






























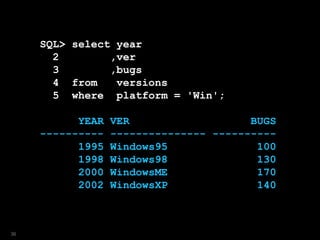
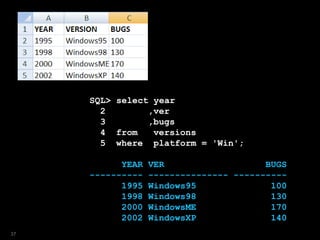

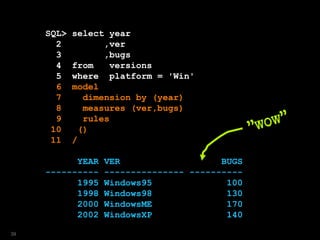

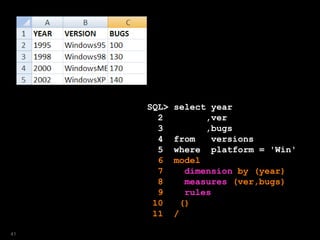





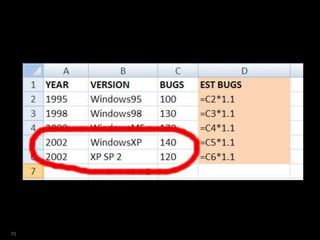
![SQL> select year
2 ,ver
3 ,bugs
4 from versions
5 where platform = 'Win'
6 model
7 dimension by (year)
8 measures (ver,bugs)
9 rules
10 ( ver[2009]='Windows7',
11 bugs[2009]=150 );
49](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-49-320.jpg)
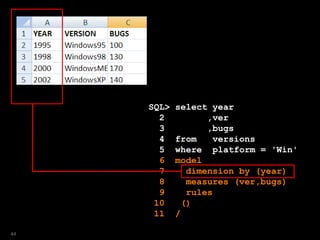
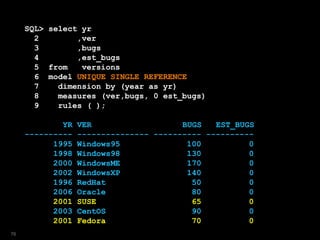
![SQL> select year
2 ,ver
3 ,bugs
4 from versions
5 where platform = 'Win'
6 model
7 dimension by (year)
8 measures (ver,bugs)
9 rules
10 ( ver[2009]='Windows7',
11 bugs[2009]=150 );
50](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-50-320.jpg)
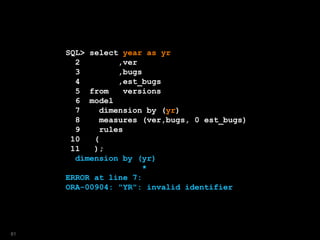
![SQL> select year
2 ,ver
3 ,bugs
4 from versions
5 where platform = 'Win'
6 model
7 dimension by (year)
8 measures (ver,bugs)
9 rules
10 ( ver[2009]='Windows7',
11 bugs[2009]=150 );
51](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-51-320.jpg)
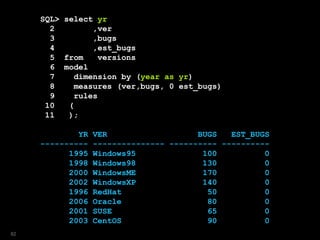
![SQL> select year
2 ,ver
3 ,bugs
4 from versions
5 where platform = 'Win'
6 model
7 dimension by (year)
8 measures (ver,bugs)
9 rules
10 ( ver[2009]='Windows7',
11 bugs[2009]=150
12 )
13 /
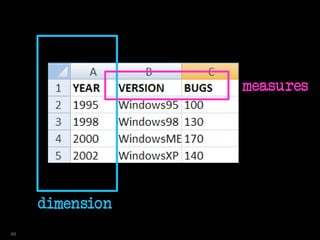
YEAR VER BUGS
---------- --------------- ----------
1995 Windows95 100
1998 Windows98 130
2000 WindowsME 170
2002 WindowsXP 140
2009 Windows7 150
52](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-52-320.jpg)
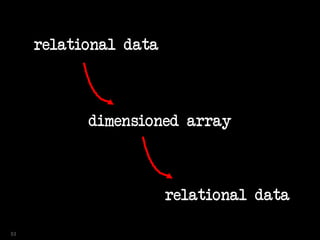



