가상의 그분의 대사
유저 로그 데이터도 전부 모으고 있고,
하둡 클러스터도 다 구축 했습니다.
이제 빅데이터로 뭐 그럴듯 한 거 하기만 하면 됩니다.
-어떤 데이터 팀 팀장
http://www.resumeexamplesweb.com/images/combination-resume.jpg
3.
가상의 그분의 대사
유저 로그 데이터도 전부 모으고 있고,
하둡 클러스터도 다 구축 했습니다.
이제 빅데이터로 뭐 그럴듯 한 거 하기만 하면 됩니다.
-어떤 데이터 팀 팀장
본 발표는 공개되어있는링크드인의 연구/발표자료등을 토대로 만들어졌습니다.
하지만 발표에서 제시되는 의견들은 저 개인의 것이며, 링크드인의 공식적인 입장과는 상이할 수 있습니다.
6.
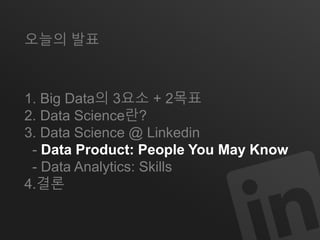
오늘의 발표
1.Big Data의 3요소 + 2목표
2. Data Science란?
3. Data Science @ Linkedin
- Data Product: People You May Know
- Data Analytics: Skills
4.결론
7.
빅데이터의 정의
인터넷을사용하는 사람들에 의해 발생하는 굉장히 큰 데이터 셋을 지칭하며
특별한 툴과 방법론을 이용해서만 저장,이해 및 사용 될 수 있다
– 캠브리지 사전
8.
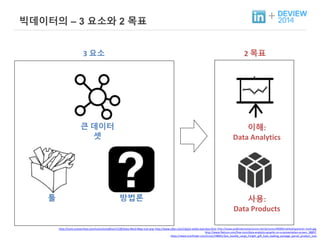
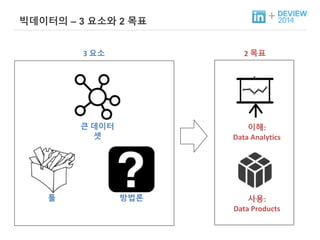
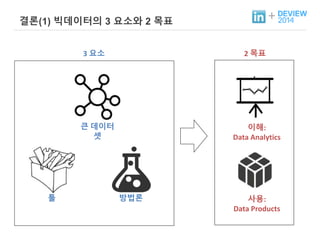
+ 빅데이터의 –3 요소와 2 목표
툴
3 요소 2 목표
큰 데이터
셋
이해:
Data Analytics
방법론 사용:
Data Products
http://icons.iconarchive.com/icons/icons8/ios7/128/Data-Mind-Map-icon.png, http://www.clker.com/clipart-white-tool-box.html, http://www.publicdomainpictures.net/pictures/40000/nahled/question-mark.jpg,
http://www.flaticon.com/free-icon/data-analytics-graphic-on-a-presentation-screen_38897,
https://www.iconfinder.com/icons/198841/box_bundle_cargo_freight_gift_load_loading_package_parcel_product_icon
9.
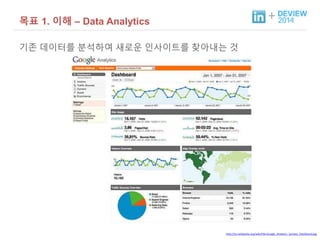
+ 목표 1.이해 – Data Analytics
기존 데이터를 분석하여 새로운 인사이트를 찾아내는 것
http://en.wikipedia.org/wiki/File:Google_Analytics_Sample_Dashboard.jpg
10.
+ 목표 2.사용 – Data Product
추천, 검색, 개인화 등 사용자에게 보여지는 제품에 데이터를 기반으로
한 알고리즘이 깊이 녹아들어가 있는 제품.
데이터를 통해 유저의 만족을 극대화하는 것이 목표.
11.
