Downloaded 42 times
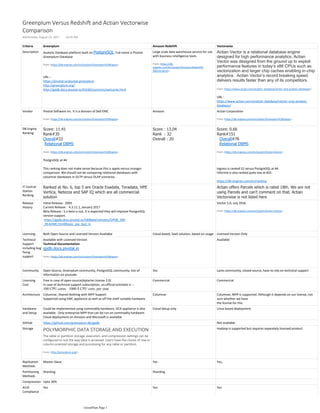
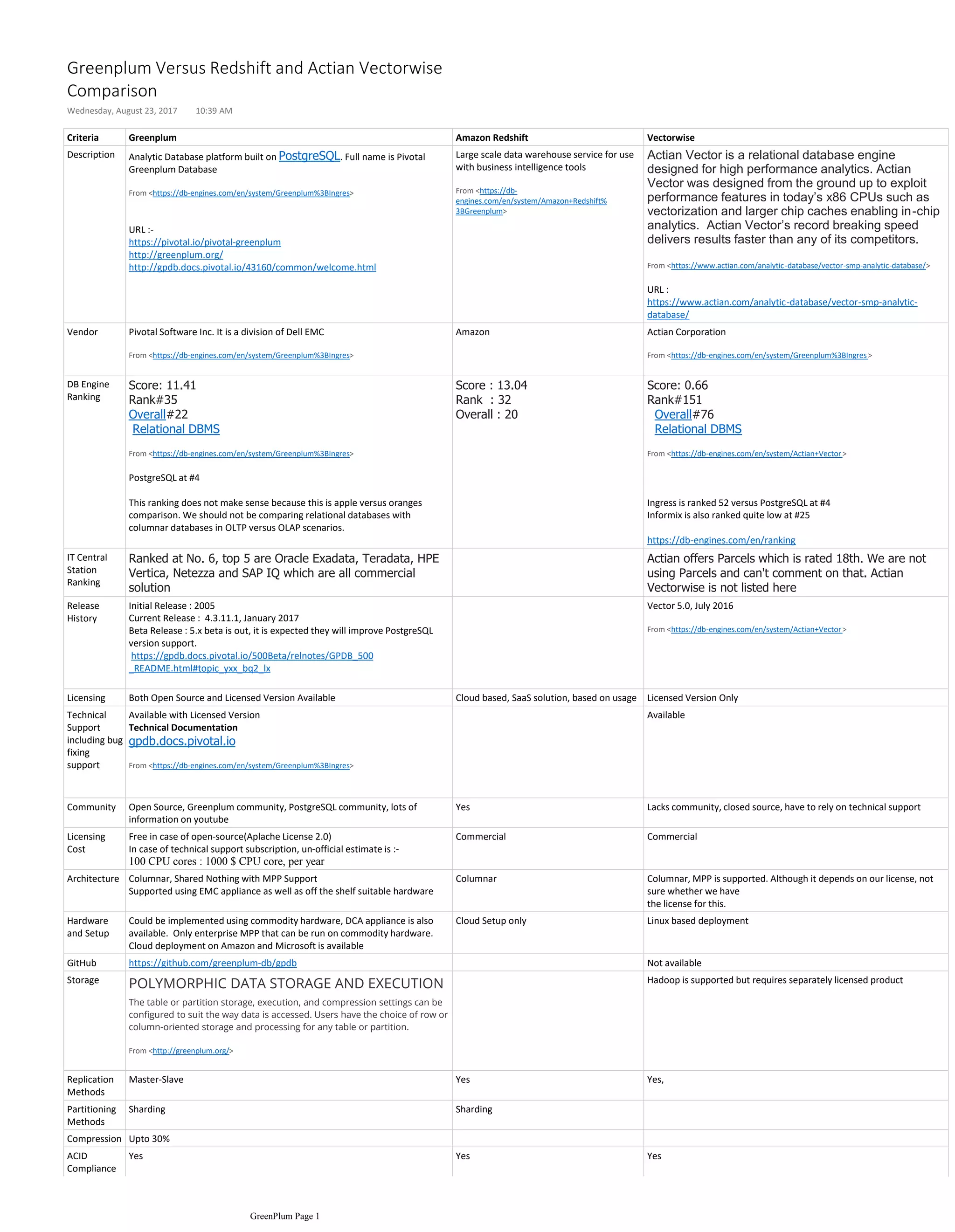
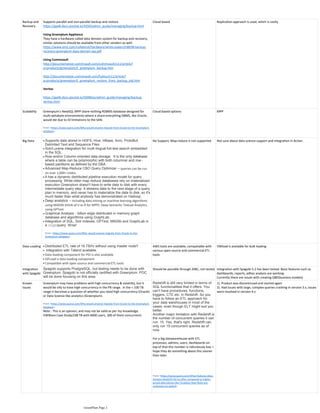




The document compares various analytic database platforms including Greenplum, Amazon Redshift, and Actian Vectorwise, highlighting their features, performance, and rankings. Greenplum provides a large-scale data warehouse solution built on PostgreSQL, emphasizing its strong data science capabilities, while Amazon Redshift offers a more limited SQL functionality with a cap on concurrent queries. Actian Vectorwise is noted for its high-performance analytics, designed for modern CPU architectures, although it lacks community support compared to the other platforms.















































