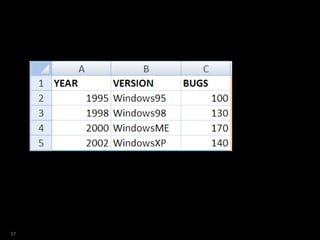

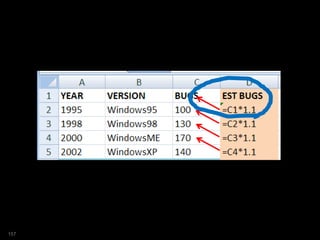
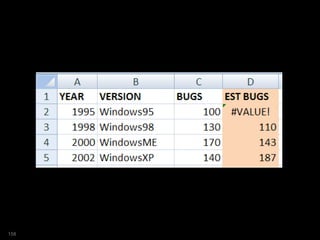
![SQL> select year
2 ,ver
3 ,bugs
4 ,est_bugs
5 from versions
6 where platform = 'Win'
7 model
8 dimension by (year)
9 measures (ver,bugs, 0 est_bugs)
10 rules sequential order
11 ( est_bugs[1995]=100 )
12 order by year;
YEAR VER BUGS EST_BUGS
---------- --------------- ---------- ----------
1995 Windows95 100 100
1998 Windows98 130 0
2000 WindowsME 170 0
2002 WindowsXP 140 0
59](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-59-320.jpg)
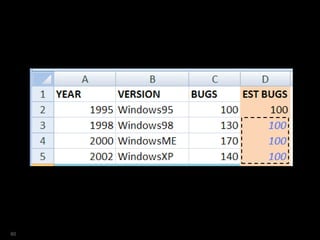
![SQL> select year
2 ,ver
3 ,bugs
4 ,est_bugs
5 from versions
6 where platform = 'Win'
7 model
8 dimension by (year)
9 measures (ver,bugs, 0 est_bugs)
10 rules sequential order
11 (
12 est_bugs[1995]=100 ,
13 est_bugs[1998]=100 ,
14 est_bugs[2000]=100 ,
15 est_bugs[2002]=100
16 ...
61](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-61-320.jpg)
![SQL> select year
2 ,ver
3 ,bugs
4 ,est_bugs
5 from versions
6 where platform = 'Win'
7 model
8 dimension by (year)
9 measures (ver,bugs, 0 est_bugs)
10 rules sequential order
11 (
12 est_bugs[ANY]=100
13 );
YEAR VER BUGS EST_BUGS
---------- --------------- ---------- ----------
1995 Windows95 100 100
1998 Windows98 130 100
2000 WindowsME 170 100
2002 WindowsXP 140 100
62](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-62-320.jpg)
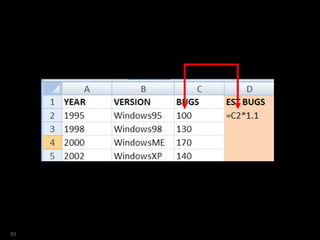
![SQL> select year
2 ,ver
3 ,bugs
4 ,est_bugs
5 from versions
6 where platform = 'Win'
7 model
8 dimension by (year)
9 measures (ver,bugs, 0 est_bugs)
10 rules sequential order
11 ( est_bugs[1995]=bugs[1995]*1.1 )
12 order by year;
YEAR VER BUGS EST_BUGS
---------- --------------- ---------- ----------
1995 Windows95 100 110
1998 Windows98 130 0
2000 WindowsME 170 0
2002 WindowsXP 140 0
64](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-64-320.jpg)
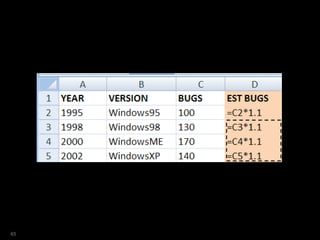

![SQL> select year
2 ,ver
3 ,bugs
4 ,est_bugs
5 from versions
6 where platform = 'Win'
7 model
8 dimension by (year)
9 measures (ver,bugs, 0 est_bugs)
10 rules
11 ( est_bugs[ANY]=bugs[CV()]*1.1
12 )
13 /
YEAR VER BUGS EST_BUGS
---------- --------------- ---------- ----------
1995 Windows95 100 110
1998 Windows98 130 143
2000 WindowsME 170 187
2002 WindowsXP 140 154
67](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-67-320.jpg)

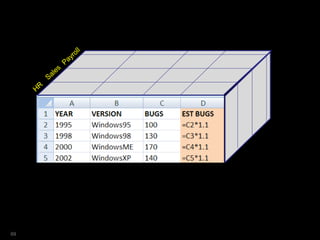
![SQL> select year
2 ,ver
3 ,bugs
4 ,est_bugs
5 from versions
6 where platform = 'Win'
7 model
8 dimension by (department, year)
9 measures (ver,bugs, 0 est_bugs)
10 rules
11 ( est_bugs['HR', ANY]=bugs['HR', CV()]*1.1
12 ( est_bugs['Sales', ANY]=bugs['Sales', CV()]*1.2
13 ( est_bugs['Payroll', ANY]=bugs['Payroll', CV()]*1.5
14 )
15 /
not just numeric
70](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-70-320.jpg)

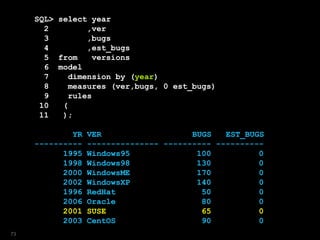
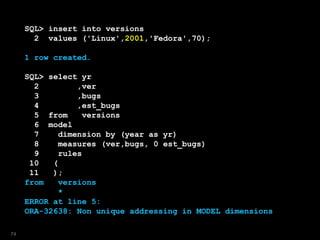


![SQL> select yr,ver,bugs,est_bugs
2 from versions
3 where platform = 'Win'
4 model
5 dimension by (year as yr)
6 measures (ver,bugs, 0 est_bugs)
7 rules
8 (
9 est_bugs[null]=140
10 );
YR VER BUGS EST_BUGS
---------- --------------- ---------- ----------
1995 Windows95 100 0
1998 Windows98 130 0
2000 WindowsME 170 0
2002 WindowsXP 140 0
(null) 140
79](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-79-320.jpg)




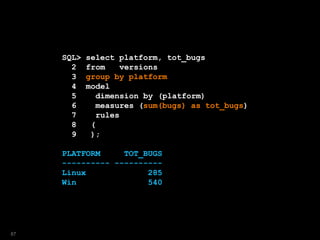
![SQL> select platform, year, ver, bugs
2 from versions
3 where platform = 'Win'
4 model
5 dimension by (year)
6 measures (ver,bugs)
7 rules
8 ( ver[2009]='Windows7',
9 bugs[2009]=150
10 );
select platform, year, ver, bugs
*
ERROR at line 1:
ORA-32614: illegal MODEL SELECT expression
91](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-91-320.jpg)
![SQL> select platform, year, ver, bugs
2 from versions
3 where platform = 'Win'
4 model
5 dimension by (year)
6 measures (ver,bugs,platform)
7 rules
8 ( ver[2009]='Windows7',
9 bugs[2009]=150
10 );
PLATFORM YEAR VER BUGS
---------- ---------- --------------- ----------
Win 1995 Windows95 100
Win 1998 Windows98 130
Win 2000 WindowsME 170
Win 2002 WindowsXP 140
2009 Windows7 150
92](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-92-320.jpg)

