Download as PDF, PPTX
































![{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "*",
"Resource": "*"
}
]
}
Making everyone an admin](https://image.slidesharecdn.com/cloudadoptionfails-5waysdeploymentsgowrongand5solutions-220420115410/75/Cloud-adoption-fails-5-ways-deployments-go-wrong-and-5-solutions-39-2048.jpg)

































![{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "*",
"Resource": "*"
}
]
}
To deploy arbitrary infra changes, you
need arbitrary (admin) permissions!](https://image.slidesharecdn.com/cloudadoptionfails-5waysdeploymentsgowrongand5solutions-220420115410/75/Cloud-adoption-fails-5-ways-deployments-go-wrong-and-5-solutions-79-2048.jpg)



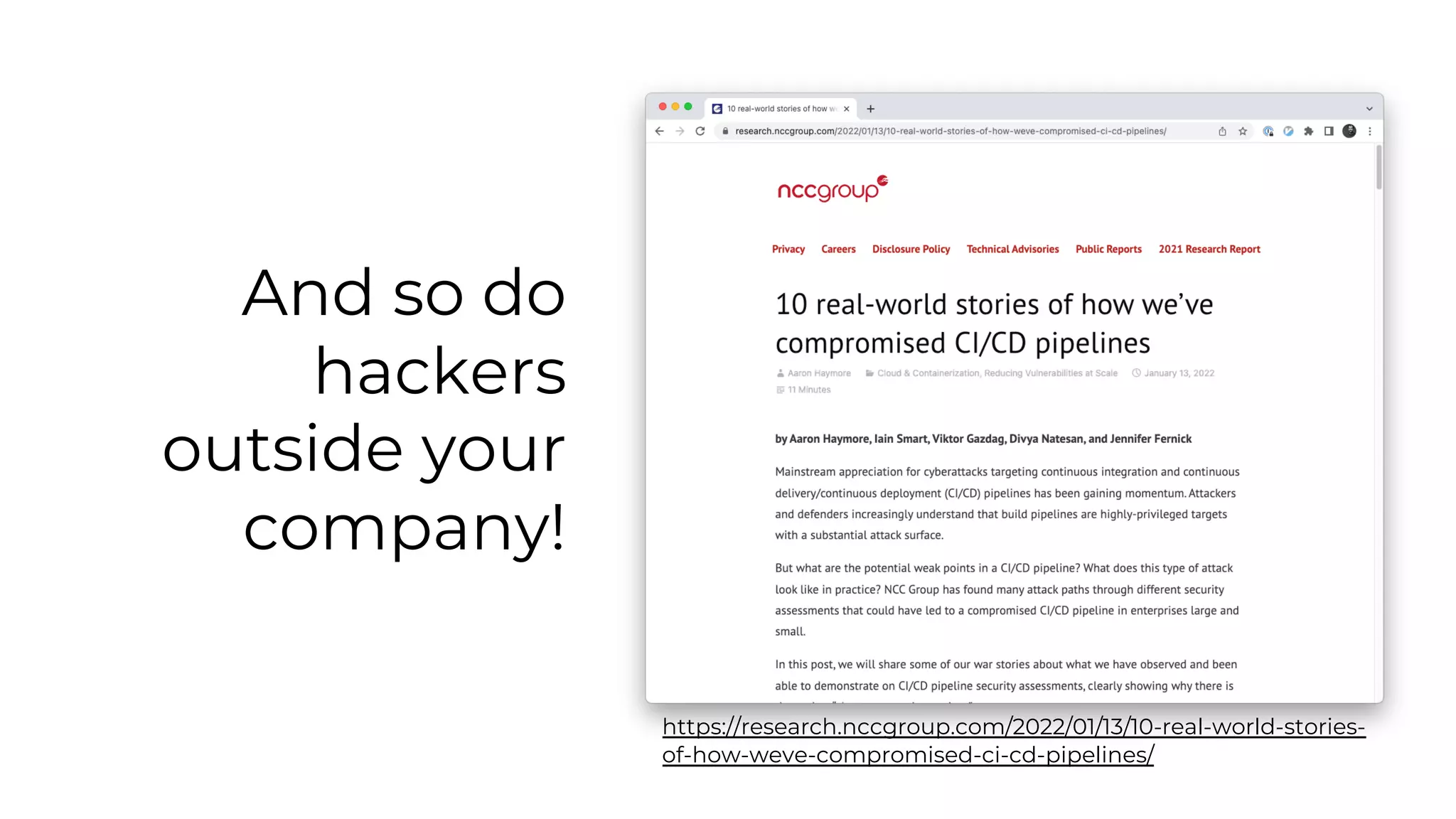
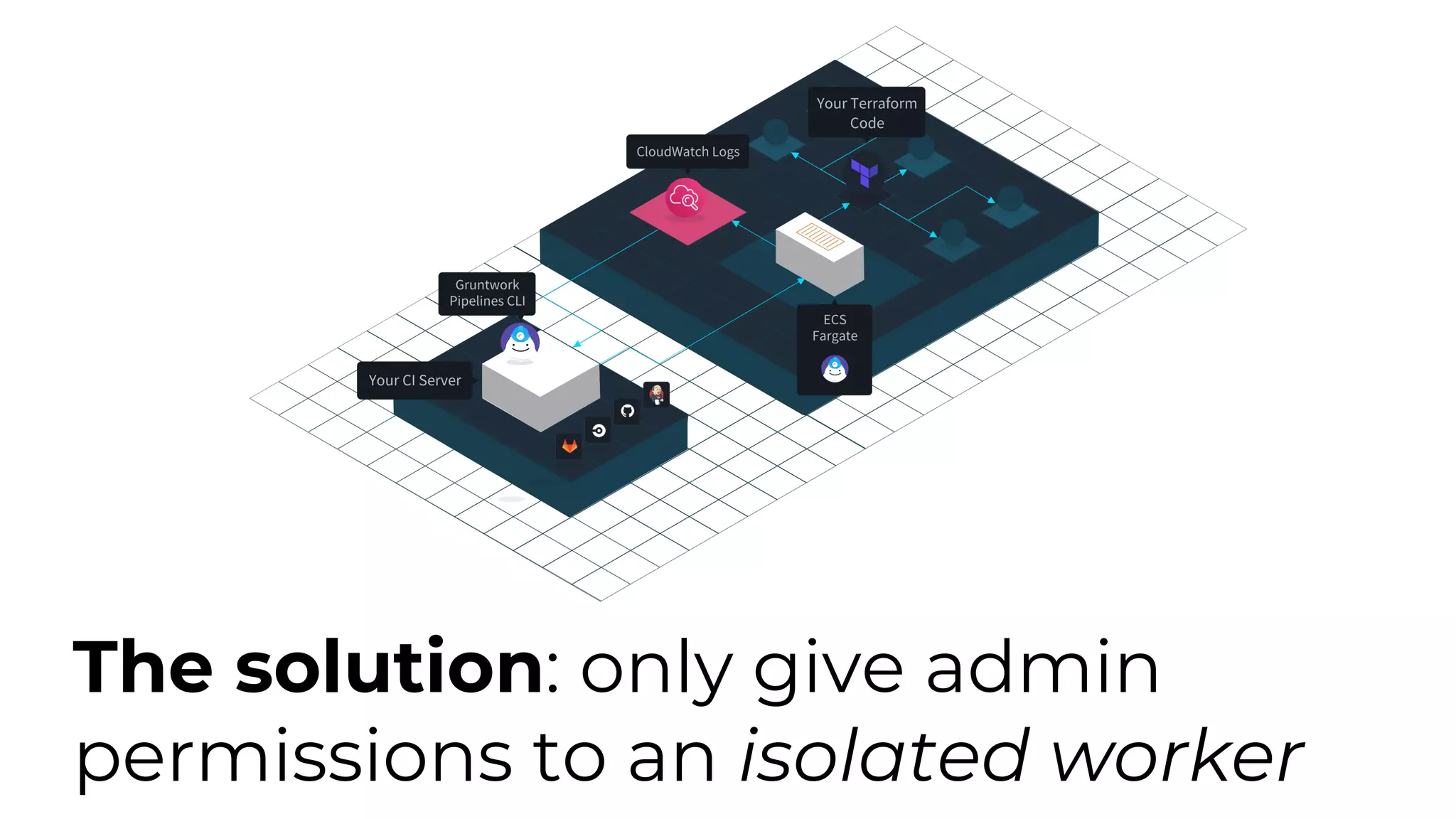












