The document provides an overview of adversarial machine learning, focusing on key concepts in machine learning and deep learning, including supervised, unsupervised, and reinforcement learning methods. It delineates various classification techniques, neural network architectures, and the role of deep learning in extracting complex data representations. Additionally, the document addresses limitations like the no-free-lunch theorem and the representational power of neural networks.





























![30
CS 404/504, Fall 2021
Elements of Neural Networks
• A NN with one hidden layer and one output layer
Introduction to Neural Networks
𝒉
𝒚
𝒙
𝒉𝒊𝒅𝒅𝒆𝒏 𝒍𝒂𝒚𝒆𝒓 𝒉 = 𝝈(𝐖𝟏𝒙 + 𝒃𝟏)
𝒐𝒖𝒕𝒑𝒖𝒕 𝒍𝒂𝒚𝒆𝒓 𝒚 = 𝝈(𝑾𝟐𝒉 + 𝒃𝟐)
Weights Biases
Activation functions
4 + 2 = 6 neurons (not counting inputs)
[3 × 4] + [4 × 2] = 20 weights
4 + 2 = 6 biases
26 learnable parameters
Slide credit: Ismini Lourentzou – Introduction to Deep Learning](https://image.slidesharecdn.com/lecture2deeplearningoverview-240504154104-72222301/85/Lecture_2_Deep_Learning_Overview-newone1-30-320.jpg)


![34
CS 404/504, Fall 2021
Elements of Neural Networks
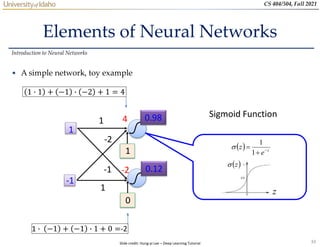
• A simple network, toy example (cont’d)
For an input vector [1 −1]𝑇
, the output is [0.62 0.83]𝑇
Introduction to Neural Networks
1
-2
1
-1
1
0
4
-2
0.98
0.12
2
-1
-1
-2
3
-1
4
-1
0.86
0.11
0.62
0.83
0
0
-2
2
1
-1
𝑓: 𝑅2
→ 𝑅2 𝑓
1
−1
=
0.62
0.83
Slide credit: Hung-yi Lee – Deep Learning Tutorial](https://image.slidesharecdn.com/lecture2deeplearningoverview-240504154104-72222301/85/Lecture_2_Deep_Learning_Overview-newone1-34-320.jpg)





![40
CS 404/504, Fall 2021
Softmax Layer
• The softmax layer applies softmax activations to output
a probability value in the range [0, 1]
The values z inputted to the softmax layer are referred to as
logits
Introduction to Neural Networks
1
z
2
z
3
z
A Softmax Layer
e
e
e
1
z
e
2
z
e
3
z
e
3
1
1
1
j
z
z j
e
e
y
3
1
j
z j
e
3
-3
1 2.7
20
0.05
0.88
0.12
≈0
3
1
2
2
j
z
z j
e
e
y
3
1
3
3
j
z
z j
e
e
y
Probability:
0 < 𝑦𝑖 < 1
𝑖 𝑦𝑖 = 1
Slide credit: Hung-yi Lee – Deep Learning Tutorial](https://image.slidesharecdn.com/lecture2deeplearningoverview-240504154104-72222301/85/Lecture_2_Deep_Learning_Overview-newone1-40-320.jpg)







![48
CS 404/504, Fall 2021
Training NNs
• Data preprocessing - helps convergence during training
Mean subtraction, to obtain zero-centered data
o Subtract the mean for each individual data dimension (feature)
Normalization
o Divide each feature by its standard deviation
– To obtain standard deviation of 1 for each data dimension (feature)
o Or, scale the data within the range [0,1] or [-1, 1]
– E.g., image pixel intensities are divided by 255 to be scaled in the [0,1] range
Training Neural Networks
Picture from: https://cs231n.github.io/neural-networks-2/](https://image.slidesharecdn.com/lecture2deeplearningoverview-240504154104-72222301/85/Lecture_2_Deep_Learning_Overview-newone1-48-320.jpg)



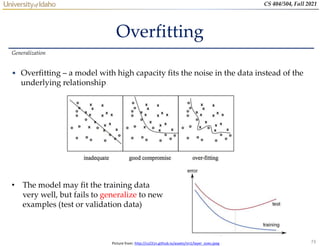
![52
CS 404/504, Fall 2021
Loss Functions
• Classification tasks
Training Neural Networks
Slide credit: Ismini Lourentzou – Introduction to Deep Learning
Training
examples
Output
Layer
Softmax Activations
[maps to a probability distribution]
Loss function Cross-entropy ℒ 𝜃 = −
1
𝑁
𝑖=1
𝑁
𝑘=1
𝐾
𝑦𝑘
(𝑖)
log 𝑦𝑘
(𝑖)
+ 1 − 𝑦𝑘
(𝑖)
log 1 − 𝑦𝑘
𝑖
Pairs of 𝑁 inputs 𝑥𝑖 and ground-truth class labels 𝑦𝑖
Ground-truth class labels 𝑦𝑖 and model predicted class labels 𝑦𝑖](https://image.slidesharecdn.com/lecture2deeplearningoverview-240504154104-72222301/85/Lecture_2_Deep_Learning_Overview-newone1-52-320.jpg)

































































![1_Introduction to Machine Learning [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/1introductiontomachinelearningautosaved-250910004933-3913b711-thumbnail.jpg?width=640&height=640&fit=bounds)


