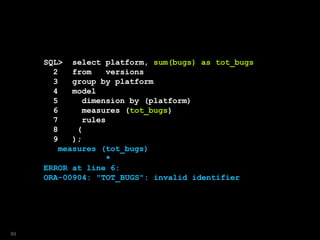
![SQL> select year, ver, bugs
2 from versions
3 where platform = 'Win'
4 model
5 dimension by (year)
6 measures (ver,bugs,year)
7 rules
8 ( ver[2009]='Windows7',
9 bugs[2009]=150,
10 year[2009]=2010
11 );
select year, ver, bugs
*
ERROR at line 1:
ORA-00957: duplicate column name
94](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-94-320.jpg)
![SQL> select year, ver, bugs
2 from versions
3 where platform = 'Win'
4 model
5 dimension by (year)
6 measures (ver,bugs,year next_year)
7 rules
8 ( ver[2009]='Windows7',
9 bugs[2009]=150,
10 next_year[2009]=2010
11 );
YEAR VER BUGS
---------- --------------- ----------
1995 Windows95 100
1998 Windows98 130
2000 WindowsME 170
2002 WindowsXP 140
2009 Windows7 150
95](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-95-320.jpg)
![SQL> select year, ver, bugs, next_year
2 from versions
3 where platform = 'Win'
4 model
5 dimension by (year)
6 measures (ver,bugs,year next_year)
7 rules
8 ( ver[2009]='Windows7',
9 bugs[2009]=150,
10 next_year[2009]=2010
11 );
YEAR VER BUGS NEXT_YEAR
---------- --------------- ---------- ----------
1995 Windows95 100 1995
1998 Windows98 130 1998
2000 WindowsME 170 2000
2002 WindowsXP 140 2002
2009 Windows7 150 2010
96](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-96-320.jpg)

![SQL> select year, ver, bugs
2 from versions
3 where platform = 'Win'
4 model
5 dimension by (year)
6 measures (ver,bugs,null est_sales)
7 rules
8 (
9 est_sales[ANY]=0
10 );
measures (ver,bugs,null est_sales)
*
ERROR at line 6:
ORA-01723: zero-length columns are not allowed
98](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-98-320.jpg)
![SQL> select year, ver, bugs
2 from versions
3 where platform = 'Win'
4 model
5 dimension by (year)
6 measures (ver,bugs,to_number(null) est_sales)
7 rules
8 (
9 est_sales[ANY]=0
10 );
YEAR VER BUGS
---------- --------------- ----------
1995 Windows95 100
1998 Windows98 130
2000 WindowsME 170
2002 WindowsXP 140
99](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-99-320.jpg)
![SQL> select year, ver, bugs, sales_rep
2 from versions
3 where platform = 'Win'
4 model
5 dimension by (year)
6 measures (ver,bugs,
7 cast(null as varchar2(20)) sales_rep)
8 rules
9 (
10 sales_rep[2000]='Mike'
11 );
YEAR VER BUGS SALES_REP
---------- --------------- ---------- --------------------
1995 Windows95 100
1998 Windows98 130
2002 WindowsXP 140
2000 WindowsME 170 Mike
100](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-100-320.jpg)
![SQL> select year, ver, bugs, sales_rep
2 from versions
3 where platform = 'Win'
4 model
5 dimension by (year)
6 measures (ver,bugs,'Unknown' sales_rep)
7 rules
8 (
9 sales_rep[2000]='Mike Jones'
10 );
ERROR:
ORA-25137: Data value out of range
101](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-101-320.jpg)
![SQL> select year, ver, bugs, sales_rep
2 from versions
3 where platform = 'Win'
4 model
5 dimension by (year)
6 measures (ver,bugs,
7 cast('Unknown' as varchar2(20)) sales_rep)
8 rules
9 (
10 sales_rep[2000]='Mike Jones'
11 );
YEAR VER BUGS SALES_REP
---------- --------------- ---------- --------------------
1995 Windows95 100 Unknown
1998 Windows98 130 Unknown
2002 WindowsXP 140 Unknown
2000 WindowsME 170 Mike Jones
102](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-102-320.jpg)

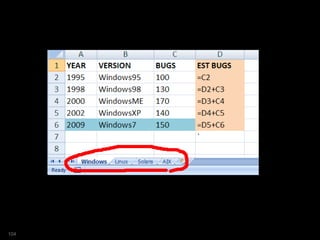
![SQL> select platform
...
6 from versions
7 model
8 partition by ( platform )
9 dimension by (year)
10 measures (ver,bugs, 0 est_bugs)
11 rules
12 ( est_bugs[1995]=bugs[1995],
13 est_bugs[year > 1995]=bugs[CV()]*1.1
14 );
PLATFORM YEAR VER BUGS EST_BUGS
---------- ---------- --------------- ---------- ----------
Linux 1996 RedHat 50 55
Linux 2006 Oracle 80 88
Linux 2001 SUSE 65 71.5
Linux 2003 CentOS 90 99
Linux 1995
Win 1995 Windows95 100 100
Win 1998 Windows98 130 143
Win 2000 WindowsME 170 187
Win 2002 WindowsXP 140 154
105](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-105-320.jpg)



![SQL> select yr
2 ,ver
3 ,bugs
4 ,est_bugs
5 from versions
6 where platform = 'Win'
7 model
8 dimension by (year as yr)
9 measures (ver,bugs, 0 est_bugs)
10 rules
11 (
12 est_bugs[1998]=100,
13 bugs[2000]= :bindvar,
14 est_bugs[2009]= dbms_random.value(80,100)
15 );
YR VER BUGS EST_BUGS
---------- ------------ ---------- ----------
1995 Windows95 100 0
2002 WindowsXP 140 0
1998 Windows98 130 100
2000 WindowsME <:bv> 0
2009 90.1501647
109](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-109-320.jpg)

![SQL> select yr
2 ,ver
3 ,bugs
4 ,est_bugs
5 from versions
6 where platform = 'Win'
7 model
8 dimension by (year as yr)
9 measures (ver,bugs, 0 est_bugs)
10 rules
11 (
12 est_bugs[2009]=
13 ( select max(bugs) from versions )
14 );
select yr
*
ERROR at line 1:
ORA-32620: illegal subquery within MODEL rules
111](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-111-320.jpg)
![SQL> select yr
2 ,ver
3 ,bugs
4 ,est_bugs
5 from versions
6 where platform = 'Win'
7 model
8 dimension by (year as yr)
9 measures (ver,bugs, 0 est_bugs,
10 ( select max(bugs) from versions ) x)
11 rules
12 (
13 est_bugs[2009]= x[2000]
14 );
YR VER BUGS EST_BUGS
---------- ------------ ---------- ----------
1995 Windows95 100 0
1998 Windows98 130 0
2002 WindowsXP 140 0
2000 WindowsME 170 0
2009 170
112](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-112-320.jpg)