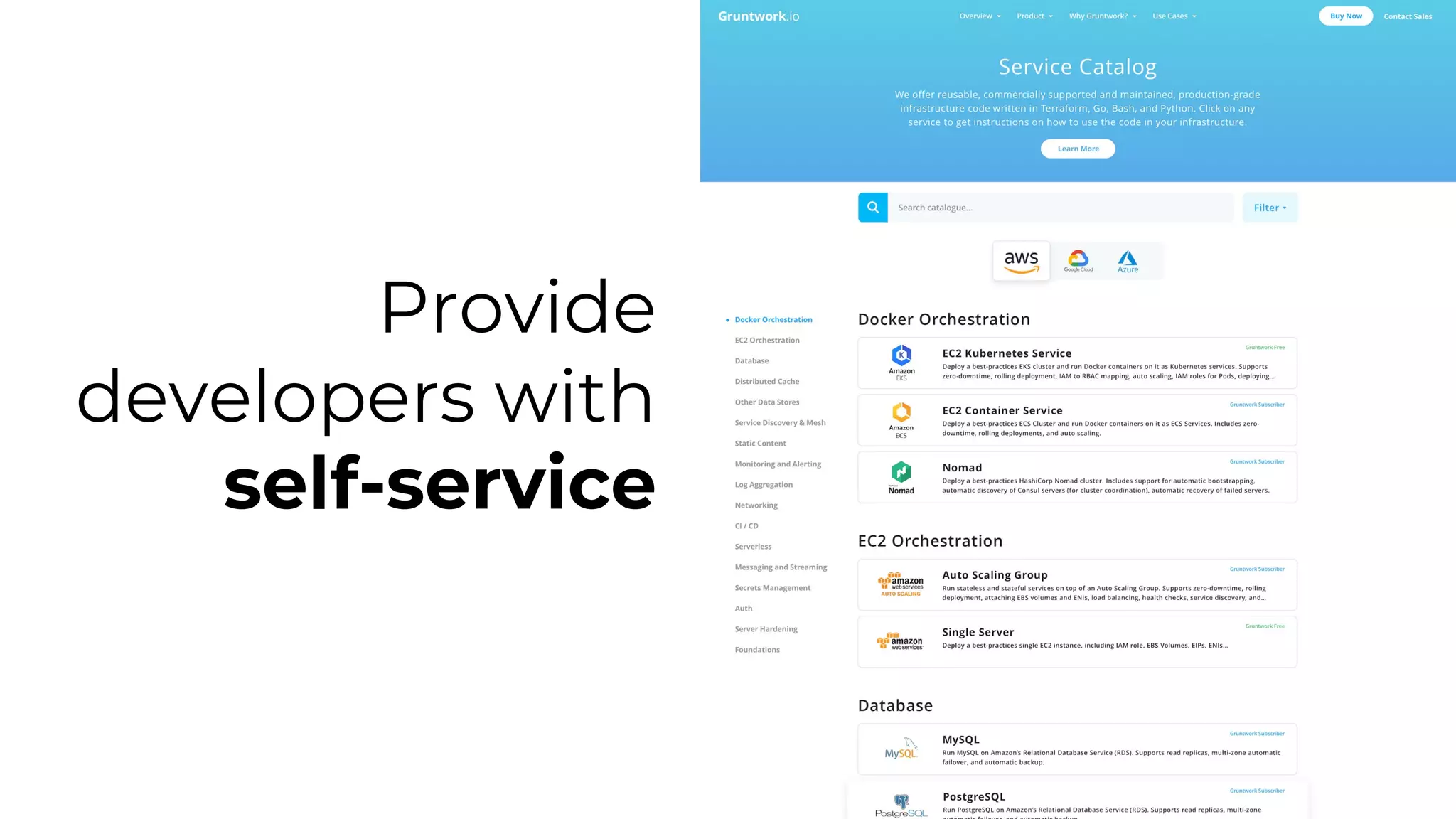












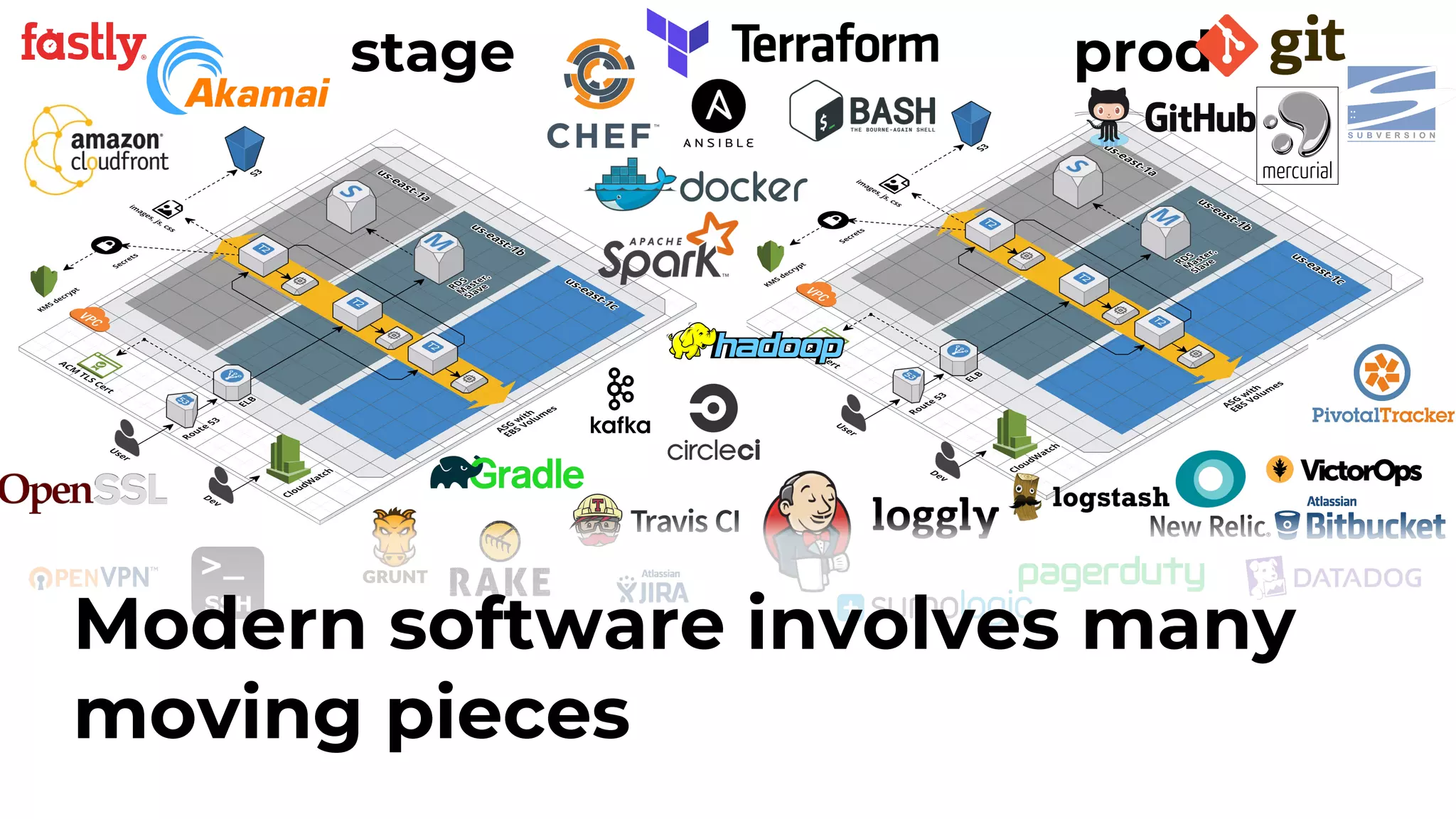










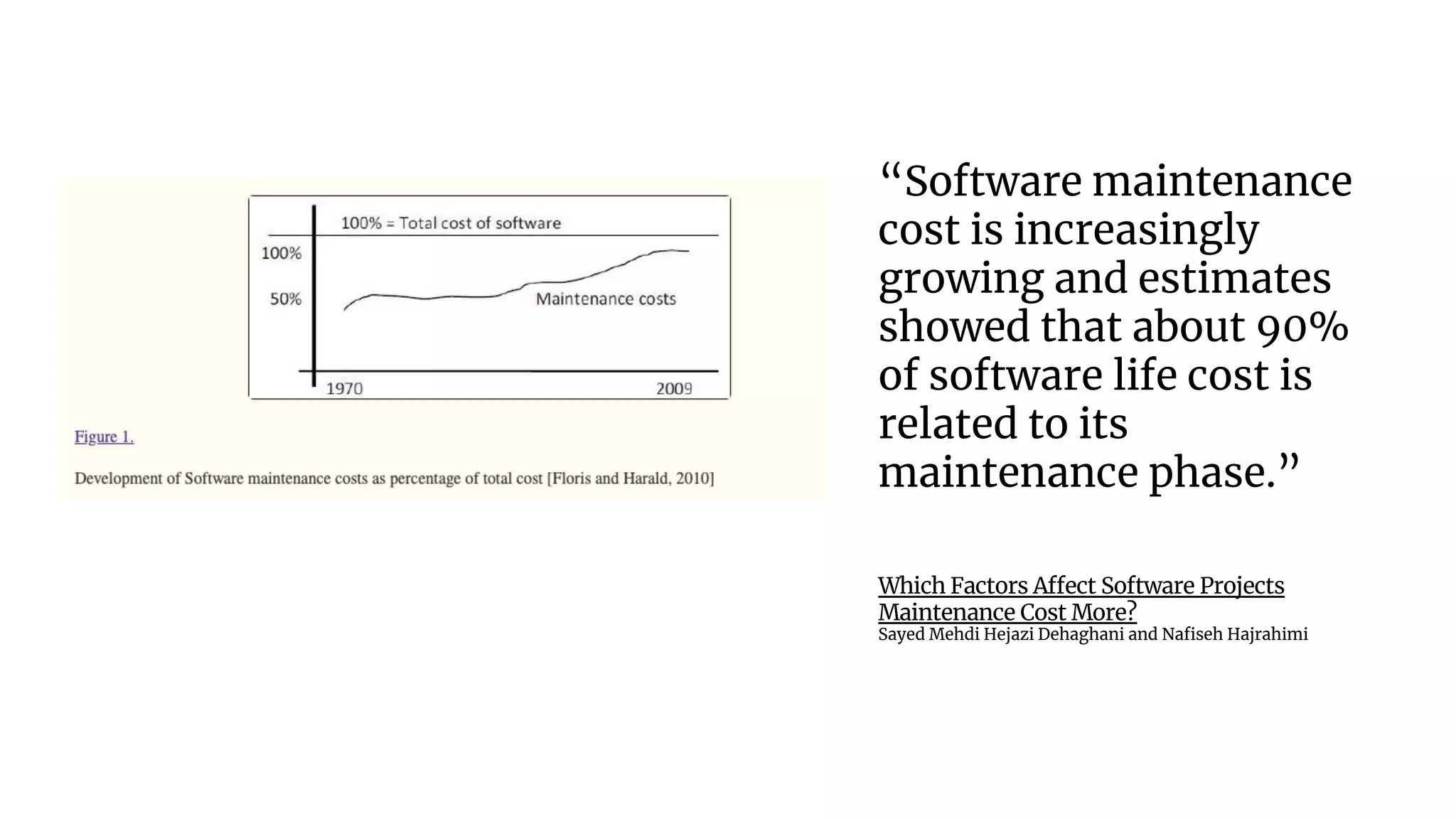













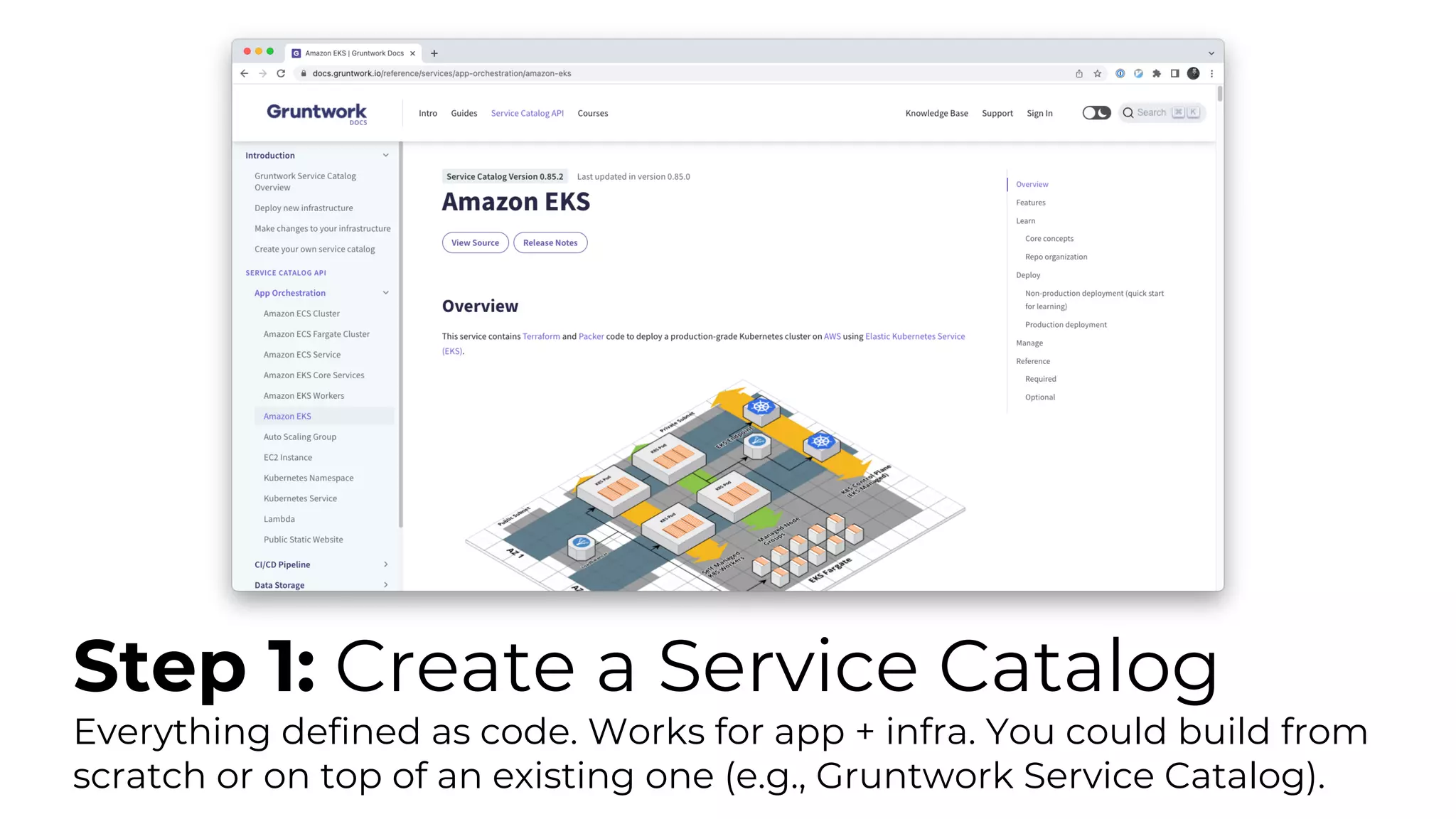

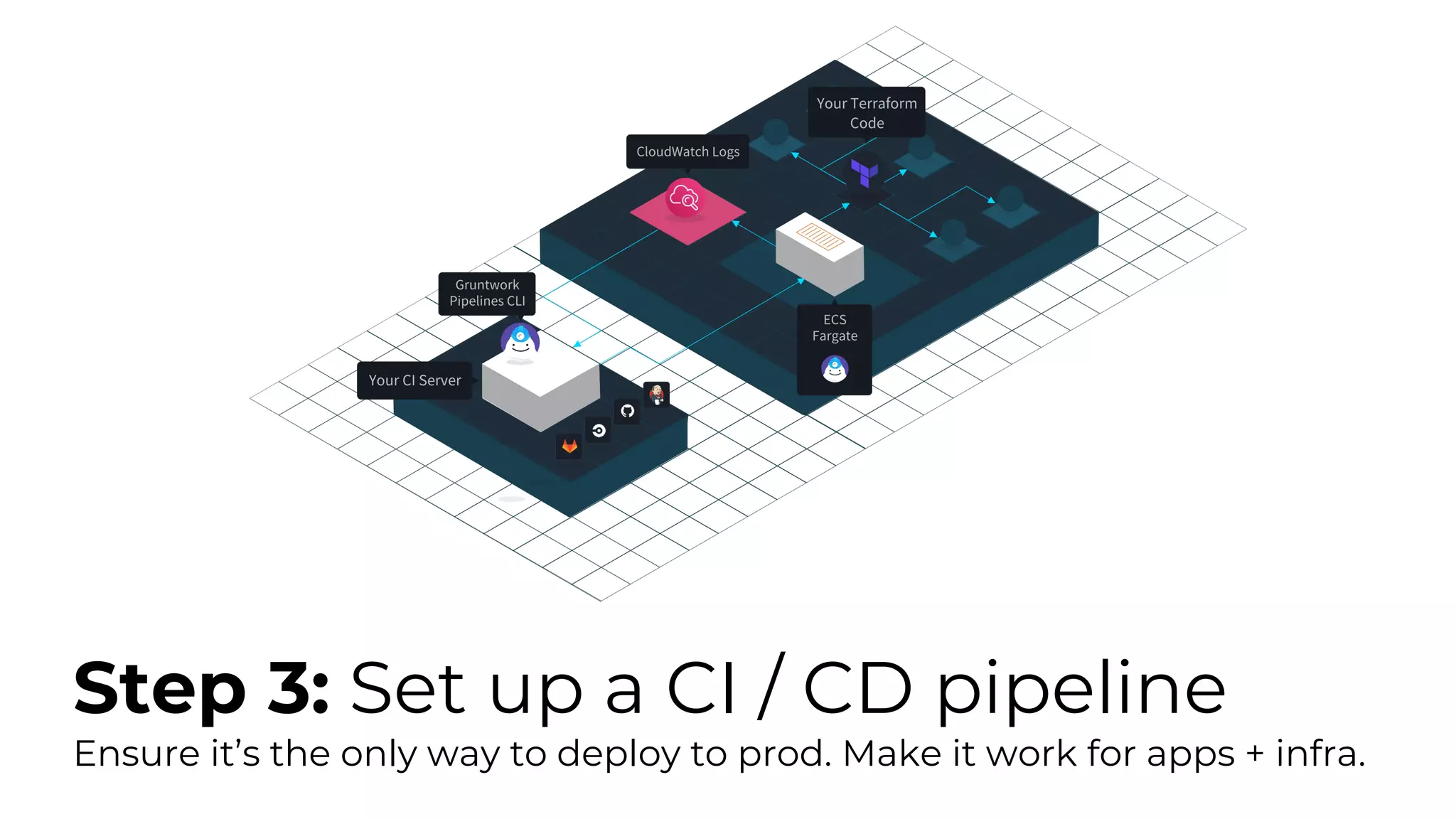
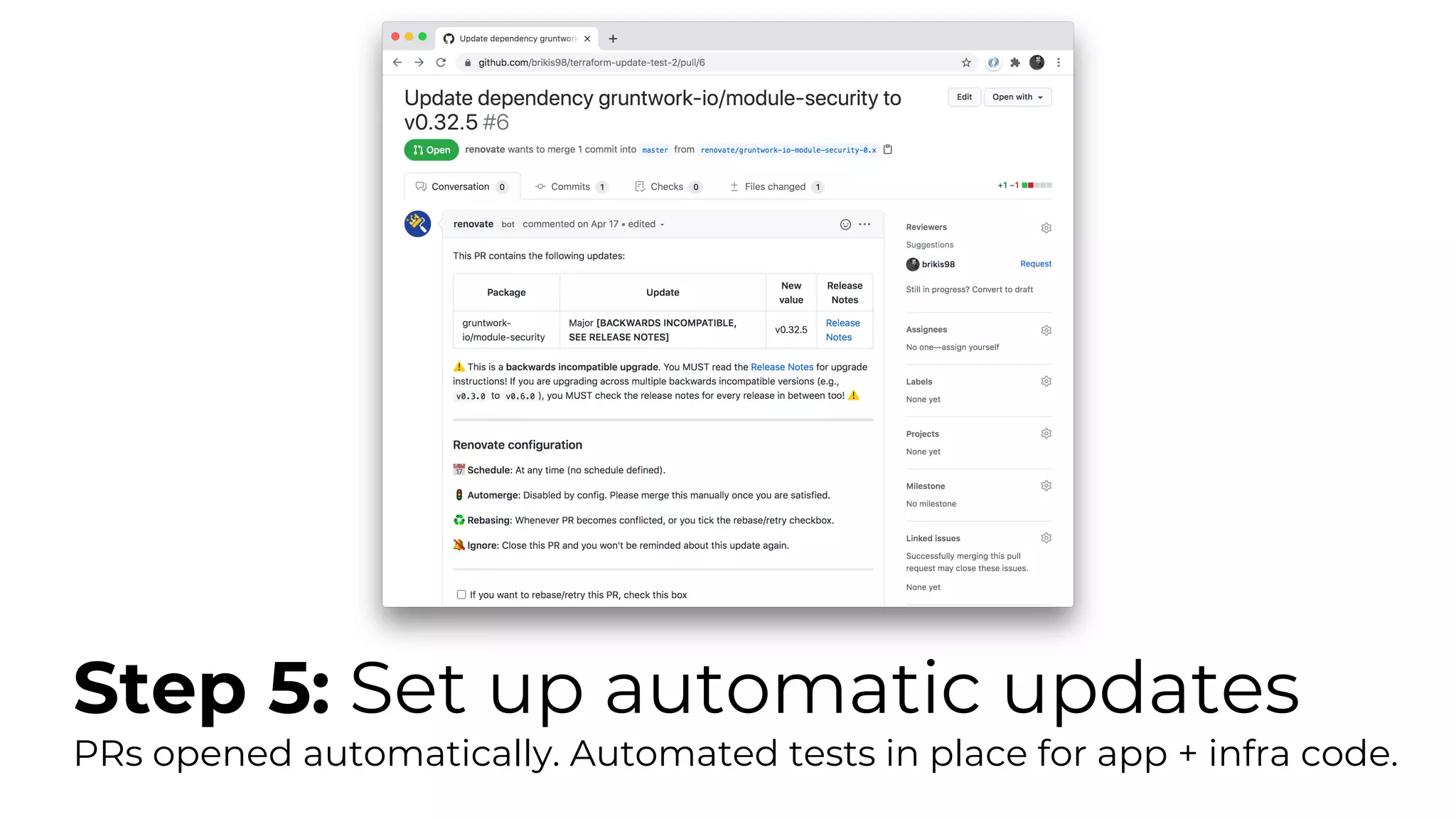



