Download as PDF, PPTX







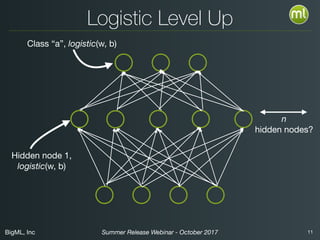
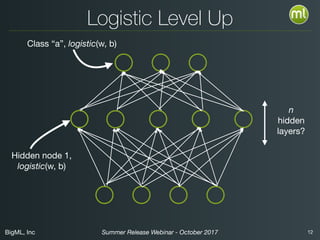
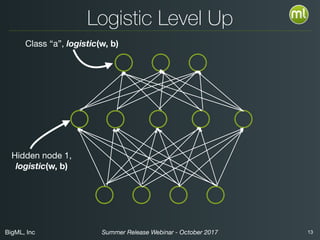

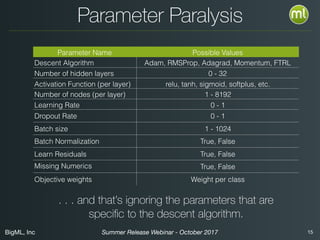



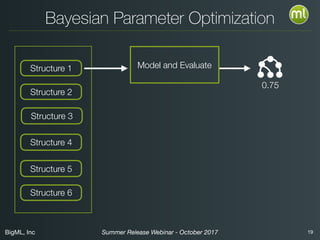
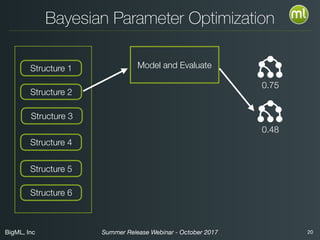
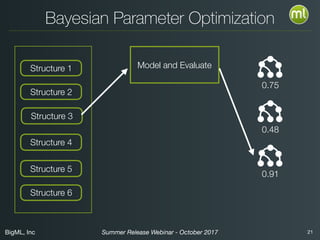
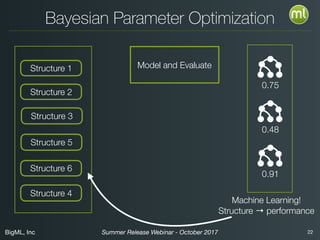





The document discusses BigML's Summer 2017 release, introducing deep neural networks aimed at making advanced machine learning accessible even to novices. It addresses common misconceptions about deep learning, outlines the complexities of parameter settings, and emphasizes the need for solutions such as metalearning and network search to simplify the process. The webinar also highlights benchmarks and warns of situations where deep learning may not be the best choice.


















































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)




