Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
DaeMyung Kang
3,635 views
Bloomfilter
BloomFilter, space-efficient probabilistic data structure
Technology
◦
Read more
30
Save
Share
Embed
Embed presentation
Download
Downloaded 33 times
1
/ 35
2
/ 35
3
/ 35
4
/ 35
5
/ 35
6
/ 35
7
/ 35
8
/ 35
9
/ 35
10
/ 35
11
/ 35
12
/ 35
13
/ 35
14
/ 35
15
/ 35
16
/ 35
17
/ 35
18
/ 35
19
/ 35
20
/ 35
21
/ 35
22
/ 35
23
/ 35
24
/ 35
25
/ 35
26
/ 35
27
/ 35
28
/ 35
29
/ 35
30
/ 35
31
/ 35
32
/ 35
33
/ 35
34
/ 35
35
/ 35
More Related Content
PPTX
Postgres Playground で pgbench を走らせよう!(第35回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PPTX
Telemetry事始め
by
npsg
PDF
pg_bigm(ピージー・バイグラム)を用いた全文検索のしくみ(後編)
by
Masahiko Sawada
PPTX
PySparkによるジョブを、より速く、よりスケーラブルに実行するための最善の方法 ※講演は翻訳資料にて行います。 - Getting the Best...
by
Holden Karau
PPTX
これぞ最強!? Windows Virtual Desktop の使い方
by
Takashi Ushigami
PDF
並列クエリを実行するPostgreSQLのアーキテクチャ
by
Kohei KaiGai
PDF
System Performance Analysis
by
Adrien Mahieux
PDF
SQL Server パフォーマンスカウンター
by
Masayuki Ozawa
Postgres Playground で pgbench を走らせよう!(第35回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
Telemetry事始め
by
npsg
pg_bigm(ピージー・バイグラム)を用いた全文検索のしくみ(後編)
by
Masahiko Sawada
PySparkによるジョブを、より速く、よりスケーラブルに実行するための最善の方法 ※講演は翻訳資料にて行います。 - Getting the Best...
by
Holden Karau
これぞ最強!? Windows Virtual Desktop の使い方
by
Takashi Ushigami
並列クエリを実行するPostgreSQLのアーキテクチャ
by
Kohei KaiGai
System Performance Analysis
by
Adrien Mahieux
SQL Server パフォーマンスカウンター
by
Masayuki Ozawa
What's hot
PDF
pg_trgmと全文検索
by
NTT DATA OSS Professional Services
PDF
Part 2: Data & AI 基盤 (製造リファレンス・アーキテクチャ勉強会)
by
Takeshi Fukuhara
PDF
Memoizeの仕組み(第41回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PPTX
Amazon Redshiftの開発者がこれだけは知っておきたい10のTIPS / 第18回 AWS User Group - Japan
by
Koichi Fujikawa
PPTX
Apache Bigtopによるオープンなビッグデータ処理基盤の構築(オープンデベロッパーズカンファレンス 2021 Online 発表資料)
by
NTT DATA Technology & Innovation
PDF
ChatGPTのデータソースにPostgreSQLを使う(第42回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
PDF
[D31] PostgreSQLでスケールアウト構成を構築しよう by Yugo Nagata
by
Insight Technology, Inc.
PDF
JSONBはPostgreSQL9.5でいかに改善されたのか
by
NTT DATA OSS Professional Services
PPTX
パケット キャプチャで学ぶ SMB (CIFS) の基本
by
彰 村地
PDF
Grafana Lokiの Docker Logging Driver入門 (Docker Meetup Tokyo #34, 2020/01/16)
by
NTT DATA Technology & Innovation
PDF
PGOを用いたPostgreSQL on Kubernetes入門(PostgreSQL Conference Japan 2022 発表資料)
by
NTT DATA Technology & Innovation
PPTX
Zero Data Loss Recovery Appliance 設定手順例
by
オラクルエンジニア通信
PDF
あなたの知らないPostgreSQL監視の世界
by
Yoshinori Nakanishi
PDF
まずやっとくPostgreSQLチューニング
by
Kosuke Kida
PPTX
PostgreSQL 14 モニタリング新機能紹介(PostgreSQL カンファレンス #24、2021/06/08)
by
NTT DATA Technology & Innovation
PDF
Greenplum versus redshift and actian vectorwise comparison
by
Dr. Syed Hassan Amin
PPTX
MLT_3_UNIT.pptx
by
AAKANKSHAAGRAWALPC22
PDF
IIJmio meeting 26 プライベートLTEとパブリックLTEの相互運用における問題とその解決
by
techlog (Internet Initiative Japan Inc.)