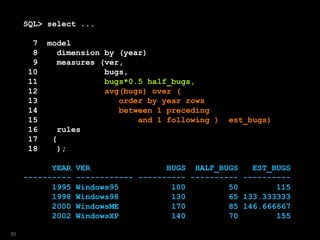
![SQL> select year
2 ,ver
3 ,bugs
4 ,est_bugs
5 from versions
6 where platform = 'Win'
7 model
8 dimension by (year)
9 measures (ver,bugs, 0 est_bugs)
10 rules
11 ( est_bugs[ANY]=bugs[CV()]*1.1
12 )
13 /
YEAR VER BUGS EST_BUGS
---------- --------------- ---------- ----------
1995 Windows95 100 110
1998 Windows98 130 143
2000 WindowsME 170 187
2002 WindowsXP 140 154
114](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-114-320.jpg)
![SQL> select year
2 ,ver
3 ,bugs
4 ,est_bugs
5 from versions
6 where platform = 'Win'
7 model
8 dimension by (year)
9 measures (ver,bugs, 0 est_bugs, 0 zero_bug)
10 rules
11 ( zero_bug[ANY]=CV()+10
12 );
( zero_bug[ANY]=CV()+10
*
ERROR at line 11:
ORA-32611: incorrect use of MODEL CV operator
115](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-115-320.jpg)
![SQL> select year
2 ,ver
3 ,bugs
4 ,est_bugs
5 ,zero_bug
6 from versions
7 where platform = 'Win'
8 model
9 dimension by (year)
10 measures (ver,bugs, 0 est_bugs, 0 zero_bug)
11 rules
12 ( zero_bug[ANY]=CV(YEAR)+10
13 );
YEAR VER BUGS EST_BUGS ZERO_BUG
---------- ------------ ---------- ---------- ----------
1995 Windows95 100 0 2005
1998 Windows98 130 0 2008
2000 WindowsME 170 0 2010
2002 WindowsXP 140 0 2012
116](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-116-320.jpg)

![SQL> select fib
2 from ( select rownum r from dual
3 connect by level <= 10 )
4 model
5 dimension by (r)
6 measures (0 fib)
7 rules
8 ( fib[1]=1,
9 fib[2]=1,
10 fib[r>2]=fib[CV()-1]+fib[CV()-2] );
FIB
----------
1
1
2
3
5
8
13
21
34
55
118](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-118-320.jpg)


![SQL> select yr
2 ,ver
3 ,bugs
4 ,est_bugs
5 from versions
6 where platform = 'Win'
7 model
8 dimension by (year as yr)
9 measures (ver,bugs, 0 est_bugs)
10 rules
11 (
12 est_bugs[2009]=100,
13 ver[2009]='Windows7'
14 );
YR VER BUGS EST_BUGS
---------- ------------ ---------- ----------
1995 Windows95 100 0
1998 Windows98 130 0
2000 WindowsME 170 0
2002 WindowsXP 140 0
2009 Windows7 100
update or create a
dimension value of '2009'
121](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-121-320.jpg)
![SQL> select yr
2 ,ver
3 ,bugs
4 ,est_bugs
5 from versions
6 where platform = 'Win'
7 model
8 dimension by (year as yr)
9 measures (ver,bugs, 0 est_bugs)
10 rules
11 (
12 est_bugs[yr=2009]=100,
13 ver[yr=2009]='Windows7'
14 );
YR VER BUGS EST_BUGS
---------- ------------ ---------- ----------
1995 Windows95 100 0
1998 Windows98 130 0
2000 WindowsME 170 0
2002 WindowsXP 140 0
update if exists a
dimension value of '2009'
122](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-122-320.jpg)

![SQL> select yr
2 ,ver
3 ,bugs
4 ,est_bugs
5 from versions
6 where platform = 'Win'
7 model
8 dimension by (year as yr)
9 measures (ver,bugs, 0 est_bugs)
10 rules
11 (
12 est_bugs[yr IN (2000,2009)]=100
13 );
YR VER BUGS EST_BUGS
---------- ------------ ---------- ----------
1995 Windows95 100 0
1998 Windows98 130 0
2002 WindowsXP 140 0
2000 WindowsME 170 100
124](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-124-320.jpg)
![SQL> select yr
2 ,ver
3 ,bugs
4 ,est_bugs
5 from versions
6 where platform = 'Win'
7 model
8 dimension by (year as yr)
9 measures (ver,bugs, 0 est_bugs)
10 rules
11 (
12 est_bugs[FOR yr IN (2000,2009)]=100
13 );
YR VER BUGS EST_BUGS
---------- ------------ ---------- ----------
1995 Windows95 100 0
1998 Windows98 130 0
2002 WindowsXP 140 0
2000 WindowsME 170 100
2009 100
125](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-125-320.jpg)
![SQL> select yr
2 ,ver
3 ,bugs
4 ,est_bugs
5 from versions
6 where platform = 'Win'
7 model
8 dimension by (year as yr)
9 measures (ver,bugs, 0 est_bugs)
10 rules
11 (
12 est_bugs[FOR yr FROM 2002 TO 2005 INCREMENT 1]=100
13 );
YR VER BUGS EST_BUGS
---------- ------------ ---------- ----------
1995 Windows95 100 0
1998 Windows98 130 0
2000 WindowsME 170 0
2002 WindowsXP 140 100
2003 100
2004 100
2005 100
126](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-126-320.jpg)
![SQL> select ...
7 model
8 dimension by (year as yr)
9 measures (ver,bugs, 0 est_bugs)
10 rules
11 (
12 est_bugs[FOR yr IN
13 ( select year
14 from versions
15 where platform = 'Linux') ]=100
16 );
YR VER BUGS EST_BUGS
---------- ------------ ---------- ----------
1995 Windows95 100 0
1998 Windows98 130 0
2000 WindowsME 170 0
2002 WindowsXP 140 0
1996 100
2006 100
2001 100
2003 100
127](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-127-320.jpg)