+ 요소 1.굉장히 큰 데이터 set
인류문명이 시작된 이래 2003년까지 만들어진 데이터양은 통틀어
5엑사바이트에 불과했습니다. 지금은 이틀마다 그만큼씩의 데이터가 새로
추가되고 있으며, 이 속도는 점점 빨라지고 있습니다. –에릭 슈미트, Technomy
2010
기회&도전
http://en.wikipedia.org/wiki/File:Google_Analytics_Sample_Dashboard.jpg
오늘의 발표
1.Big Data의 3요소 + 2목표
2. Data Science란?
3. Data Science @ Linkedin
- Data Product: People You May Know
- Data Analytics: Skills
4.결론
19.
+ 데이터 사이언스란?
데이터
사이언스
방법론
hhttp://www.iconpng.com/icon/58699
20.
+ 데이터 사이언스란?
Data Science 는 데이터로부터 일반화 가능한 지식을 추출하는
학문으로써, 키워드는 “Science”이다. Data Science는 signal
processing, mathematics, probability models, machine learning,
statistical learning, computer programming, data engineering, pattern
recognition and learning, visualization, uncertainty modeling, data
warehousing, and high performance computing 등 다양한 분야의
학문을 접목시켜서, 데이터로부터 의미를 추출하거나 데이터
프로덕트를 만드는 것을 목표로 한다. …
-en.wikipedia.org, “data science”
21.
+ 데이터 사이언스란?
http://www.jumpgate.io/assets/img/datascience.jpg
22.
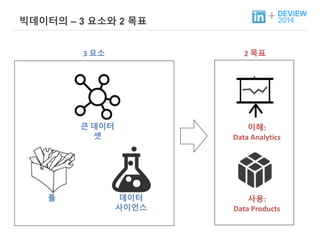
+ 빅데이터의 –3 요소와 2 목표
툴
3 요소 2 목표
큰 데이터
셋
이해:
Data Analytics
방법론 사용:
Data Products
23.
+ 빅데이터의 –3 요소와 2 목표
툴
3 요소 2 목표
큰 데이터
셋
이해:
Data Analytics
사용:
Data Products
데이터
사이언스
24.
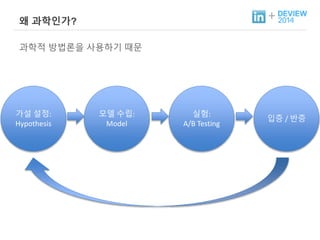
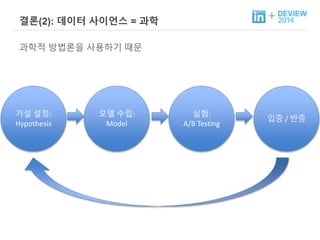
+ 왜 과학인가?
과학적 방법론을 사용하기 때문
가설 설정:
Hypothesis
모델 수립:
Model
실험:
A/B Testing
입증 / 반증
25.
+ 과학적 방법론:가설 설정 / 모델 수립
유저의 행동을 잘 설명할 수 있는 가설을 설정:
한국인일수록 LOL 실력이 좋다?
코딩을 한 기간이 길수록 연봉이 높다?
가설을 바탕으로 수학적 모델을 수립:
P(LOL 플래티넘 랭크) = 0.5 + if(한국인 == true) 0.2, else -0.2
연봉 = 평균 연봉 * (1 + (코딩 한 년수 / 100년))
26.
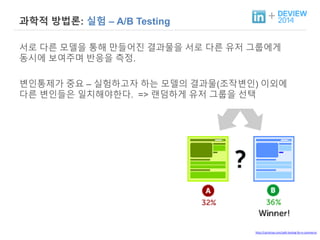
+ 과학적 방법론:실험 – A/B Testing
서로 다른 모델을 통해 만들어진 결과물을 서로 다른 유저 그룹에게
동시에 보여주며 반응을 측정.
변인통제가 중요 – 실험하고자 하는 모델의 결과물(조작변인) 이외에
다른 변인들은 일치해야한다. => 랜덤하게 유저 그룹을 선택
http://cartytrax.com/split-testing-for-e-commerce
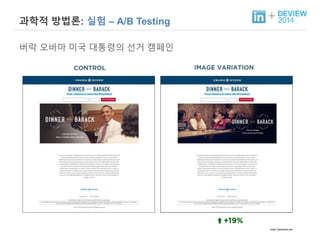
+ 과학적 방법론:실험 – A/B Testing
A/B/C/D/E/F …… Testing?