PDF
IIJmio meeting 11 HLR/HSS開放とは何か?
by
techlog (Internet Initiative Japan Inc.)
PPTX
Data and database administration(database)
by
welcometofacebook
pg_trgmと全文検索
by
NTT DATA OSS Professional Services
Part 2: Data & AI 基盤 (製造リファレンス・アーキテクチャ勉強会)
by
Takeshi Fukuhara
Memoizeの仕組み(第41回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
Amazon Redshiftの開発者がこれだけは知っておきたい10のTIPS / 第18回 AWS User Group - Japan
by
Koichi Fujikawa
Apache Bigtopによるオープンなビッグデータ処理基盤の構築(オープンデベロッパーズカンファレンス 2021 Online 発表資料)
by
NTT DATA Technology & Innovation
ChatGPTのデータソースにPostgreSQLを使う(第42回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
[D31] PostgreSQLでスケールアウト構成を構築しよう by Yugo Nagata
by
Insight Technology, Inc.
JSONBはPostgreSQL9.5でいかに改善されたのか
by
NTT DATA OSS Professional Services
パケット キャプチャで学ぶ SMB (CIFS) の基本
by
彰 村地
Grafana Lokiの Docker Logging Driver入門 (Docker Meetup Tokyo #34, 2020/01/16)
by
NTT DATA Technology & Innovation
PGOを用いたPostgreSQL on Kubernetes入門(PostgreSQL Conference Japan 2022 発表資料)
by
NTT DATA Technology & Innovation
Zero Data Loss Recovery Appliance 設定手順例
by
オラクルエンジニア通信
あなたの知らないPostgreSQL監視の世界
by
Yoshinori Nakanishi
まずやっとくPostgreSQLチューニング
by
Kosuke Kida
PostgreSQL 14 モニタリング新機能紹介(PostgreSQL カンファレンス #24、2021/06/08)
by
NTT DATA Technology & Innovation
Greenplum versus redshift and actian vectorwise comparison
by
Dr. Syed Hassan Amin
MLT_3_UNIT.pptx
by
AAKANKSHAAGRAWALPC22
IIJmio meeting 26 プライベートLTEとパブリックLTEの相互運用における問題とその解決
by
techlog (Internet Initiative Japan Inc.)
IIJmio meeting 11 HLR/HSS開放とは何か?
by
techlog (Internet Initiative Japan Inc.)
Data and database administration(database)
by
welcometofacebook
Similar to Bloomfilter
PPTX
NDC 2018 억! 소리나는 게임 서비스 플랫폼을 지탱하는 알고리즘 - 해시, 불변데이터, 확률적 자료구조
by
Isaac Jeon
PPTX
코딩테스트 합격자 되기 2주차 스터디 - 리스트_딕셔너리
by
ultrasuperrok
PPTX
[데브루키]노대영_알고리즘 스터디
by
대영 노
PDF
BlOOM FILTER의 이해와 활용방법_Wh oracle
by
엑셈
PDF
redis 소개자료 - 네오클로바
by
NeoClova
PDF
Oracle B*tree
by
Jongwon
PDF
[추천] 색인기법 김성현
by
Young-jun Jeong
PDF
자료구조 06 최종 보고서
by
pkok15
PDF
프로젝트#6 (오탈자 검사)보고서
by
mil23
PDF
Project#6 오탈자 검사 D0 Hwp
by
Kimjeongmoo
PDF
자료구조6보고서
by
KimChangHoen
PPTX
DBMS 아키텍처
by
HaksunLEE6
PPTX
Amugona study 1회 jjw
by
정완 전
PPTX
Amugona study 1회 jjw
by
정완 전
PDF
InfiniFlux vs RDBMS
by
InfiniFlux Korea
PPTX
[자바카페] 람다 아키텍처, 더 깊이 살펴보기
by
용호 최
PDF
Algorithms summary korean
by
Young-Min kang
PDF
대규모서비스를지탱하는기술 7
by
HyeonSeok Choi
PDF
Graph
by
GNGLB
PDF
[D2 campus]Key-value store 만들기
by
NAVER D2
NDC 2018 억! 소리나는 게임 서비스 플랫폼을 지탱하는 알고리즘 - 해시, 불변데이터, 확률적 자료구조
by
Isaac Jeon
코딩테스트 합격자 되기 2주차 스터디 - 리스트_딕셔너리
by