![SQL> select yr
2 ,ver
3 ,bugs
4 ,est_bugs
5 from versions
6 where platform = 'Win'
7 model
8 dimension by (year as yr)
9 measures (ver,bugs, 0 est_bugs)
10 rules
11 (
12 est_bugs[FOR yr IN (2000,2009)]=100,
13 ver[2009]='Windows7' );
YR VER BUGS EST_BUGS
---------- ------------ ---------- ----------
1995 Windows95 100 0
1998 Windows98 130 0
2002 WindowsXP 140 0
2000 WindowsME 170 100
2009 Windows7 100
UPSERT
129](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-129-320.jpg)
![SQL> select yr
2 ,ver
3 ,bugs
4 ,est_bugs
5 from versions
6 where platform = 'Win'
7 model
8 dimension by (year as yr)
9 measures (ver,bugs, 0 est_bugs)
10 rules UPDATE
11 (
12 est_bugs[FOR yr IN (2000,2009)]=100,
13 ver[2009]='Windows7' );
YR VER BUGS EST_BUGS
---------- ------------ ---------- ----------
1995 Windows95 100 0
1998 Windows98 130 0
2002 WindowsXP 140 0
2000 WindowsME 170 100
2009 Windows7 100
2009 gone
130](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-130-320.jpg)

![SQL> select *
2 from versions
3 where platform = 'z/OS';
no rows selected
SQL> select *
2 from versions
3 where platform = 'z/OS'
4 model
5 dimension by (year as yr)
6 measures (ver, 0 est_bugs)
7 rules
8 ( est_bugs[FOR yr IN (2000,2002,2009)]=100,
9 ver[ANY]='IBM' );
YR VER EST_BUGS
---------- --------------- ----------
2000 IBM 100
2002 IBM 100
2009 IBM 100
132](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-132-320.jpg)


![SQL> select yr
2 ,ver
3 ,bugs
4 ,est_bugs
5 from versions
6 where platform = 'Win'
7 model
8 dimension by (year as yr)
9 measures (ver,bugs, 0 est_bugs, year as yr2)
10 rules
11 (
12 yr2[ANY]=yr2[CV()]-2,
13 est_bugs[yr2[2000]]=100
14 );
YR VER BUGS EST_BUGS
---------- ------------ ---------- ----------
1995 Windows95 100 0
1998 Windows98 130 100
2000 WindowsME 170 0
2002 WindowsXP 140 0
yr2[2000]=2000-2=1998
est_bugs[1998]=100
135](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-135-320.jpg)

![SQL> select ...
7 model
8 dimension by (year as yr)
9 measures (ver,bugs, 0 est_bugs)
10 rules
11 (
12 est_bugs[yr is null]=100,
13 est_bugs[yr is not null]=110,
14 est_bugs[yr > 0]=120,
15 est_bugs[yr between 2000 and 2010]=130,
16 est_bugs[null]=140
17 );
YR VER BUGS EST_BUGS
---------- ------------ ---------- ----------
1995 Windows95 100 120
1998 Windows98 130 120
2000 WindowsME 170 130
2002 WindowsXP 140 130
(null) 140
137](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-137-320.jpg)
![SQL> select year
2 ,ver
3 ,bugs
4 ,est_bugs
5 from versions
6 model
7 dimension by (platform,year)
8 measures (ver,bugs, 0 est_bugs)
9 rules
10 (
11 est_bugs[2009]=100
12 );
est_bugs[2009]=100
*
ERROR at line 11:
ORA-00947: not enough values
139](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-139-320.jpg)
![SQL> select year
2 ,ver
3 ,bugs
4 ,est_bugs
5 from versions
6 where platform = 'Win'
7 model
8 dimension by (year)
9 measures (ver,bugs, 0 est_bugs)
10 rules
11 (
12 est_bugs['Win',2009]=100
13 );
est_bugs['Win',2009]=100
*
ERROR at line 12:
ORA-00947: not enough values
140](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-140-320.jpg)

![SQL> select year
2 ,ver
3 ,bugs
4 ,cumtot
5 from versions
6 where platform = 'Win'
7 model
8 dimension by (year)
9 measures (ver,bugs, 0 cumtot)
10 rules
11 ( cumtot[ANY]=SUM(bugs)[year <= CV(year)]
12 );
YEAR VER BUGS CUMTOT
---------- ------------ ---------- ----------
1995 Windows95 100 100
1998 Windows98 130 230
2000 WindowsME 170 400
2002 WindowsXP 140 540
142](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-142-320.jpg)
![SQL> select year
2 ,ver
3 ,bugs
4 ,wt
5 from versions
6 where platform = 'Win'
7 model
8 dimension by (year)
9 measures (ver,bugs, 0 wt)
10 rules
11 ( wt[ANY]=bugs[CV()]*
12 row_number() over ( order by year )
13 );
YEAR VER BUGS WT
---------- ------------ ---------- ----------
1995 Windows95 100 100
1998 Windows98 130 260
2000 WindowsME 170 510
2002 WindowsXP 140 560
143](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-143-320.jpg)

![SQL> select year
2 ,ver
3 ,bugs
4 from versions
5 where platform = 'Win'
6 model
7 dimension by (year)
8 measures (ver,bugs)
9 rules automatic order
10 ( bugs[2000]=150,
11 bugs[ANY]=bugs[CV()]*1.1
12 )
13 /
bugs[ANY]=bugs[CV()]*1.1
*
ERROR at line 11:
ORA-32630: multiple assignment in automatic
order MODEL
145](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-145-320.jpg)
![SQL> select year
2 ,ver
3 ,bugs
4 from versions
5 where platform = 'Win'
6 model
7 dimension by (year)
8 measures (ver,bugs)
9 rules sequential order
10 ( bugs[2000]=150,
11 bugs[ANY]=bugs[CV()]*1.1
12 )
13 /
YEAR VER BUGS
---------- --------------- ----------
1995 Windows95 110
1998 Windows98 143
2000 WindowsME 165
2002 WindowsXP 154
146](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-146-320.jpg)
![SQL> select year
2 ,ver
3 ,bugs
4 from versions
5 where platform = 'Win'
6 model
7 dimension by (year)
8 measures (ver,bugs)
9 rules sequential order
10 ( bugs[ANY]=bugs[CV()]*1.1,
11 bugs[2000]=150
12 )
13 /
YEAR VER BUGS
---------- --------------- ----------
1995 Windows95 110
1998 Windows98 143
2000 WindowsME 150
2002 WindowsXP 154
110
143
165
154
147](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-147-320.jpg)