야후의 CEO 마리사 메이어는 구글 재직 시절 여러가지로 유명하지만,
“40 shades of blue” 는 그녀의 성향을 특히 더 잘 설명합니다. Google
Mail 과 Google page에서 보여지는 파란색을 결정하기 위해서, 그녀는
서로 다른 음영의 40가지의 파란색이 각각 2.5%의 사용자에게 보여지게
하였습니다.가장 많은 클릭을 받은 파란색이 여러분들이 오늘날 Google
과 Google Mail에서 보는 파란색입니다. - http://www.theguardian.com/
http://commons.wikimedia.org/wiki/File:Color_gradient_map_(blue)_palette.png
29.
+ 과학적 방법론:입증/반증
입증된 모델의 경우:
가설을 받아들임 and 데이터 프로덕트에 적용
반증된 모델의 경우:
가설/모델/실험 단계에서 잘못된 점을 검토
30.
오늘의 발표
1.Big Data의 3요소 + 2목표
2. Data Science란?
3. Data Science @ Linkedin
- Data Product: People You May Know
- Data Analytics: Skills
4.결론
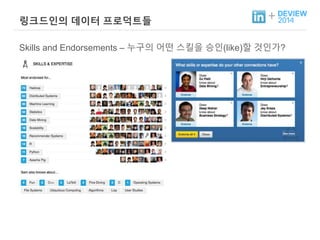
+ 링크드인의 데이터프로덕트들
Skills and Endorsements – 누구의 어떤 스킬을 승인(like)할 것인가?
34.
+ 링크드인의 데이터프로덕트들
Jobs You May be Interested In – 어떤 새 직장에 관심이 있을 것인가?
News Recommendation – 어떤 뉴스를 읽고 싶은가?
Feed – 유저가 관심가질만한 정보로 이루어진 메인 페이지
35.
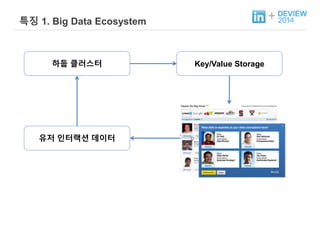
+ 특징 1.Big Data Ecosystem
하둡 클러스터 Key/Value Storage
유저 인터랙션 데이터
36.
+ 특징 2.오픈소스의 활용
Apache Hadoop: 분산 처리 시스템
Apache Kafka: 분산 메세징 시스템
Azkaban: 웹 기반 하둡 scheduler
Voldemort: Key/Value Storage
Apache Pig: 하둡 쿼리 언어
DataFu: 피그용 UDF 모음
37.
+ 특징 3.Encapsulation
시스템에 대해 잘 모르는 데이터 사이언티스트가 Recommendation
Algorithm을 만들고 싶다면?
Analytics/Modeling Layer
R, Linkedin’s Azkaban(Hadoop workflow management),
Apache Pig, LinkedIn’s DataFu
Infrastructure Layer
Hadoop, LinkedIn’s Voldemort(Key/Value storage)
데이터 모델링, 분석 레벨의 지식과
인프라스트럭쳐 레벨의 지식이 분리됨.
38.
오늘의 발표
1.Big Data의 3요소 + 2목표
2. Data Science란?
3. Data Science @ Linkedin
- Data Product: People You May Know
- Data Analytics: Skills
4.결론
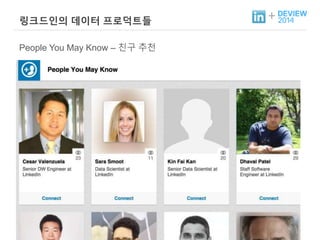
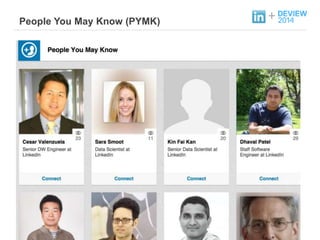
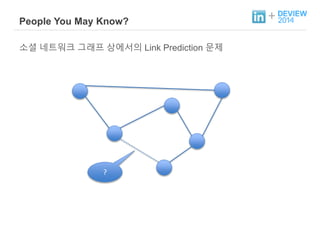
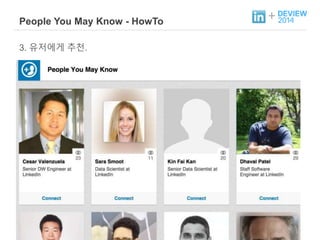
+ People YouMay Know?