ultrasuperrok
[데브루키]노대영_알고리즘 스터디
by
대영 노
BlOOM FILTER의 이해와 활용방법_Wh oracle
by
엑셈
redis 소개자료 - 네오클로바
by
NeoClova
Oracle B*tree
by
Jongwon
[추천] 색인기법 김성현
by
Young-jun Jeong
자료구조 06 최종 보고서
by
pkok15
프로젝트#6 (오탈자 검사)보고서
by
mil23
Project#6 오탈자 검사 D0 Hwp
by
Kimjeongmoo
자료구조6보고서
by
KimChangHoen
DBMS 아키텍처
by
HaksunLEE6
Amugona study 1회 jjw
by
정완 전
Amugona study 1회 jjw
by
정완 전
InfiniFlux vs RDBMS
by
InfiniFlux Korea
[자바카페] 람다 아키텍처, 더 깊이 살펴보기
by
용호 최
Algorithms summary korean
by
Young-Min kang
대규모서비스를지탱하는기술 7
by
HyeonSeok Choi
Graph
by
GNGLB
[D2 campus]Key-value store 만들기
by
NAVER D2
More from DaeMyung Kang
PPTX
The easiest consistent hashing
by
DaeMyung Kang
PDF
webservice scaling for newbie
by
DaeMyung Kang
PDF
Massive service basic
by
DaeMyung Kang
PDF
How to build massive service for advance
by
DaeMyung Kang
PPTX
Count min sketch
by
DaeMyung Kang
PPTX
Data pipeline and data lake
by
DaeMyung Kang
PPTX
Kafka timestamp offset
by
DaeMyung Kang
PDF
Scalable webservice
by
DaeMyung Kang
PDF
Redis
by
DaeMyung Kang
PDF
Data Engineering 101
by
DaeMyung Kang
PDF
Integration between Filebeat and logstash
by
DaeMyung Kang
PDF
How To Become Better Engineer
by
DaeMyung Kang
PDF
How to use redis well
by
DaeMyung Kang
PDF
Number system
by
DaeMyung Kang
PDF
Why GUID is needed
by
DaeMyung Kang
PDF
How to name a cache key
by
DaeMyung Kang
PPTX
Kafka timestamp offset_final
by
DaeMyung Kang
PDF
Ansible
by
DaeMyung Kang
PDF
Redis acl
by
DaeMyung Kang
PDF
Coffee store
by
DaeMyung Kang
The easiest consistent hashing
by
DaeMyung Kang
webservice scaling for newbie
by
DaeMyung Kang
Massive service basic
by
DaeMyung Kang
How to build massive service for advance
by
DaeMyung Kang
Count min sketch
by
DaeMyung Kang
Data pipeline and data lake
by
DaeMyung Kang
Kafka timestamp offset
by
DaeMyung Kang
Scalable webservice
by
DaeMyung Kang
Redis
by
DaeMyung Kang
Data Engineering 101
by
DaeMyung Kang
Integration between Filebeat and logstash
by
DaeMyung Kang
How To Become Better Engineer
by
DaeMyung Kang
How to use redis well
by
DaeMyung Kang
Number system
by
DaeMyung Kang
Why GUID is needed
by
DaeMyung Kang
How to name a cache key
by
DaeMyung Kang
Kafka timestamp offset_final
by
DaeMyung Kang
Ansible
by
DaeMyung Kang
Redis acl
by
DaeMyung Kang
Coffee store
by
DaeMyung Kang
Bloomfilter
1.
아주 심플한 블룸필터의
원리 강대명 (CHARSYAM@NAVER.COM)
2.
블룸필터가 뭔가요? 있다고 하면
없을 수 있지만(False Positive), 없다고 하면 정말 없는 자료구조(No False Negative)
3.
실화입니까? 있다고 해도 실제로
없을 수 있다면, 매번 있는지 확인해 야 할 것 같은데, 이런 걸 어디에 써야 하나요? HashMap 등은 contains에 있으면 반드시 있으니, 믿 고 쓸 수 있는데 말입니다.
