AWS Lambda
최선의 관리효율성: 손쉬운 플리케이션의 작성, 배포, 유지 보수,
보안 & 관리
Bring Your Own Code: Node.js, Java, Python, C# 기반의
Stateless, event-driven 어플리케이션 작성, Bring Your Own
Library 지원
인프라 관리에서 해방: Amazon EC2 및 Auto Scaling과 같은
인프라 관리 요소 없음
비용 효율성: 요청 빈도에 따른 자동화된 용량 조정, 실행 시간
(100ms) 단위의 과금
이벤트 기반의 호출: 동기 및 비동기 API Call, AWS
서비스와의 Integration, 3rd 파티 Trigger 지원
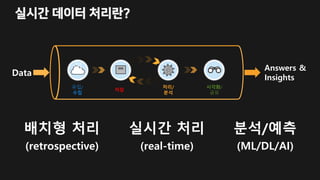
서버리스 실시간 데이터처리란…
데이터 흐름(스트림)
을 받아서
IoT Data
금융
로그
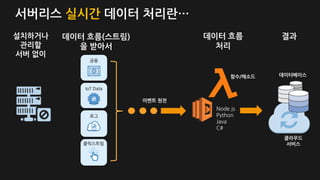
설치하거나
관리할
서버 없이
이벤트 원천
Node.js
Python
Java
C#
데이터 흐름
처리
함수/메소드
클릭스트림
결과
데이터베이스
클라우드
서비스
8.
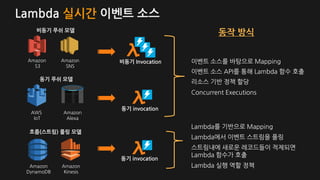
Lambda 실시간 이벤트소스
Amazon
DynamoDB
Amazon
Kinesis
Amazon
S3
Amazon
SNS
비동기 푸쉬 모델
흐름(스트림) 풀링 모델
Amazon
Alexa
AWS
IoT
동기 푸쉬 모델
이벤트 소스를 바탕으로 Mapping
Lambda를 기반으로 Mapping
이벤트 소스 API를 통해 Lambda 함수 호출
스트림내에 새로운 레코드들이 적제되면
Lambda 함수가 호출
리소스 기반 정책 할당
Lambda 실행 역할 정책
Concurrent Executions
동기 invocation
비동기 Invocation
동기 invocation
Lambda에서 이벤트 스트림을 풀링
동작 방식
Amazon Kinesis
Amazon KinesisOffering: 스트림 데이터의 Ingestion 및
처리를 위한 관리형 서비스.
• Amazon Kinesis Streams: 스트림 데이터 처리 및
분석
• Amazon Kinesis Firehose: 스트림 데이터를
Amazon S3 및 Amazon Redshift로 저장
• Amazon Kinesis Analytics: 스트림 데이터에 대한
SQL 쿼리 기반의 분석
실시간: 실시간 데이터 스트림 수집 및 이에 대한 즉각적인 분석
쉬운 관리: 인프라 관리 없이 데이터 스트리밍 어플리케이션
자체에 집중
11.
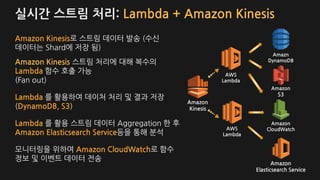
Amazon Kinesis로 스트림데이터 발송 (수신
데이터는 Shard에 저장 됨)
Amazon Kinesis 스트림 처리에 대해 복수의
Lambda 함수 호출 가능
(Fan out)
Lambda 를 활용하여 데이처 처리 및 결과 저장
(DynamoDB, S3)
Lambda 를 활용 스트림 데이터 Aggregation 한 후
Amazon Elasticsearch Service등을 통해 분석
모니터링을 위하여 Amazon CloudWatch로 함수
정보 및 이벤트 데이터 전송
Amazon
Kinesis
AWS
Lambda
Amazon
CloudWatch
Amazn
DynamoDB
Amazon
Elasticsearch Service
Amazon
S3
AWS
Lambda
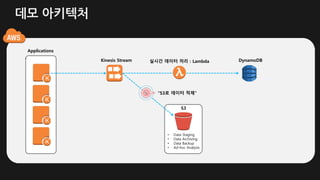
실시간 스트림 처리: Lambda + Amazon Kinesis
12.