소셜 네트워크 그래프 상에서의 Link Prediction 문제
?
41.
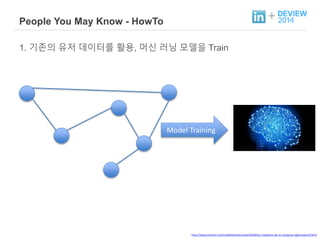
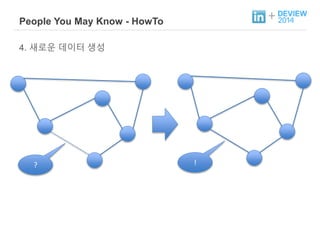
+ People YouMay Know - HowTo
1. 기존의 유저 데이터를 활용, 머신 러닝 모델을 Train
Model Training
http://www.vorterix.com/malditosnerds/notas/4918/los-creadores-de-siri-preparan-algo-especial.html
42.
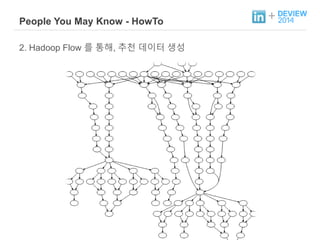
+ People YouMay Know - HowTo
2. Hadoop Flow 를 통해, 추천 데이터 생성
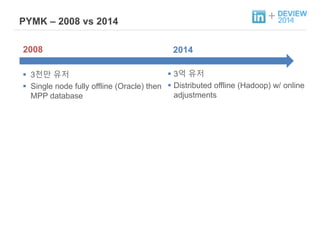
+ PYMK –2008 vs 2014
2008 2014
3천만 유저
Single node fully offline (Oracle) then
MPP database
3억 유저
Distributed offline (Hadoop) w/ online
adjustments
46.
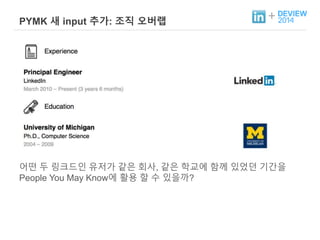
+ PYMK 새input 추가: 조직 오버랩
어떤 두 링크드인 유저가 같은 회사, 같은 학교에 함께 있었던 기간을
People You May Know에 활용 할 수 있을까?
Can we compute edge affinity based on organizational overlap?
47.
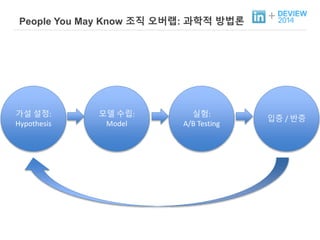
+ People YouMay Know 조직 오버랩: 과학적 방법론
가설 설정:
Hypothesis
모델 수립:
Model
실험:
A/B Testing
입증 / 반증
48.
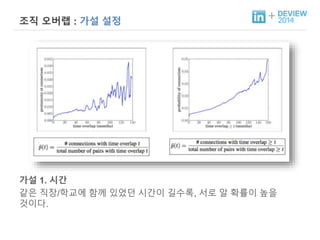
+ 조직 오버랩: 가설 설정
가설 1. 시간
같은 직장/학교에 함께 있었던 시간이 길수록, 서로 알 확률이 높을
것이다.
49.
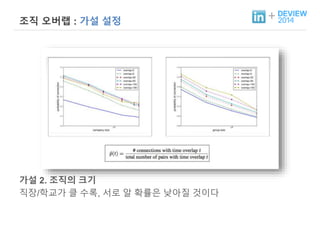
+ 조직 오버랩: 가설 설정
가설 2. 조직의 크기
직장/학교가 클 수록, 서로 알 확률은 낮아질 것이다
50.