4.
블룸필터를 쓰고 있는
것들? Cassandra Hbase Oracle(Bloom pruning of partitions for queries) Quora, FaceBook
5.
실화입니까?(2) 이런 제품들이나 회사들이
블룸필터를 쓰는 이유는 무엇 일까요?
6.
DISK와 메모리의 속도비교
L1 cache reference 0.5 ns Branch mispredict 5 ns L2 cache reference 7 ns 14x L1 cache Mutex lock/unlock 25 ns Main memory reference 100 ns 20x L2 cache, 200x L1 cache Compress 1K bytes with Zippy 3,000 ns 3 us Send 1K bytes over 1 Gbps network 10,000 ns 10 us Read 4K randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD Read 1 MB sequentially from memory 250,000 ns 250 us Round trip within same datacenter 500,000 ns 500 us Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory Disk seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip Read 1 MB sequentially from disk 20,000,000 ns 20,000 us 20 ms 80x memory, 20X SSD Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 ms
7.
메인메모리와 디스크 디스크 접근은
메모리보다 겨우 10,000배 느립니다. MEM 속도 = 디스크 * 10,000 SSD는 1,500 배 느림. MEM 속도 = SSD * 1,500 결론 디스크 접근을 줄이자.
8.
블룸필터의 필요성 실제 데이터가
있는지 정확히 알려면? 메모리가 데이터 사이즈 만큼 필요함. 데이터량이 굉장히 많다면? 블룸필터를 이용하면 메모리 사용량을 줄이면서 비슷한 효과 를 낼 수 있음.
9.
블룸필터의 필요성 블 룸 필 터 SSD/HDD Query Query Query Query exist exist exist not exist Query Query not
exist not exist exist exist not exist 실제 3번의 쿼리를 할 필요가 없음.
10.
How 블룸필터 works? 블룸필터는
bitarray 입니다. n개의 hash를 선택합니다.(crc, murmur, md5등) 보통 3개 hash(key, 0) 은 crc hash를 의미 hash(key, 1) 은 murmur hash를 의미 hash(key, 2) 은 md5 hash를 의미
11.
블룸필터 #1 bitarray의
크기는 16 hash(“charsyam”, 0) % 16 = 3 hash(“charsyam”, 1) % 16 = 5 hash(“charsyam”, 2) % 16 = 11 0 0 0 1 0 1 0 0 0 0 0 1 0 0 0 0 add(“charsyam”)
12.
블룸필터 #2 bitarray의
크기는 16 hash(“bloomfilter”, 0) % 16 = 0 hash(“bloomfilter”, 1) % 16 = 1 hash(“bloomfilter”, 2) % 16 = 15 1 1 0 1 0 1 0 0 0 0 0 1 0 0 0 1 add(“bloomfilter”)
13.
블룸필터 #3 bitarray의
크기는 16 hash(“clark”, 0) % 16 = 1 hash(“clark”, 1) % 16 = 2 hash(“clark”, 2) % 16 = 14 1 1 1 1 0 1 0 0 0 0 0 1 0 0 1 1 add(“clark”)
14.
블룸필터 #4 exists
동작, 3개의 비트가 1로 채워져 있으면 존재한다고 알림. hash(“charsyam”, 0) % 16 = 3 hash(“charsyam”, 1) % 16 = 5 hash(“charsyam”, 2) % 16 = 11 1 1 1 1 0 1 0 0 0 0 0 1 0 0 1 1 exists(“charsyam”)
15.
블룸필터 #5 exists,
False Positive, fake는 추가하지 않았지만 모든 bit가 1임 hash(“fake”, 0) % 16 = 0 hash(“fake”, 1) % 16 = 3 hash(“fake”, 2) % 16 = 15 1 1 1 1 0 1 0 0 0 0 0 1 0 0 1 1 exists(“fake”)
16.
블룸필터의 한계 #1 데이터의
삭제가 불가능하다. Hbase, Cassandra 지워지는 케이스는 없고 Compaction시에 재생성
17.
블룸필터의 한계 #2 false
positive 가 발생하는 비율을 적절히 조절해야 한다.
18.