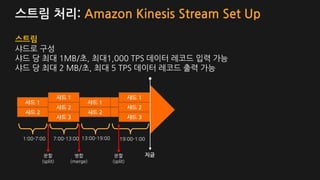
스트림 처리: AmazonKinesis Stream Set Up
스트림
샤드로 구성
샤드 당 최대 1MB/초, 최대1,000 TPS 데이터 레코드 입력 가능
샤드 당 최대 2 MB/초, 최대 5 TPS 데이터 레코드 출력 가능
샤드 2
샤드 1
샤드 2
샤드 1
샤드 3
샤드 2
샤드 1
샤드 2
샤드 1
샤드 3
샤드 2
샤드 1
지금
1:00-7:00 7:00-13:00 13:00-19:00 19:00-1:00
분할
(split)
분할
(split)
병합
(merge)
13.
스트림 처리: AmazonKinesis Stream Set Up
데이터
저장된 데이터는 24시간 (기본값)내 Replay 가능
파티션키의 선택
Managed Buffer: 복수의 샤드의 고른 활용을 위하여 고르게 분배 되는 (랜덤 키 등) 파티
션 키 지정
Streaming MapReduce: 특정 컬럼 (디바이스 ID, 고객 ID 등)을 파티션 키로하여 특정
샤드로 적제 되도록 구성
Best Practice
병렬 처리 성능 향상을 위한 Partition Key의 고려 필요
예상되는 최대 워크로드 기준의 위한 초기 사이즈/샤드 디자인
콘솔에서 제공되는 “Help me decide how many shards I need” 옵션 활용
샤드 수량 판별:
max(incoming_write_bandwidth_in_KB/1000, outgoing_read_bandwidth_in_KB / 2000)
14.
스트림 처리: Lambda함수 생성
메모리
메모리 사이즈에 따라 CPU 파워가 할당됨
높은 CPU 파워 또는 많은 량의 레코드를 처리해야 하는 경우 메모리 증가가 필요
Timeout
최대 5분까지 설정 가능
Permission model
Kinesis Stream에 대한 권한 필요
Retries
Amazon Kinesis의 기본 데이터 저장 기간이 24시간까지 지속적으로 Retry
15.
스트림 처리: Lambda함수 생성
Best Practice
Lambda 함수는 Stateless (함수내에는 Stateful 데이터 저장 금지)
커넥션 재사용을 위해 외부 인터페이스 (예: DB, AWS)는 Handler Faction 외부에 선언
var AWS = require('aws-sdk');
var doc = new AWS.DynamoDB.DocumentClient();
exports.handler = function(event, context) {
console.log('Received event:', JSON.stringify(event, null, 2));
...
...
}
16.
스트림 처리: 이벤트소스 설정
Amazon Kinesis는 Lambda의 이벤트 소스로 지정됨
Batch size
Lambda 함수 한번 호출로 처리할 레코드의 수량
Batch size는 레코드의 크기 및 요구되는 Latency에 따라 다를 수 있음
실제 배치 사이즈 – Calculated as:
MIN(records available, batch size, 6MB)
Starting position
“Trim Horizon” 과거 데이터부터 현재까지의 순서로 샤드를 읽어 들일 경우
“Lastest” 최신 데이터부터 과거의 순서로 샤드를 읽어 들일 경우
“At timestemp” 특정 시점를 기준으로 이후의 데이터를 읽어 들일 경우
17.
스트림 처리: Underthe hood
• 각 샤드별로 진행, 샤드에 데이터가 없는 경우 250ms 후 Polling
• GetRecords call을 호출하여 최대 데이터 (최대 10K, 10MB)를
읽어옴
Polling
• Lambda 함수 호출을 위한 Function Parameter 준비
• Polling 단계에서 호출된 데이터를 호출될 Lambda의 Payload로
Batch의 수량 만큼 분할하여 로딩
Batching
Lambda
Invocation
• RequestResponse 타입으로 동기적으로 호출됨
• Lambda는 Kinesis에 대하여 at least semantics 기반으로 동작
• 각 샤드의 데이터는 샤드별로 우선 순위가 보장됨
Synchronous
18.
스트림 처리: 처리량튜닝
… …
Source
Amazon Kinesis
Destination 1
Lambda
Destination 2
FunctionsShards
샤드 수량에 맞춰 Lambda 스케일 자동 조정샤드에 대한 split/merge를 기반으로 스케일 조정
Waits for responsePolls a batch
최대 이론상 처리량 # shards * 2MB / Lambda function duration (s)
실제 이론상 처리량 # shards * batch size (MB) / Lambda function duration (s)
실제 Put/Ingestion 되는 데이터량이 이론적인 처리량보다 높은 경우 데이터 유실
발생 가능
19.