![SQL> select year
2 ,ver
3 ,bugs
4 from versions
5 where platform = 'Win'
6 model return updated rows
7 dimension by (year)
8 measures (ver,bugs)
9 rules
10 ( ver[2009]='Windows7',
11 bugs[2009]=150
12 )
13 /
YEAR VER BUGS
---------- --------------- ----------
2009 Windows7 150
149](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-149-320.jpg)

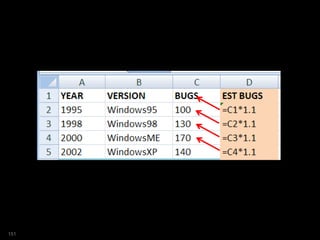
![SQL> select year
2 ,ver
3 ,bugs
4 ,est_bugs
5 from versions
6 where platform = 'Win'
7 model
8 dimension by (year)
9 measures (ver,bugs, 0 est_bugs)
10 rules
11 ( est_bugs[ANY]=bugs[CV()-1]*1.1
12 )
13 /
YEAR VER BUGS EST_BUGS
---------- --------------- ---------- ----------
1995 Windows95 100
1998 Windows98 130
2000 WindowsME 170
2002 WindowsXP 140
est_bugs[1995]=bugs[1994]
est_bugs[1998]=bugs[1997]
est_bugs[2000]=bugs[1999]
est_bugs[2002]=bugs[2001]
152](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-152-320.jpg)

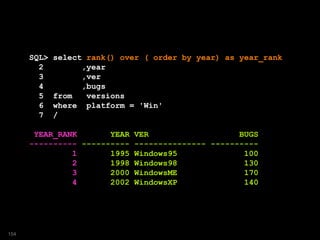
![SQL> select year_rank,year
2 ,ver,bugs,est_bugs
3 from versions
4 where platform = 'Win'
5 model
6 dimension by (
7 rank() over ( order by year) as year_rank)
8 measures (ver,bugs,year,0 est_bugs)
9 rules
10 ( est_bugs[1]=bugs[1],
11 est_bugs[year_rank > 1]=bugs[CV()-1]*1.1
12 );
YEAR_RANK YEAR VER BUGS EST_BUGS
---------- ---------- --------------- ---------- ----------
1 1995 Windows95 100 100
2 1998 Windows98 130 110
3 2000 WindowsME 170 143
4 2002 WindowsXP 140 187
155](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-155-320.jpg)

![SQL> select year_rank,year
2 ,ver,bugs,est_bugs
3 from versions
4 where platform = 'Win'
5 model
6 dimension by (
7 rank() over ( order by year) as year_rank)
8 measures (ver,bugs,year,0 est_bugs)
9 rules
10 ( est_bugs[1]=bugs[1],
11 est_bugs[year_rank > 1]=bugs[CV()-1]*1.1
12 );
YEAR_RANK YEAR VER BUGS EST_BUGS
---------- ---------- --------------- ---------- ----------
1 1995 Windows95 100 100
2 1998 Windows98 130 110
3 2000 WindowsME 170 143
4 2002 WindowsXP 140 187
159](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-159-320.jpg)
![SQL> select year_rank,year
2 ,ver,bugs,est_bugs
3 from versions
4 where platform = 'Win'
5 model
6 dimension by (
7 rank() over ( order by year) as year_rank)
8 measures (ver,bugs,year,0 est_bugs)
9 rules
10 ( est_bugs[ANY]=bugs[CV()-1]*1.1
11 );
YEAR_RANK YEAR VER BUGS EST_BUGS
---------- ---------- --------------- ---------- ----------
1 1995 Windows95 100
2 1998 Windows98 130 110
3 2000 WindowsME 170 143
4 2002 WindowsXP 140 187
160](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-160-320.jpg)

![SQL> select year_rank,year
2 ,ver,bugs,est_bugs
3 from versions
4 where platform = 'Win'
5 model IGNORE NAV
6 dimension by (
7 rank() over ( order by year) as year_rank)
8 measures (ver,bugs,year,0 est_bugs)
9 rules
10 ( est_bugs[ANY]=bugs[CV()-1]*1.1
11 );
YEAR_RANK YEAR VER BUGS EST_BUGS
---------- ---------- --------------- ---------- ----------
1 1995 Windows95 100 0
2 1998 Windows98 130 110
3 2000 WindowsME 170 143
4 2002 WindowsXP 140 187
162](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-162-320.jpg)
![SQL> select *
2 from dual
3 where 1=0
4 model ignore nav
5 dimension by (0 tag)
6 measures (to_date(null) d,
7 to_number(null) n,
8 cast(null as varchar2(10)) v)
9 rules
10 ( d[0] = d[1],
11 n[0] = n[1],
12 v[0] = v[1]
13 );
TAG D N V
---------- ------------------- ---------- ------
0 01/01/2000 00:00:00 0
dimension 1 does not exist
beware documentation !
163](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-163-320.jpg)