False Positive #1 False
Positive는 당연히 발생하게 됨. k: 해시 함수 개수 m: bitarray의 크기 n: 전체 원소의 개수 당연히 m이 크고 n이 적을 수록 False Positive가 적음 그럼 k는?
19.
False Positive #2 가장
적은 False Positive를 가지는 경우
20.
False Positive #3 한번의
hash 연산으로 나온 Bit를 1로 설정 한번의 hash 연산으로 BitArray V의 어떤 값이 설정될 확률 = 1/m 반대로 어떤 값이 설정 안될 확률은 (1 – 1/m)
21.
False Positive #4 k
개의 해시 함수를 이용할 경우에 설정되지 않을 확률은 n 개의 원소가 들어가게 되면 다시 이 확률은
22.
False Positive #5 이제
다시 n개의 원소가 있을 때 특정 Bit가 1로 셋팅되어 있을 확률은 1 에서 해당 값을 빼면 됨.
23.
False Positive #6 k
개의 해시 함수가 실행되는 것과 위의 1로 설정될 확률이 독립 사건이므로…(이 부분이 이해가 안가요!!! ㅋㅋㅋ) 각각의 해시 함수가 실행될 때 마다 이 확률이라서…
24.
False Positive #7
다시 m 이 무한으로 수렴한다고 하면 그 값이 아래와 같이 되므 로…
25.
False Positive #8 즉
False Postivie가 발생할 확률은 아래의 식이 도출됨 (뭐지 이건 또 T.T)
26.
False Positive #9 다시,
가장 적은 False Positive를 가지는 경우
27.
False Positive #10 다시,
가장 적은 False Positive를 가지는 경우 k를 유지할 경우에 m, n의 변화에 따른 False Postivie 확률 p의 변화
28.
Scalable BloomFilter #1 블룸필터를
확장 가능하게 만들 수 있을까? 즉, 처음에 원소가 적을 때는 m을 작게 잡고, 윈소가 늘어나면 m을 크게 만들면 좋지 않을까? 0 0 0 1 최초 1 1 1 1 0 1 0 0 확장
29.
Scalable BloomFilter #2 기존
블룸필터의 확장은 불가능 배열의 크기가 커지면 해시에 대한 modular도 달라지면서 기 존 값들의 의미가 전부 사라짐. 그러면 새로 만들어야 함.
30.
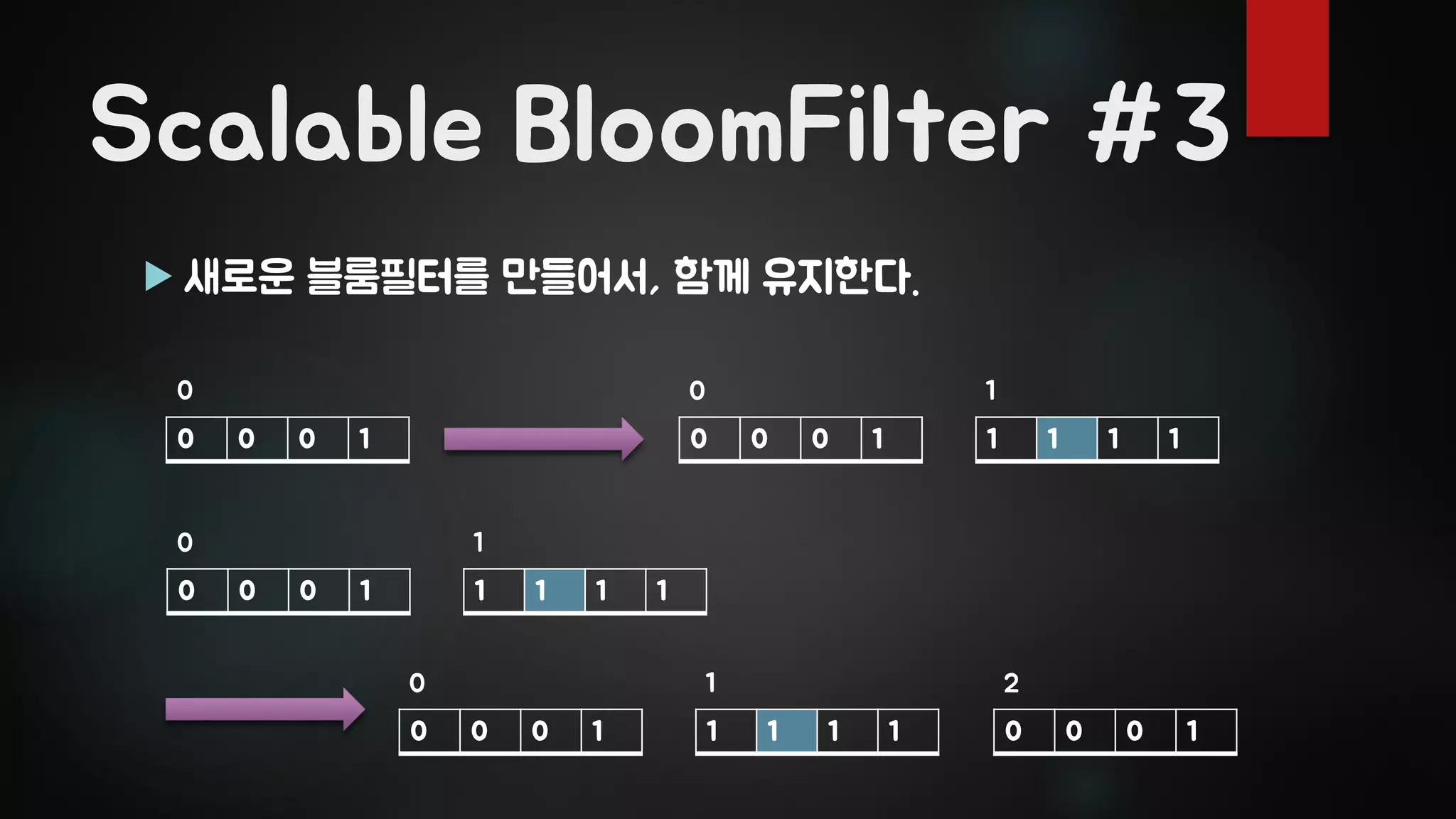
Scalable BloomFilter #3
새로운 블룸필터를 만들어서, 함께 유지한다. 0 0 0 1 0 0 0 1 1 1 1 1 0 10 0 0 0 1 1 1 1 1 0 1 0 0 0 1 1 1 1 1 0 1 0 0 0 1 2
31.
Scalable BloomFilter #4
Add 동작 입력 key가 기존 블룸필터들에 존재하는 지 확인 있으면, 리턴! 없으면, 여유 공간이 있는지 보고, 새로운 블룸필터 체인을 만들 어야 하는지 확인 맨 마지막 블룸필터에 삽입한다.