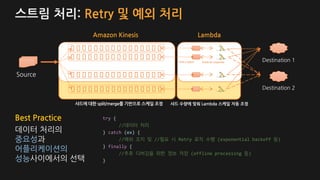
스트림 처리: Retry및 예외 처리
… …
Source
Amazon Kinesis
Destination 1
Lambda
Destination 2
FunctionsShards
샤드 수량에 맞춰 Lambda 스케일 자동 조정샤드에 대한 split/merge를 기반으로 스케일 조정
Waits for responsePolls a batch
Best Practice try {
//데이터 처리
} catch (ex) {
//예외 조치 및 //필요 시 Retry 로직 수행 (exponential backoff 등)
} finally {
//추후 디버깅을 위한 정보 저장 (offline processing 등)
}
데이터 처리의
중요성과
어플리케이션의
성능사이에서의 선택
스트림 처리: 경험몇 가지…
실제 처리되는 배치의 크기는 부하가 낮을때는 설정 보다 낮아졌습니다.
실제 처리되는 배치의 크기는 부하가 높을때는 설정 보다 높아졌습니다.
너무 많은 Consumer는 단일 샤드의 Read limit에 도달할 가능성이 높아지기 때문에,
ReadProvisionedThroughputExceeded 에러 및 메트릭에 대한 모니터링이
필요합니다.
“모든 어플리케이션이
Kinesis Stream 수준의 스트림 처리 및 분석
요구사항을 갖고 있을까요?”
스트림 처리: 경험몇 가지…
• GetRecords: 실제 처리량
• PutRecord : bytes, latency, records 등
• GetRecords.IteratorAgeMilliseconds: 현재 시간과 마지막
GetRecords와의 시간 차이
Amazon Kinesis Streams 모니터링
Lambda 함수 모니터링
• Invocations: 함수 호출 횟수
• Duration: 실행 및 처리 시간
• Error count: 에러 수량
• Throttle: Throttle이 발생한 수량 (Lambda concurrent execution
limit)
• Iterator Age: 처리된 배치의 마지막 레코드 (스트림에 저장된 시간
기준)
서버리스 분산 컴퓨팅:맵 리듀스 Model
왜? 서버리스 기반의 분산 컴퓨팅인가?
인프라 관리의 어려움에서 해방
- 클러스터 관리, 복잡한 구성 도구 불필요
심플하고 유연하며 사용자 친화적인 데이터 프로세싱
환경 제공
- State 관리 복잡성 완화
- 서버의 Utilization 및 Multi-Threading으로 인한 프로
그램 복잡성으로 부터 해방
- Ad-hoc 형태의 맵리듀스 작업에 대한 비용 절감
28.
서버리스 분산 컴퓨팅:맵 리듀스 Model
https://github.com/awslabs/lambda-refarch-mapreduce
29.
서버리스 분산 컴퓨팅:맵 리듀스 Model
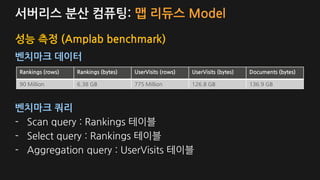
성능 측정 (Amplab benchmark)
벤치마크 데이터
벤치마크 쿼리
- Scan query : Rankings 테이블
- Select query : Rankings 테이블
- Aggregation query : UserVisits 테이블
Rankings (rows) Rankings (bytes) UserVisits (rows) UserVisits (bytes) Documents (bytes)
90 Million 6.38 GB 775 Million 126.8 GB 136.9 GB
30.
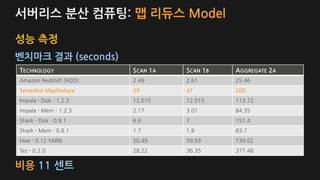
성능 측정
벤치마크 결과(seconds)
TECHNOLOGY SCAN 1A SCAN 1B AGGREGATE 2A
Amazon Redshift (HDD) 2.49 2.61 25.46
Serverless MapReduce 39 47 200
Impala - Disk - 1.2.3 12.015 12.015 113.72
Impala - Mem - 1.2.3 2.17 3.01 84.35
Shark - Disk - 0.8.1 6.6 7 151.4
Shark - Mem - 0.8.1 1.7 1.8 83.7
Hive - 0.12 YARN 50.49 59.93 730.62
Tez - 0.2.0 28.22 36.35 377.48
서버리스 분산 컴퓨팅: 맵 리듀스 Model
비용 11 센트
31.