![SQL> select year_rank,year
2 ,ver,bugs,cum_bugs
3 from versions
4 where platform = 'Win'
5 model
6 dimension by (
7 rank() over ( order by year) as year_rank)
8 measures (ver,bugs,year,to_number(null) cum_bugs)
9 rules
10 ( cum_bugs[ANY]=cum_bugs[CV()-1]+bugs[CV()-1]
11 );
YEAR_RANK YEAR VER BUGS CUM_BUGS
---------- ---------- --------------- ---------- ----------
1 1995 Windows95 100
2 1998 Windows98 130
3 2000 WindowsME 170
4 2002 WindowsXP 140
165](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-165-320.jpg)
![SQL> select year_rank,year
2 ,ver,bugs,cum_bugs
3 from versions
4 where platform = 'Win'
5 model IGNORE NAV
6 dimension by (
7 rank() over ( order by year) as year_rank)
8 measures (ver,bugs,year,to_number(null) cum_bugs)
9 rules
10 ( cum_bugs[ANY]=cum_bugs[CV()-1]+bugs[CV()-1]
11 );
YEAR_RANK YEAR VER BUGS EST_BUGS
---------- ---------- --------------- ---------- ----------
1 1995 Windows95 100 0
2 1998 Windows98 130 100
3 2000 WindowsME 170 230
4 2002 WindowsXP 140 400
166](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-166-320.jpg)

![SQL> select ...
6 from versions
7 where platform = 'Win'
8 model
9 dimension by (rank() over ( order by year) as year_rank)
10 measures (ver,bugs,year,bugs est_bugs)
11 rules
12 (
13 est_bugs[ANY]=est_bugs[CV()-1]*1.1
14 );
YEAR_RANK YEAR VER BUGS EST_BUGS
---------- ---------- ------------ ---------- ----------
1 1995 Windows95 100
2 1998 Windows98 130
3 2000 WindowsME 170
4 2002 WindowsXP 140
168](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-168-320.jpg)
![SQL> select ...
6 from versions
7 where platform = 'Win'
8 model
9 dimension by (rank() over ( order by year) as year_rank)
10 measures (ver,bugs,year,bugs est_bugs)
11 rules
12 (
13 est_bugs[ANY] order by year_rank desc =
14 est_bugs[CV()-1]*1.1
15 );
YEAR_RANK YEAR VER BUGS EST_BUGS
---------- ---------- ------------ ---------- ----------
1 1995 Windows95 100
2 1998 Windows98 130 110
3 2000 WindowsME 170 143
4 2002 WindowsXP 140 187
169](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-169-320.jpg)

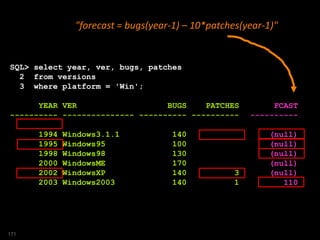
![SQL> select year, ver, patches, fcast, pv, pnv
2 from versions
3 where platform = 'Win'
4 model
5 dimension by ( year )
6 measures (ver, bugs, 0 fcast, patches, 'X' pv, 'X' pnv)
7 rules
8 (
9 fcast[ANY]=bugs[CV()]-10*patches[CV()-1],
10 pv[ANY]=PRESENTV( patches[CV()-1], 'Y','N'),
11 pnv[ANY]=PRESENTNNV( patches[CV()-1], 'Y','N')
12 );
YEAR VER PATCHES FCAST PV PNV
---------- --------------- ---------- ---------- ---- ----
1994 Windows3.1.1 N N
1995 Windows95 Y N
1998 Windows98 N N
2000 WindowsME N N
2002 WindowsXP 3 N N
2003 Windows2003 1 110 Y Y
172](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-172-320.jpg)



![SQL> select year, ver, bugs, bugs5yr
2 from versions
3 where platform = 'Win'
4 model
5 dimension by ( year )
6 measures (ver, bugs, bugs bugs5yr)
7 rules ITERATE(5)
8 (
9 bugs5yr[ANY]=bugs5yr[CV()] * 0.96
10 );
YEAR VER BUGS BUGS5YR
---------- --------------- ---------- -------
1995 Windows95 100 81.54
1998 Windows98 130 106.00
2000 WindowsME 170 138.61
2002 WindowsXP 140 114.15
176](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-176-320.jpg)


![SQL> select num
2 from dual
3 model
4 dimension by ( 0 x)
5 measures ( 0 num)
6 rules iterate (20)
7 (
8 num[ITERATION_NUMBER]=ITERATION_NUMBER
9 );
NUM
----------
0
1
2
3
4
...
17
18
19
20 rows selected.
starts from zero
179](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-179-320.jpg)


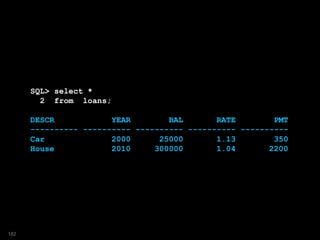
![SQL> select descr, bal final_bal, yrs
2 from loans
3 model
4 partition by ( year)
5 dimension by (0 idx)
6 measures (descr, bal, rate, pmt, 0 yrs)
7 rules iterate (50) until bal[0]*rate[0]-12*pmt[0]<0
8 (
9 bal[0]=bal[0]*rate[0]-12*pmt[0]
10 ,yrs[0]=iteration_number
11 );
DESCR FINAL_BAL YRS
---------- ----------- ----------
House 11660.34 14
Car 632.33 11
183](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-183-320.jpg)


![SQL> select year, bal, apprec, yrs
2 from loans
3 where descr = 'House'
4 model
5 partition by ( year )
6 dimension by ( 0 idx)
7 measures ( year y, bal, 12*pmt mort, apprec, 0 yrs)
8 rules iterate (20)
9 until bal[0]- previous( bal[0] ) > mort[0]
10 (
11 bal[0]=bal[0]*(1+apprec[0]/100),
12 yrs[0]=iteration_number+1
13 );
YEAR BAL APPREC YRS
---------- ---------- --------- ----------
2010 437742.689 6.5 6
186](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-186-320.jpg)