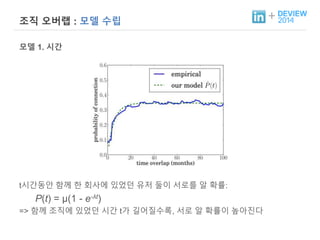
+ 조직 오버랩: 모델 수립
모델 1. 시간
t시간동안 함께 한 회사에 있었던 유저 둘이 서로를 알 확률:
P(t) = μ(1 - e-λt)
=> 함께 조직에 있었던 시간 t가 길어질수록, 서로 알 확률이 높아진다
51.
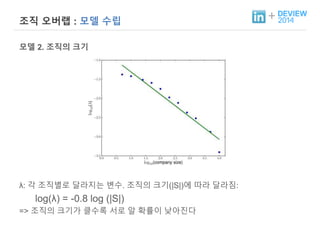
+ 조직 오버랩: 모델 수립
모델 2. 조직의 크기
λ: 각 조직별로 달라지는 변수. 조직의 크기(|S|)에 따라 달라짐:
log(λ) = -0.8 log (|S|)
=> 조직의 크기가 클수록 서로 알 확률이 낮아진다
52.
+ 조직 오버랩: 실험
A/B Testing
기존 모델 vs. 조직 오버랩을 활용한 모델
어떤 모델이 유저들에게 더 반응이 좋은가?
A 그룹: 기존
모델
B 그룹: 기존 모델 + 조직 오버랩
More Clicks!
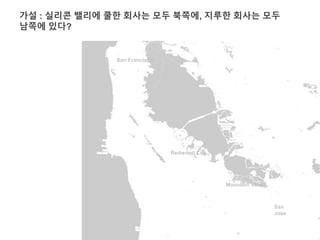
가설 : 실리콘밸리에 쿨한 회사는 모두 북쪽에, 지루한 회사는 모두
남쪽에 있다?
San Francisco
Mountain View
San
Jose
Redwood City
57.
가설 : 실리콘밸리에 쿨한 회사는 모두 북쪽에, 지루한 회사는 모두
남쪽에 있다?
San Francisco
Mountain View
San
Jose
Redwood City
58.
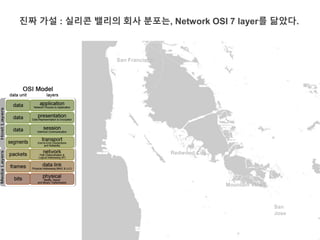
진짜 가설 :실리콘 밸리의 회사 분포는, Network OSI 7 layer를 닮았다.
San Francisco
Mountain View
San
Jose
Redwood City
59.
모델 수립 /실험
1.실리콘 밸리를 남~북 순으로 네개의 지역으로 나눔
2.각 지역별로 IT회사들을 정리
3.회사 직원들의 링크드인 프로필상 스킬을 모음
4.각 지역별로 가장 빈번히 보이는 스킬들은, 북쪽 지역일수록
Application layer, 남쪽 지역일수록 Physical layer의 스킬 일 것이다.
60.
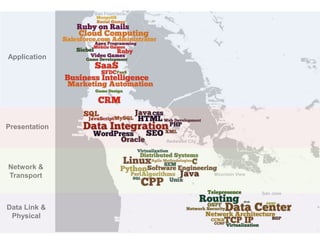
San Francisco
SanJose
Redwood City
Mountain View
Application
Presentation
Network &
Transport
Data Link &
Physical
61.
오늘의 발표
1.Big Data의 3요소 + 2목표
2. Data Science란?
3. Data Science @ Linkedin
- Data Product: People You May Know
- Data Analytics: Skills
4.결론
62.
가상의 그분의 대사- Before
유저 로그 데이터도 전부 모으고 있고,
하둡 클러스터도 다 구축 했습니다.
이제 빅데이터로 뭐 그럴듯 한 거 하기만 하면 됩니다.
-어떤 데이터 팀 팀장
63.
가상의 그분의 대사- After
유저 로그 데이터도 전부 모으고 있고,
하둡 클러스터도 다 구축 했습니다.
이제 데이터에 대한 가설을 설정하고 이를 입/반증하는 과정을 통해서,
로그 데이터 분석을 통해 사용자에 대한 이해도를 높이고
사용자들에게 더 좋은 반응을 이끌어 낼 수 있는 데이터 프로덕트를
만들고자 합니다.