서버리스 분산 컴퓨팅:Fannie Mae 사례
목적
노후화 (7년) 된 HPC Grid의 성능 개선을 목적으로 고려
경과
2016년 Lambda를 활용한 첫 HPC 컴퓨티 플랫폼 작성
금융 모델링 어플리케이션 개발의 경우 한달이내 이를 위한 컴퓨팅 리소스를 수
분내에 프로비저닝
2017년 15,000 병렬 수행이 가능한 최초의 금융 모델링 어플리케이션 배포
32.
서버리스 분산 컴퓨팅:Fannie Mae 사례
Lambda 구성
2,000 concurren로 시작하여 1분 단위로 100개씩 추가 호출
부하에 따라 2,000dptj 15,000까지 자동 증가
어플리케이션 결과
20M (2천만) 모기지에 대한 시뮬레이션에 약 2시간 소요 (기존 대비 3배 향상)
33.
서버리스 분산 컴퓨팅:PyWren
UC, Berkeley에서 첫 프로토타입 개발
http://pywren.io/
파이션 및 Stateless Lambda 함수를 기반으로 대량 데이터에 대한 분석에 활용
S3 저장소에 대하여 코어당 30~40MB/s 수준의 읽기 및 쓰기 성능 달성
2800개의 동시 실행을 통해 60~80GB/s 수준의 성능 확장 가능
34.
요약
• 실시간 서버리스데이터 처리를 위한 Lambda와
Kinesis에 대한 이해 및 Internal 동작 원리
• 서버 리스 분산 컴퓨팅 및 고객 사례














































![[115]쿠팡 서비스 클라우드 마이그레이션 통해 배운것들](https://cdn.slidesharecdn.com/ss_thumbnails/115coupang-181011031522-thumbnail.jpg?width=640&height=640&fit=bounds)







![[2018] 고객 사례를 통해 본 클라우드 전환 전략](https://cdn.slidesharecdn.com/ss_thumbnails/cloudinfra06-190131073402-thumbnail.jpg?width=640&height=640&fit=bounds)














![[AWS Dev Day] 앱 현대화 | 실시간 데이터 처리를 위한 현대적 애플리케이션 개발 방법 - 김영진 AWS 솔루션즈 아키텍트, 이세...](https://cdn.slidesharecdn.com/ss_thumbnails/realtime-190930044254-thumbnail.jpg?width=640&height=640&fit=bounds)





![[D3T1S01] Gen AI를 위한 Amazon Aurora 활용 사례 방법](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s01genaiamazonaurora-240702042912-516e67f4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S06] Neptune Analytics with Vector Similarity Search](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s06neptuneanalyticsvectorsilimliaritysearch-240702042912-94c41309-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S03] Amazon DynamoDB design puzzlers](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s03amazondynamodbdesignpuzzlers-240702042912-ad6df881-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S04] Aurora PostgreSQL performance monitoring and troubleshooting by use...](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s04aurorapostgresqlperformancemonitoringandtroubleshooting-240702042912-5df626e3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S07] AWS S3 - 클라우드 환경에서 데이터베이스 보호하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s07-240702042911-cb134cd6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S05] Aurora 혼합 구성 아키텍처를 사용하여 예상치 못한 트래픽 급증 대응하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s05aurora-240702042911-c7f3f22d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S02] Aurora Limitless Database Introduction](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s02auroralimitlessdatabaseintroduction-240702042911-cb5552b7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T2S01] Amazon Aurora MySQL 메이저 버전 업그레이드 및 Amazon B/G Deployments 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s01amazonaurorabluegreendeployment-240702042226-3ae36566-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T2S03] Data&AI Roadshow 2024 - Amazon DocumentDB 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s03documentdbhandson-240702042224-047bbc2c-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Keynote] 슬기로운 AWS 데이터베이스 선택하기 - 발표자: 강민석, Korea Database SA Manager, WWSO, A...](https://cdn.slidesharecdn.com/ss_thumbnails/d3s01aws-230704014400-3eeae447-thumbnail.jpg?width=640&height=640&fit=bounds)



