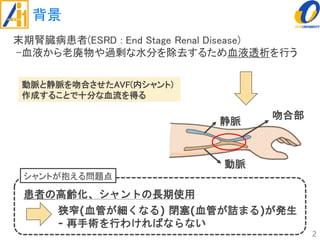
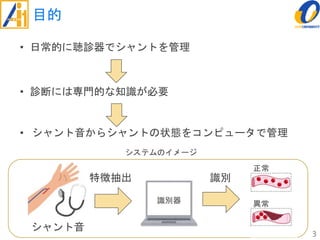
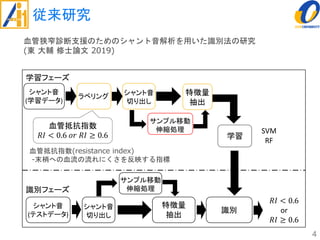
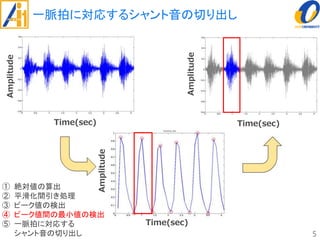
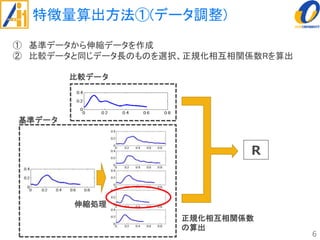
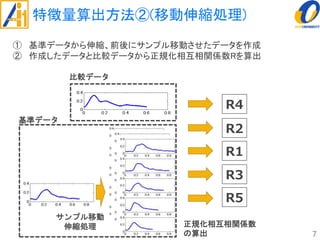
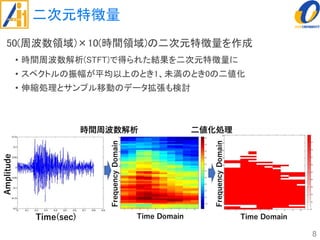
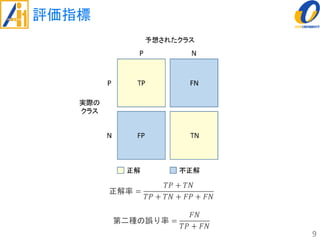
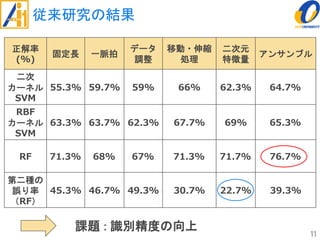
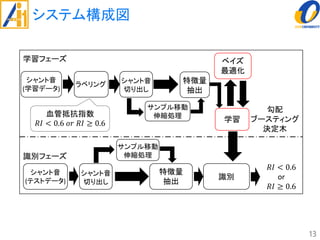
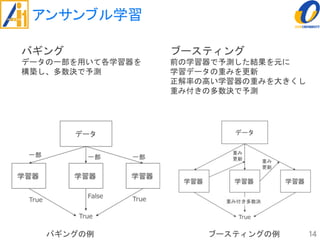
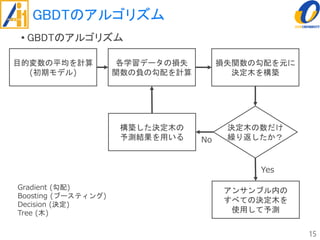
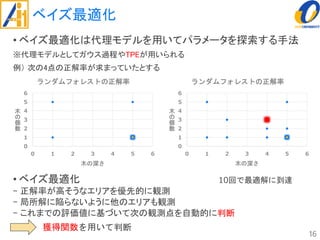
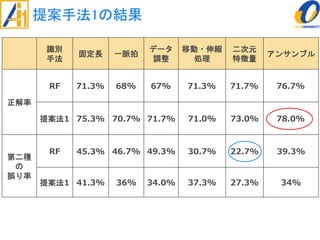
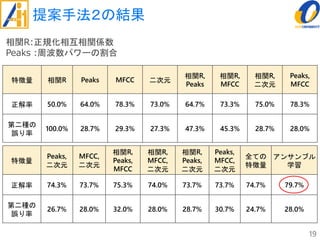
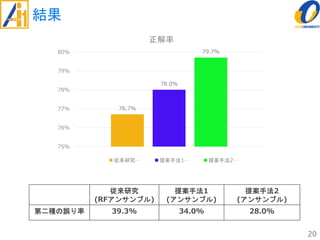
The document describes a study on improving the accuracy of detecting blood vessel stenosis using phonocardiograms. The study proposes using gradient boosting decision trees instead of random forests for classification, and exploring different combinations of four frequency-domain features extracted from phonocardiograms. Experiments show the proposed method achieves higher accuracy rates and lower false negative rates than previous methods, demonstrating its effectiveness in identifying normal and abnormal blood vessels from heart sound data.






















![[DL輪読会]Memory-Augmented Attribute Manipulation Networks for Interactive Fashi...](https://cdn.slidesharecdn.com/ss_thumbnails/goto20170616-170712031459-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Envir...](https://cdn.slidesharecdn.com/ss_thumbnails/20201023voxelposekuboshizuma-201023025841-thumbnail.jpg?width=640&height=640&fit=bounds)




