32.
Scalable BloomFilter #5
check 동작 모든 블룸필터 체인에서 검색을 해서 없어야만 없다고 알려준다.
33.
Scalable BloomFilter #6
확장시에 새 블룸필터의 사이즈는 더 늘어날 수 있다. 이에 따라 에러율도 바뀌어야 한다. ERROR_TIGHTENING_RATIO 라는 개념이 적용되는데, 이건 패스…
34.
Reference 꼭 참고하세요.
https://en.wikipedia.org/wiki/Bloom_filter http://d2.naver.com/helloworld/749531 http://gsd.di.uminho.pt/members/cbm/ps/dbloom.pdf https://github.com/RedisLabsModules/rebloom https://github.com/jaybaird/python-bloomfilter/
35.
Thank you.
Download

















































![[D31] PostgreSQLでスケールアウト構成を構築しよう by Yugo Nagata](https://cdn.slidesharecdn.com/ss_thumbnails/d31postgresnagata-131128230735-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)















![[데브루키]노대영_알고리즘 스터디](https://cdn.slidesharecdn.com/ss_thumbnails/devrookiealgorithm-180926091907-thumbnail.jpg?width=640&height=640&fit=bounds)



![[추천] 색인기법 김성현](https://cdn.slidesharecdn.com/ss_thumbnails/random-110424155234-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)








![[자바카페] 람다 아키텍처, 더 깊이 살펴보기](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatastudylabdadeepdive-190419125137-thumbnail.jpg?width=640&height=640&fit=bounds)



![[D2 campus]Key-value store 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/d2campuskeyvaluestore-150822042537-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)



















