Download as PDF, PPTX

















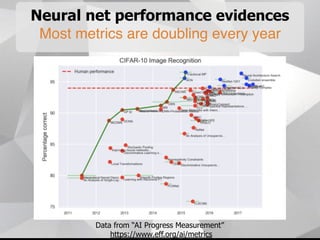
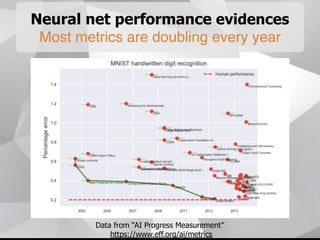
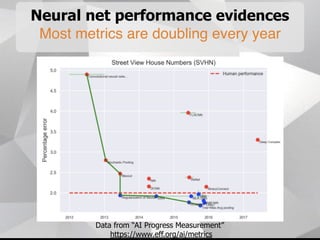
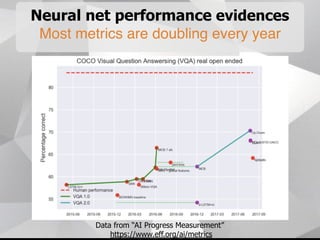
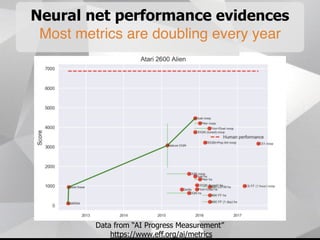
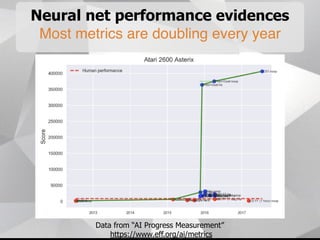
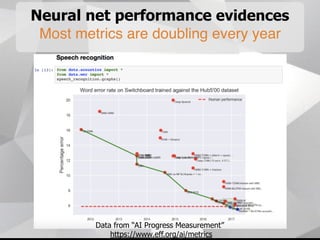
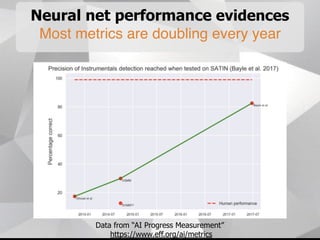
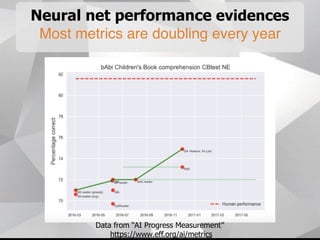







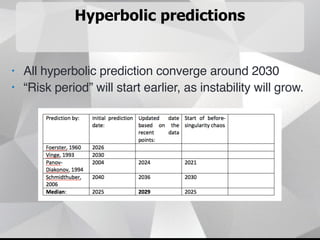







Near-term AI safety expert Alexey Turchin discusses the possibility of human extinction caused by AI within the next 10 years. He presents several pieces of evidence that AI capabilities are growing exponentially and may reach human levels by the early-to-mid 2020s. This includes neural network performance doubling every year, hardware capacity increasing exponentially, and the size of datasets needed for human-level performance being achievable in the next 5 years. He argues that while superintelligence may not be necessary for an extinction event, narrow AI applications could enable catastrophic outcomes before AGI if misused by bad actors.


















































































![ANIMAL_CELL_,_TISSUE_AND_ORGAN_CULTURE[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/animalcelltissueandorganculture1-260204172026-4462b440-thumbnail.jpg?width=640&height=640&fit=bounds)