-어떤 데이터 팀 팀장
64.
가상의 그분의 대사- After
유저 로그 데이터도 전부 모으고 있고,
하둡 클러스터도 다 구축 했습니다.
이제 데이터에 대한 가설을 설정하고 이를 입/반증하는 과정을 통해서,
로그 데이터 분석을 통해 사용자에 대한 이해도를 높이고
사용자들에게 더 좋은 반응을 이끌어 낼 수 있는 데이터 프로덕트를
만들고자 합니다.
-어떤 데이터 팀 팀장
65.
+ 결론(1) 빅데이터의3 요소와 2 목표
툴
3 요소 2 목표
큰 데이터
셋
이해:
Data Analytics
사용:
Data Products
방법론
66.
+ 결론(2): 데이터사이언스 = 과학
과학적 방법론을 사용하기 때문
가설 설정:
Hypothesis
모델 수립:
Model
실험:
A/B Testing
입증 / 반증
#3 Imaginary conversation: I’m collecting user log data, I finished setting up hadoop cluster. Now I just want to do “something interesting” with big data
#4 Imaginary conversation: I’m collecting user log data, I finished setting up hadoop cluster. Now I just want to do “something interesting” with big data
#5 How can u do “something interesting” with big data?
#6 Disclaimer: This presentation is based on public research/presentations of LinkedIn. However, opinions presented here is mine, and can be differ from official stance of Linkedin.
2:05
#8 Definition of Big Data
Very large sets of data that are produced by people using the internet, and that can only be stored, understood, and used with the help of special tools and methods
– Cambridge Dictionary
#9 3 elements of big data
각각의 요소에 대해 자세히 말할 필요는 없음(다음슬라이드들에서 할것이기 때문에)
#15 Imaginary conversation: I’m collecting user log data, I finished setting up hadoop cluster. Now I just want to do “something interesting” with big data
#16 Imaginary conversation: I’m collecting user log data, I finished setting up hadoop cluster. Now I just want to do “something interesting” with big data
#17 How can u do “something interesting” with big data?
#63 Imaginary conversation: I’m collecting user log data, I finished setting up hadoop cluster. Now I just want to do “something interesting” with big data
#64 Imaginary conversation: I’m collecting user log data, I finished setting up hadoop cluster. Now I just want to do “something interesting” with big data
#65 Imaginary conversation: I’m collecting user log data, I finished setting up hadoop cluster. Now I just want to do “something interesting” with big data
#66 3 elements of big data
각각의 요소에 대해 자세히 말할 필요는 없음(다음슬라이드들에서 할것이기 때문에)



































![[2A6]web & health 2.0. 회사에서의 data science란?](https://cdn.slidesharecdn.com/ss_thumbnails/2a6webhealth2-140930011255-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[FAST CAMPUS] 1강 data science overview](https://cdn.slidesharecdn.com/ss_thumbnails/1datascienceoverviewprint-141124210725-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)







![[코세나, kosena] 빅데이터 구축 및 제안 가이드](https://cdn.slidesharecdn.com/ss_thumbnails/random-161220075637-thumbnail.jpg?width=640&height=640&fit=bounds)







































![[WTM18] 커리어에 데이터사이언스 더하기](https://cdn.slidesharecdn.com/ss_thumbnails/wtm18datascience-180409193139-thumbnail.jpg?width=640&height=640&fit=bounds)




![[2018] 효율적인 데이터 관리를 위한 플랫폼 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/machinebigdata06-190212052349-thumbnail.jpg?width=640&height=640&fit=bounds)

![[211] 인공지능이 인공지능 챗봇을 만든다](https://cdn.slidesharecdn.com/ss_thumbnails/211chatbot-181106094835-thumbnail.jpg?width=640&height=640&fit=bounds)
