn.slidesharecdn.com/ss_thumbnails/paperanti-spoofingforfacerecognition-210508093958-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] attention mechanism(luong)](https://cdn.slidesharecdn.com/ss_thumbnails/paperattentionmechanismluong-210508090926-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] shuffle net an extremely efficient convolutional neural network for ...](https://cdn.slidesharecdn.com/ss_thumbnails/papershufflenetanextremelyefficientconvolutionalneuralnetworkformobiledevices-210424000132-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] EDA : easy data augmentation techniques for boosting performance on t...](https://cdn.slidesharecdn.com/ss_thumbnails/paperedaeasydataaugmentationtechniquesforboostingperformanceontextclassificationtasks-210414133327-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] auto ml part 1](https://cdn.slidesharecdn.com/ss_thumbnails/paperautomlpart1-210413122952-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] eXplainable ai(xai) in computer vision](https://cdn.slidesharecdn.com/ss_thumbnails/paperexplainableaixaiincomputervision-210411093712-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper] learning video representations from correspondence proposals](https://cdn.slidesharecdn.com/ss_thumbnails/paperlearningvideorepresentationsfromcorrespondenceproposals-210410235049-thumbnail.jpg?width=640&height=640&fit=bounds)

