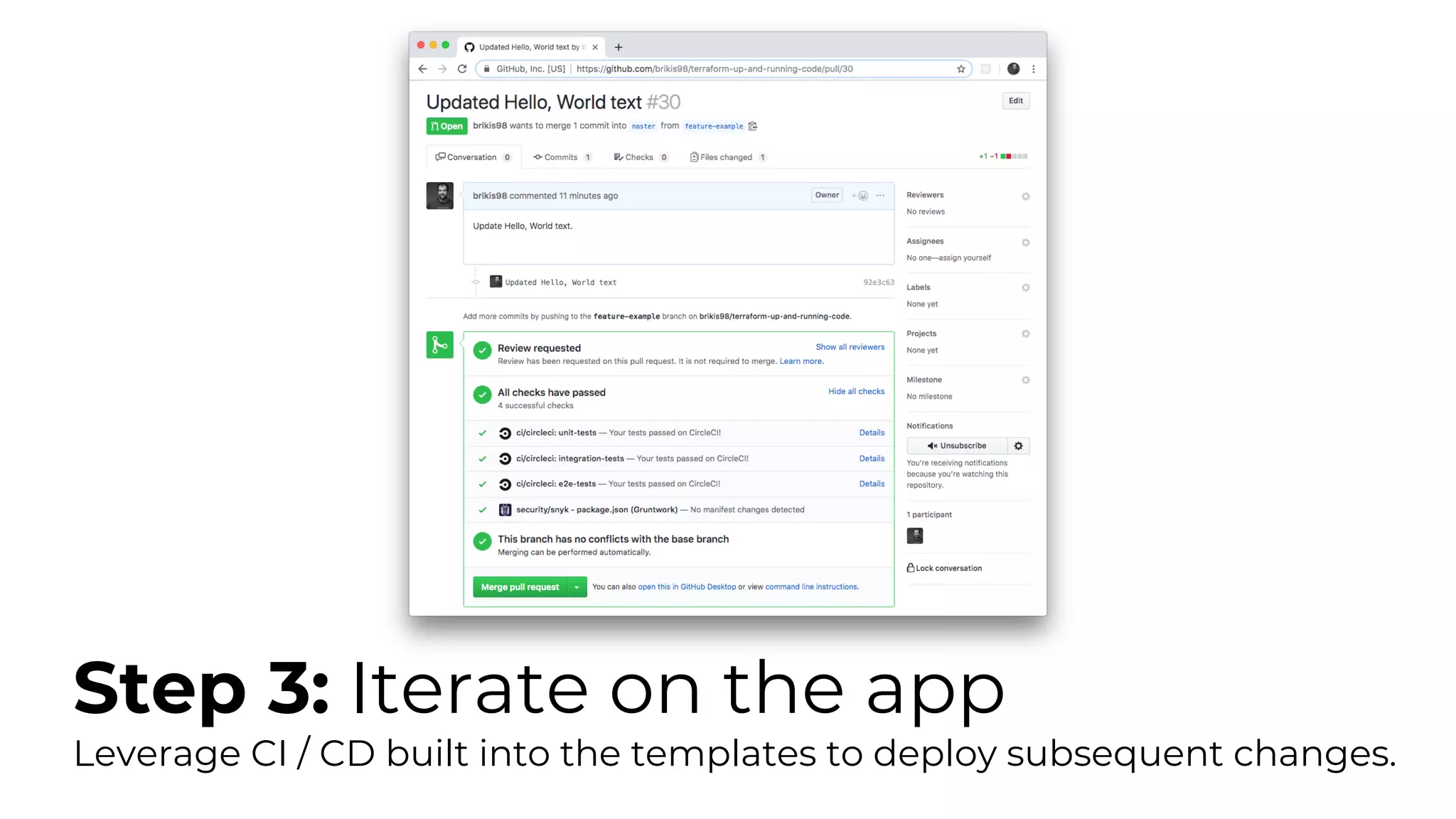

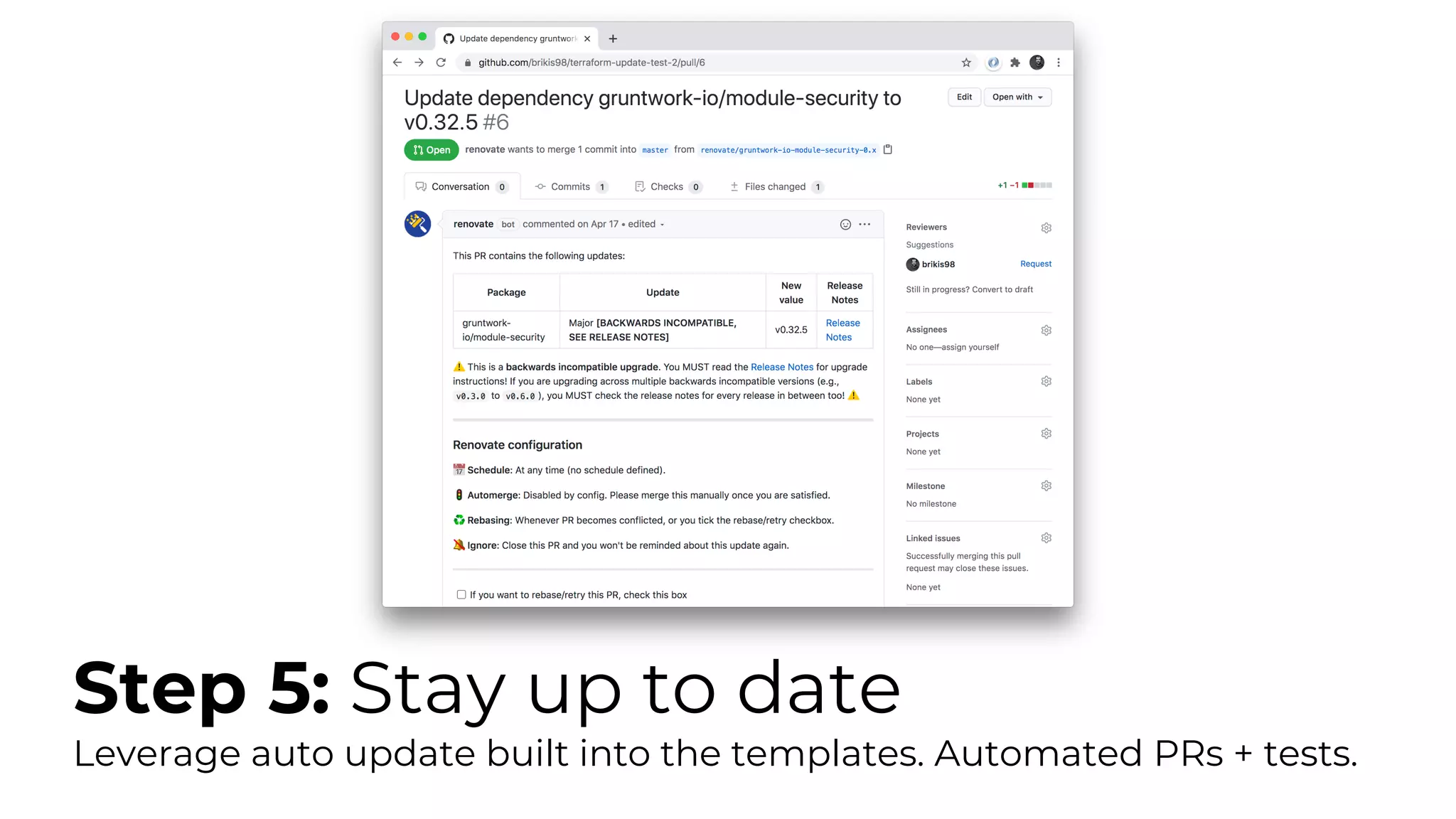



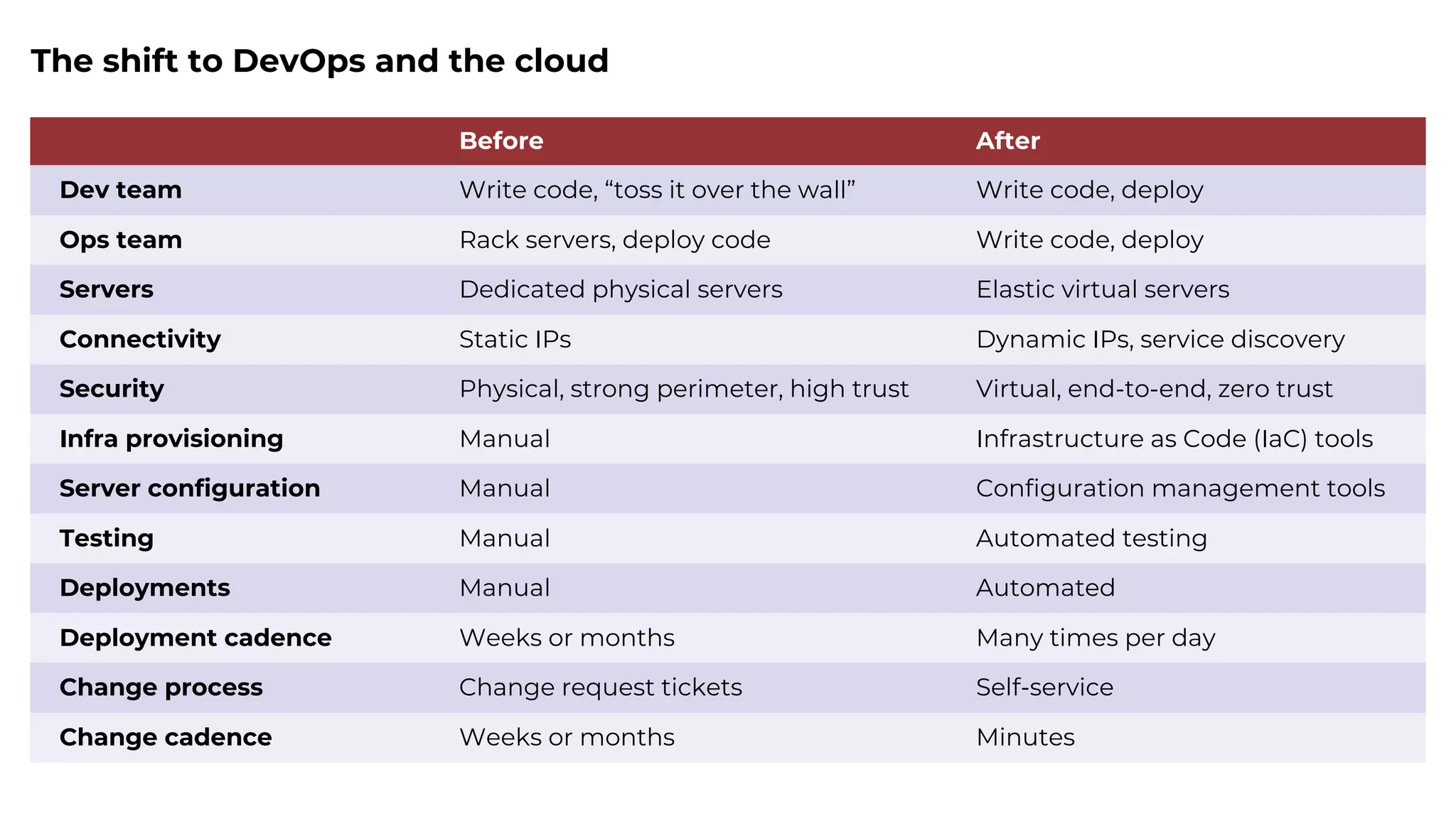
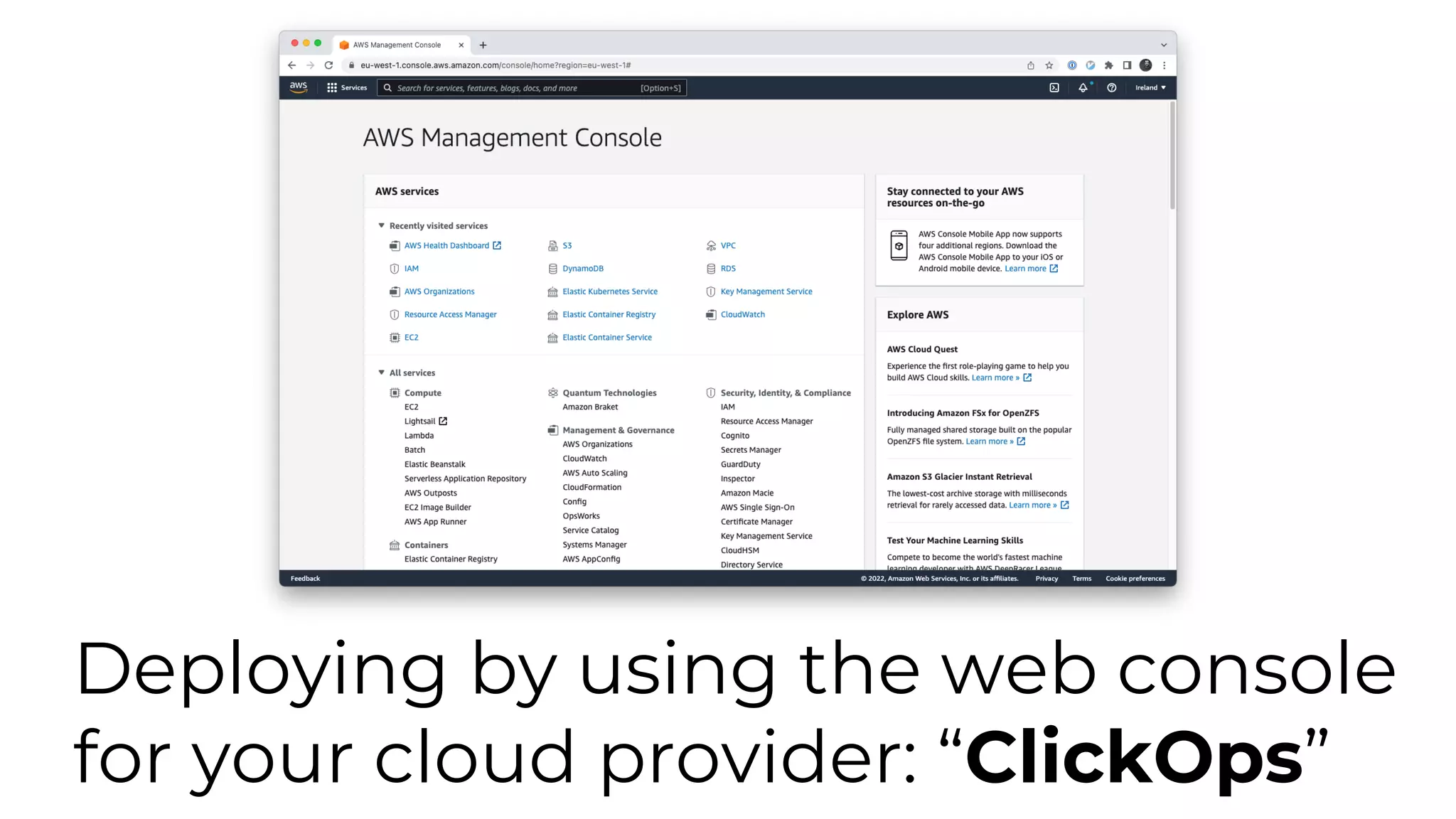
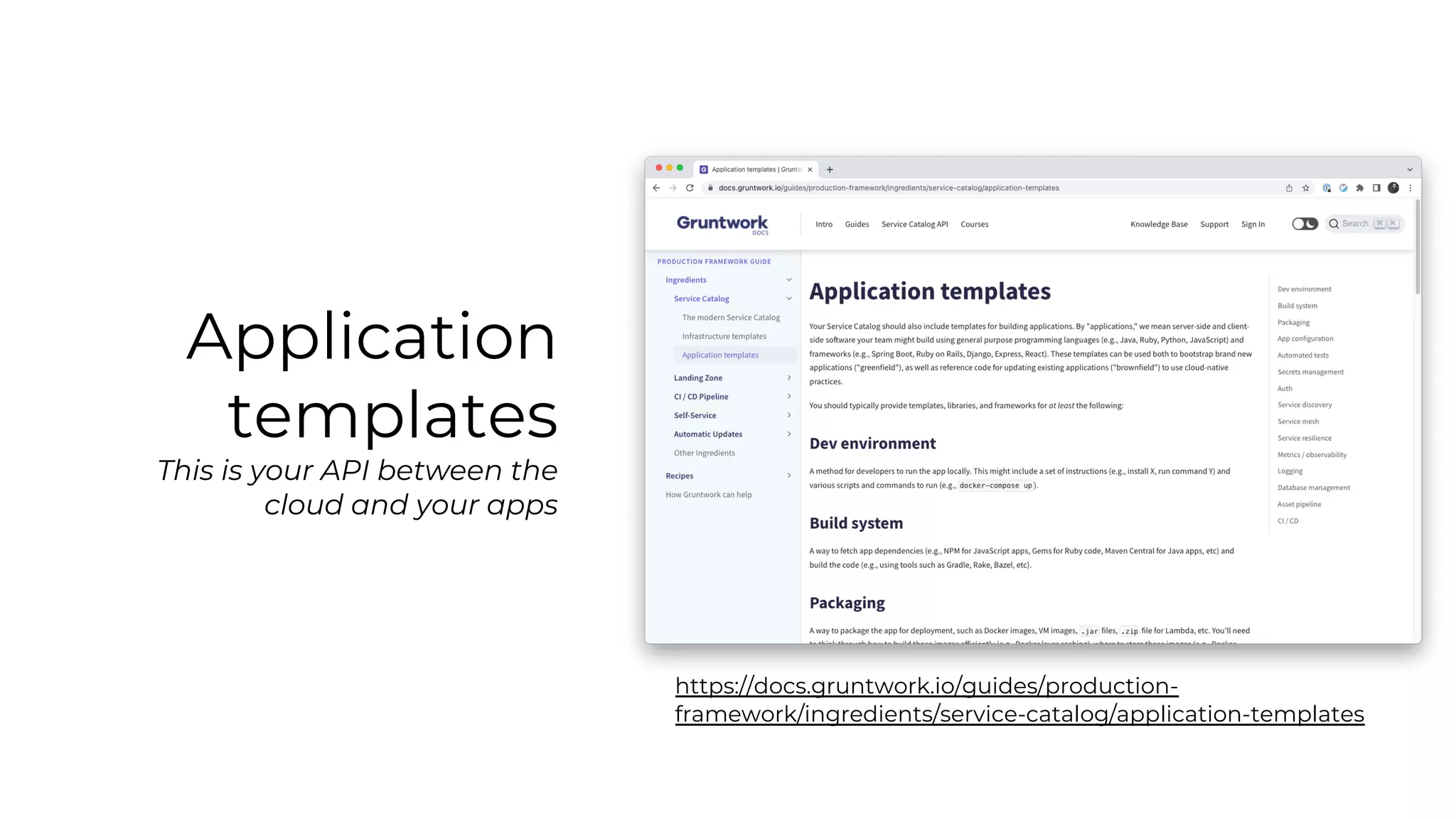
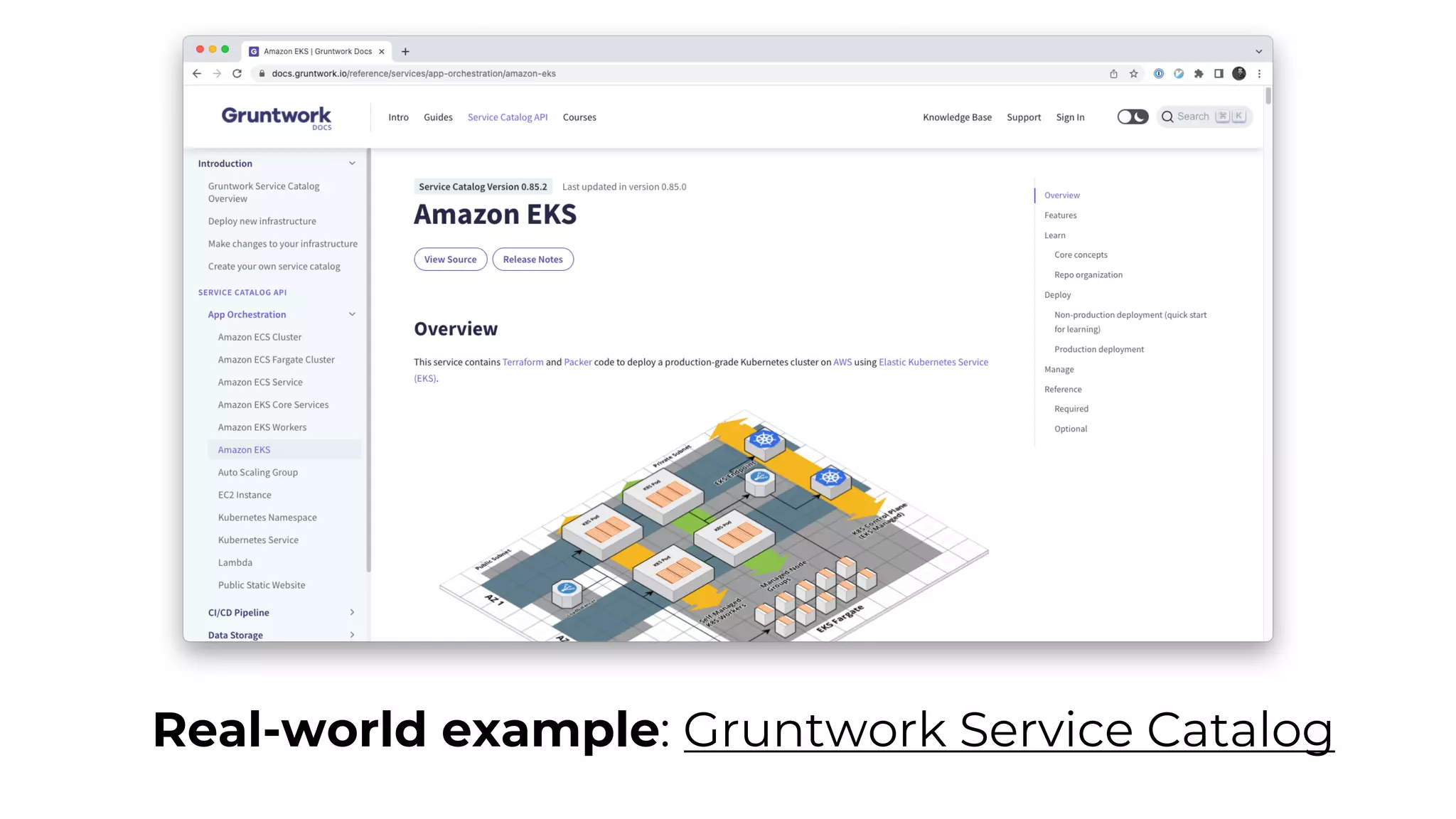
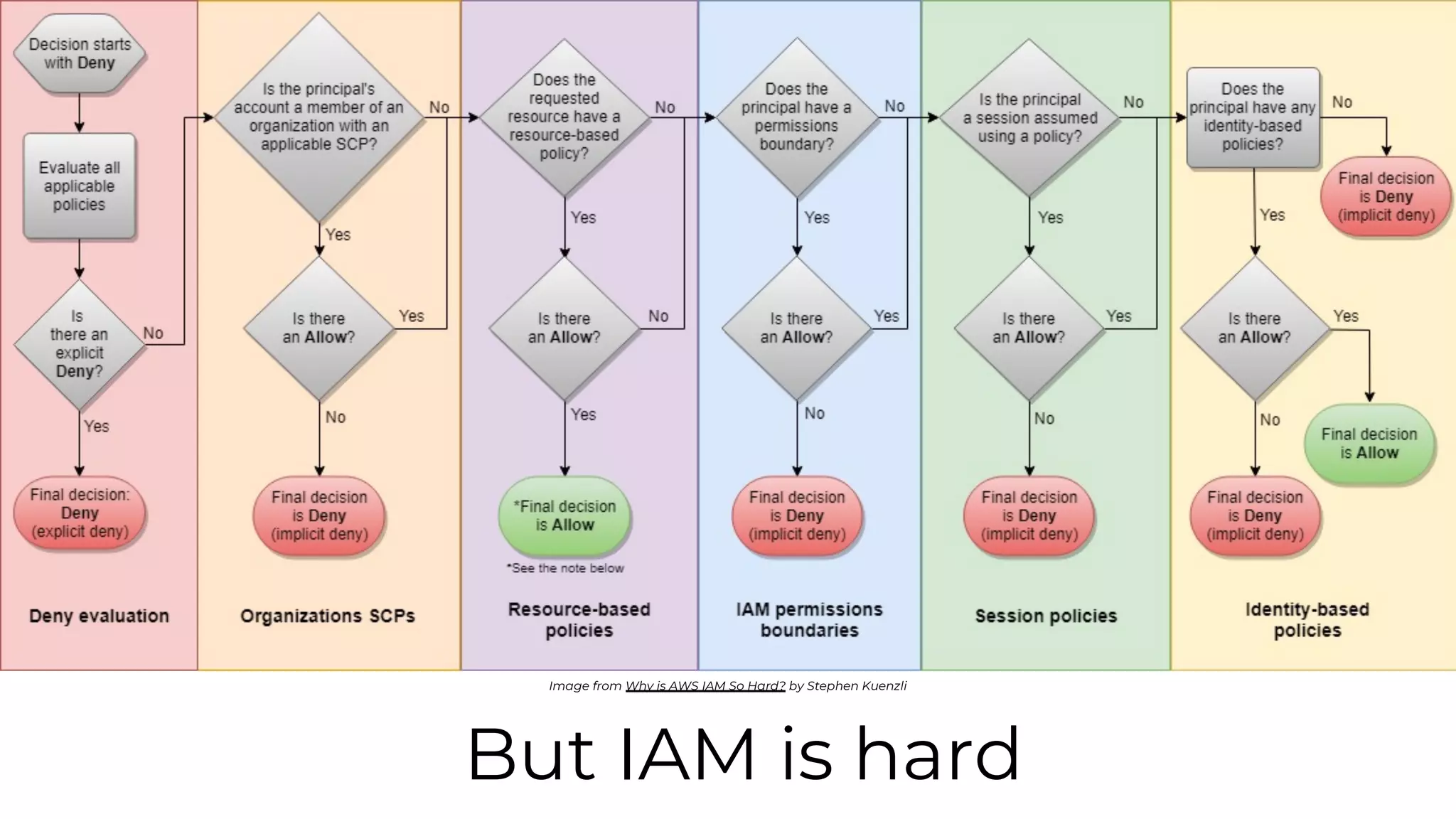