![[233] 대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing: Maglev Hashing Scheduler i...](https://cdn.slidesharecdn.com/ss_thumbnails/233networkloadbalancing-181018151852-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215] Druid로 쉽고 빠르게 데이터 분석하기](https://cdn.slidesharecdn.com/ss_thumbnails/215druid-181012071910-thumbnail.jpg?width=640&height=640&fit=bounds)
![[245]Papago Internals: 모델분석과 응용기술 개발](https://cdn.slidesharecdn.com/ss_thumbnails/245papagointernals1-181012045005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[236] 스트림 저장소 최적화 이야기: 아파치 드루이드로부터 얻은 교훈](https://cdn.slidesharecdn.com/ss_thumbnails/236deview2018jihoonson-final-181012031726-thumbnail.jpg?width=640&height=640&fit=bounds)
![[235]Wikipedia-scale Q&A](https://cdn.slidesharecdn.com/ss_thumbnails/235deview2018julienperezwikipediaqa12oct2018-181012030613-thumbnail.jpg?width=640&height=640&fit=bounds)
![[244]로봇이 현실 세계에 대해 학습하도록 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/244deview2018tomisilanderrobotsrealworldfinal11oct2018-181012024720-thumbnail.jpg?width=640&height=640&fit=bounds)
![[243] Deep Learning to help student’s Deep Learning](https://cdn.slidesharecdn.com/ss_thumbnails/243deeplearningtohelpstudentsdeeplearning-181012024530-thumbnail.jpg?width=640&height=640&fit=bounds)
![[234]Fast & Accurate Data Annotation Pipeline for AI applications](https://cdn.slidesharecdn.com/ss_thumbnails/234fastaccuratedataannotationpipelineforaiapplications1-181012024230-thumbnail.jpg?width=640&height=640&fit=bounds)
![Old version: [233]대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing](https://cdn.slidesharecdn.com/ss_thumbnails/233largecontainerclusternetworkloadbalancing-181012024225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[226]NAVER 광고 deep click prediction: 모델링부터 서빙까지](https://cdn.slidesharecdn.com/ss_thumbnails/226naveraddeepclickprediction-181012024116-thumbnail.jpg?width=640&height=640&fit=bounds)
![[225]NSML: 머신러닝 플랫폼 서비스하기 & 모델 튜닝 자동화하기](https://cdn.slidesharecdn.com/ss_thumbnails/225nsmlmachinelearningntuningautomize-181012023407-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224]네이버 검색과 개인화](https://cdn.slidesharecdn.com/ss_thumbnails/224naversearchnpersonalizationfinal-181012022631-thumbnail.jpg?width=640&height=640&fit=bounds)
![[216]Search Reliability Engineering (부제: 지진에도 흔들리지 않는 네이버 검색시스템)](https://cdn.slidesharecdn.com/ss_thumbnails/216sresearchreliabilityengineering-181012022623-thumbnail.jpg?width=640&height=640&fit=bounds)
![[214] Ai Serving Platform: 하루 수 억 건의 인퍼런스를 처리하기 위한 고군분투기](https://cdn.slidesharecdn.com/ss_thumbnails/214aiservingplatforminference-181012022603-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213] Fashion Visual Search](https://cdn.slidesharecdn.com/ss_thumbnails/213fashionvisualsearchreduced-181012022540-thumbnail.jpg?width=640&height=640&fit=bounds)
![[232] TensorRT를 활용한 딥러닝 Inference 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/232dlinferenceoptimizationusingtensorrt1-181012014455-thumbnail.jpg?width=640&height=640&fit=bounds)
![[242]컴퓨터 비전을 이용한 실내 지도 자동 업데이트 방법: 딥러닝을 통한 POI 변화 탐지](https://cdn.slidesharecdn.com/ss_thumbnails/242pcdpublic-181012011734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212]C3, 데이터 처리에서 서빙까지 가능한 하둡 클러스터](https://cdn.slidesharecdn.com/ss_thumbnails/212c3-181012011644-thumbnail.jpg?width=640&height=640&fit=bounds)
![[223]기계독해 QA: 검색인가, NLP인가?](https://cdn.slidesharecdn.com/ss_thumbnails/2232018-181012010149-thumbnail.jpg?width=640&height=640&fit=bounds)