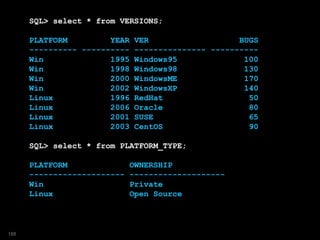
![SQL> select year, ver, bugs, est_bugs, own_ship
2 from versions
3 model
4 reference pt on
5 ( select platform p, ownership own
6 from platform_type )
7 dimension by (p)
8 measures (own)
9 dimension by (year)
10 measures (ver,bugs, 0 est_bugs,
11 platform, cast(null as varchar2(20)) own_ship)
12 rules
13 ( est_bugs[1995]=bugs[1995],
14 est_bugs[year > 1995]=bugs[cv()]*1.1,
15 own_ship[any]=pt.own[platform[cv()]]
16 );
YEAR VER BUGS EST_BUGS OWN_SHIP
---------- --------------- ---------- ---------- -----------
1995 Windows95 100 100 Private
1998 Windows98 130 143 Private
2000 WindowsME 170 187 Private
2002 WindowsXP 140 154 Private
1996 RedHat 50 55 Open Source
2006 Oracle 80 88 Open Source
2001 SUSE 65 71.5 Open Source
2003 CentOS 90 99 Open Source189](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-189-320.jpg)



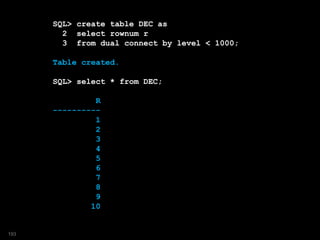
![SQL> select r, ltrim(str,'0')
2 from DEC
3 model
4 dimension by (r)
5 measures (
6 cast('' as varchar2(64)) str,
7 r as runtot,
8 power(2,32) as chk)
9 rules iterate(33)
10 ( str[ANY] =
11 str[CV()] ||
12 case
13 when bitand(runtot[CV()],chk[CV()]) > 0
14 then '1' else '0'
15 end,
16 runtot[ANY] =
17 runtot[CV()] -
18 bitand(runtot[CV()],chk[CV()]),
19 chk[ANY] = chk[CV()] / 2
20 );
194](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-194-320.jpg)


![select r, ltrim(str,'0')
from DEC
model
partition by (r)
dimension by (1 blah)
measures (
cast('' as varchar2(64)) str,
r as runtot,
power(2,32) as chk)
rules iterate(33)
( str[1] =
str[1] ||
case
when bitand(runtot[1],chk[1]) > 0
then '1' else '0'
end,
runtot[1] =
runtot[1] -
bitand(runtot[1],chk[1]),
chk[1] = chk[1] / 2
);
197](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-197-320.jpg)

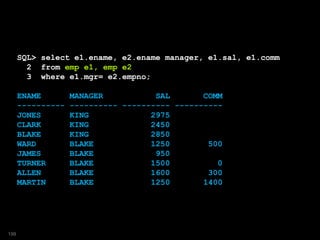
![SQL> select ename, manager, sal, comm
2 from emp
3 model
4 dimension by (empno)
5 measures (ename, mgr, sal, comm,
6 cast (null as varchar2(10)) as manager)
7 rules (
8 manager[any] = ename[mgr[cv()]]
9 );
ENAME MANAGER SAL COMM
---------- ---------- ---------- ----------
KING ALLEN 5000
BLAKE KING 2850
CLARK KING 2450
JONES KING 2975
MARTIN BLAKE 1250 1400
ALLEN BLAKE 1600 300
...
200](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-200-320.jpg)

![SQL> select deptno, ltrim(str,',') str
2 from emp
3 model return updated rows
4 partition by (deptno)
5 dimension by (
6 rank() over ( partition by deptno order by empno) x )
7 measures ( ename, cast('' as varchar2(4000)) str)
8 rules iterate (20)
9 until presentv(ename[iteration_number+1],1,2)=2
10 (
11 str[1] = str[1] || ','|| ename[iteration_number+1]
12 );
DEPTNO STR
---------- -------------------------------------------------
20 SMITH,JONES,SCOTT,ADAMS,FORD,
10 CLARK,KING,MILLER,
30 ALLEN,WARD,MARTIN,BLAKE,TURNER,JAMES,
202](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-202-320.jpg)

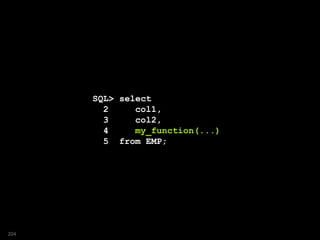



![SELECT c, p, m, pp, ip FROM MORTGAGE
MODEL
REFERENCE R ON
(SELECT customer, fact, amt FROM mortgage_facts
MODEL DIMENSION BY (customer, fact) MEASURES (amount amt)
RULES
(amt[any, 'PaymentAmt']= (amt[CV(),'Loan']*
Power(1+ (amt[CV(),'Annual_Interest']/100/12),
amt[CV(),'Payments']) *
(amt[CV(),'Annual_Interest']/100/12)) /
(Power(1+(amt[CV(),'Annual_Interest']/100/12),
amt[CV(),'Payments']) - 1)))
DIMENSION BY (customer cust, fact) measures (amt)
MAIN amortization
PARTITION BY (customer c)
DIMENSION BY (0 p)
MEASURES (principalp pp, interestp ip, mort_balance m, customer mc)
RULES
ITERATE(1000) UNTIL (ITERATION_NUMBER+1 =r.amt[mc[0],'Payments'])
(ip[ITERATION_NUMBER+1] = m[CV()-1] *
r.amt[mc[0], 'Annual_Interest']/1200,
pp[ITERATION_NUMBER+1] = r.amt[mc[0], 'PaymentAmt'] - ip[CV()],
m[ITERATION_NUMBER+1] = m[CV()-1] - pp[CV()] )
208](https://image.slidesharecdn.com/model-181005070520/85/The-SQL-Model-Clause-208-320.jpg)









The document discusses the use of SQL for modeling data, particularly focusing on incorporating calculations and dimensions similar to Excel functionalities. It provides numerous SQL query examples demonstrating how to create measures, define rules, and handle idiosyncrasies in relational data queries. The emphasis is on the flexibility of SQL capabilities while comparing its advantages with traditional tools like Excel.

























![Wk. 3. Data [12-05-2021] (2).ppt](https://cdn.slidesharecdn.com/ss_thumbnails/wk-240205070901-8f81e253-thumbnail.jpg?width=640&height=640&fit=bounds)









