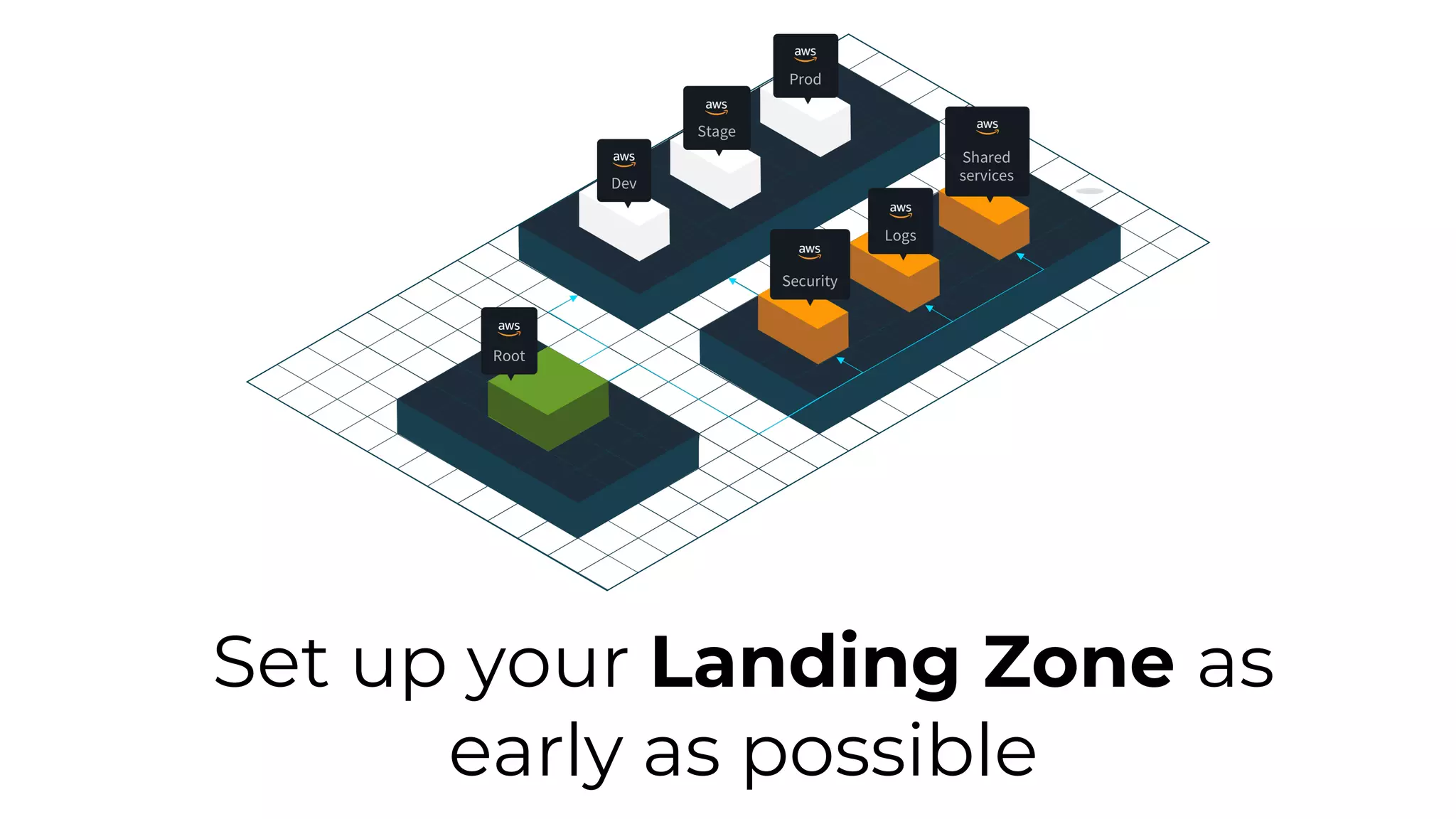
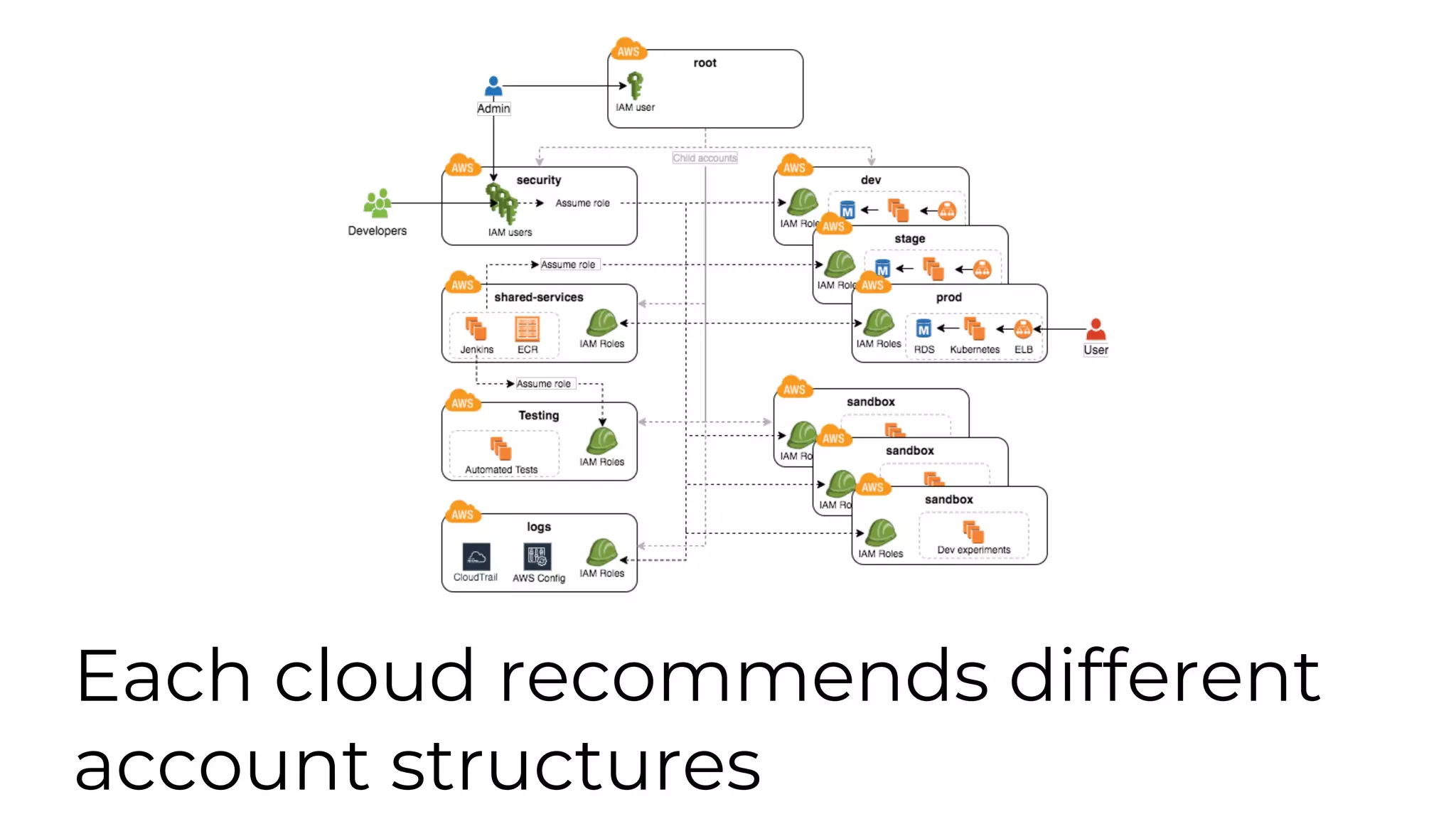
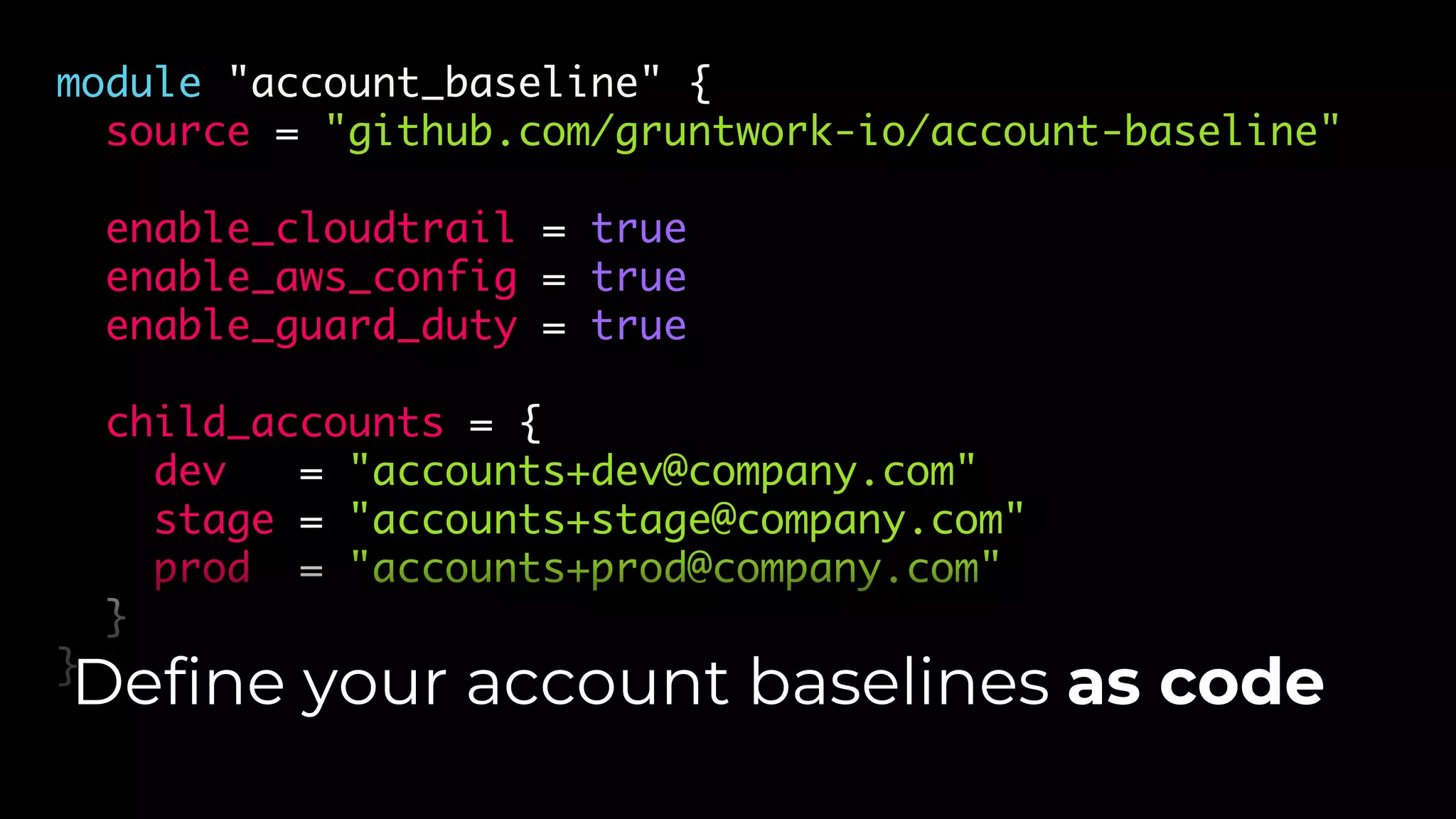
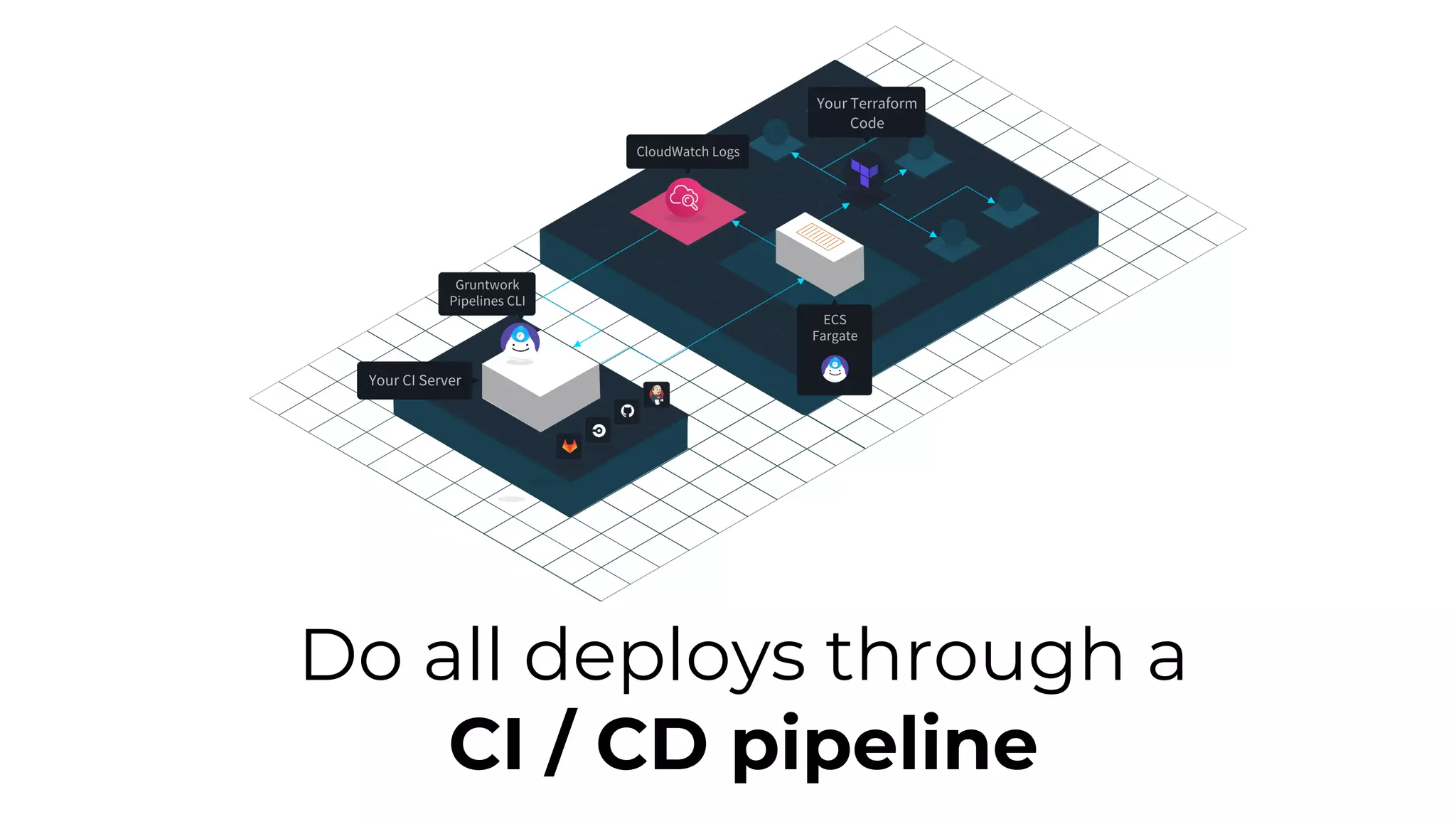
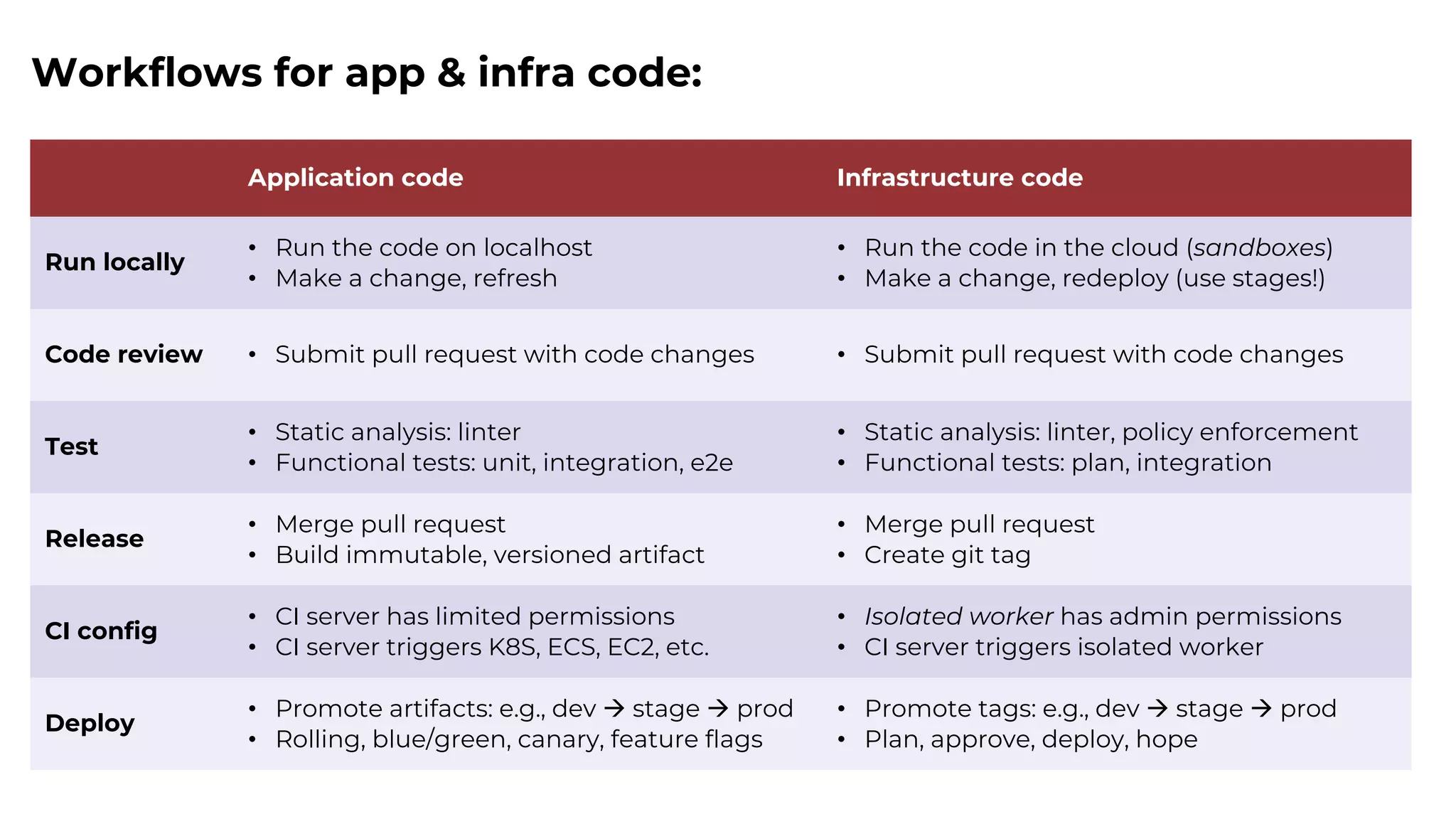
The document discusses common failures in cloud adoption and offers solutions based on the experiences of various companies. Key issues include reliance on manual processes, improper permission management, and bottlenecks created by operations teams. Solutions involve automation through CI/CD pipelines, infrastructure as code, and establishing a self-service model for developers to manage their own deployments.















































![Hackdays and [in]cubator](https://cdn.slidesharecdn.com/ss_thumbnails/hackdaysandincubator-130211223338-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



















