Download to read offline


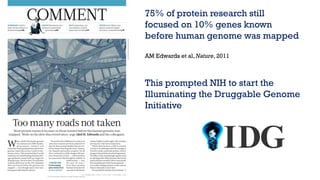



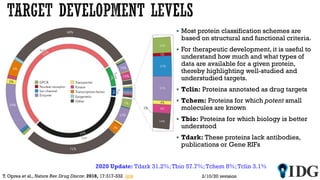
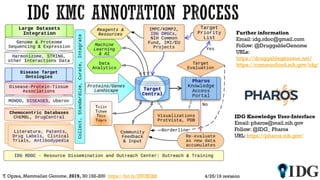
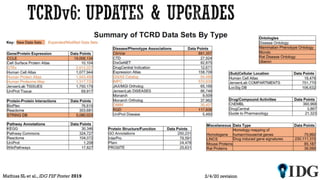


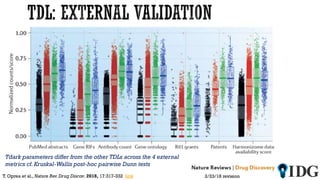


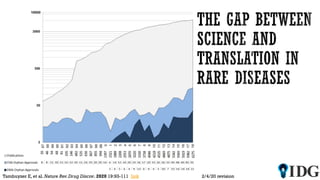
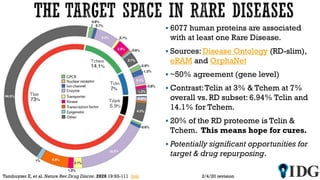



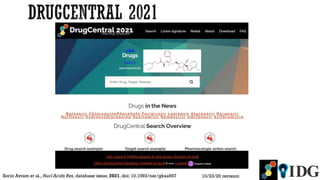
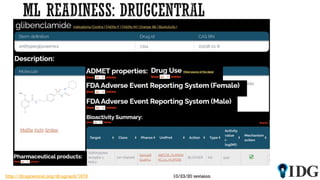

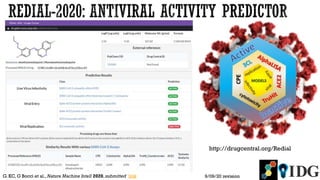
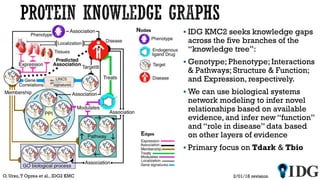

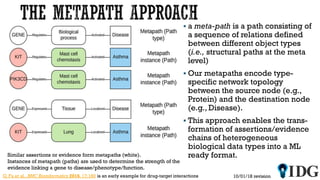
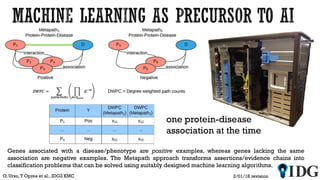
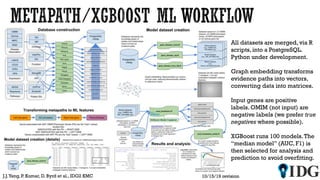

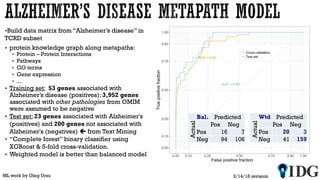

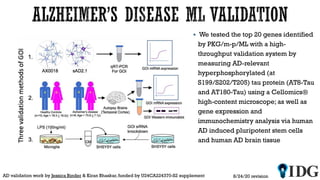
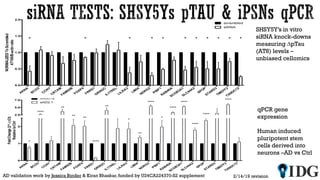
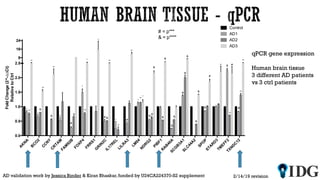
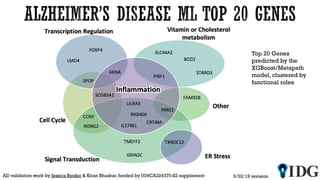










The document discusses the Illuminating the Druggable Genome initiative, which aims to enhance protein-targeting research through informatics, data science, and machine learning. It highlights the classification of proteins associated with drug targets, detailing the available data for various protein categories and the significance of understanding under-studied proteins in therapeutic development. Additionally, the document emphasizes the potential of machine learning in prioritizing clinically relevant protein-disease associations and the aggregation of diverse biological data to inform drug development.






































































![ANIMAL_CELL_,_TISSUE_AND_ORGAN_CULTURE[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/animalcelltissueandorganculture1-260204172026-4462b440-thumbnail.jpg?width=640&height=640&fit=bounds)
















